 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign3D-AD: Cross-Modal Feature Alignment and Dual-Prompt Learning for Zero-shot 3D Anomaly Detection
May 07, 2026Zero-shot 3D anomaly detection aims to identify anomalies without access to training data from target categories. However, existing methods mainly rely on projecting 3D observations into multi-view representations that primarily capture geometric cues rather than realistic visual semantics and process them with vision encoders pretrained on RGB data, leading to a significant domain gap between the encoder and the projected representations. To address this issue, we propose Align3D-AD, a unified two-stage framework that leverages the RGB modality from auxiliary categories as cross-modal guidance for zero-shot 3D anomaly detection. First, we introduce a cross-modal feature alignment paradigm that maps rendering features into the RGB semantic space. Unlike prior works that implicitly rely on pretrained encoders, our method enables direct semantic transfer from RGB observations. A semantic consistency reweighting strategy is further introduced to refine feature alignment by reweighting local regions according to holistic semantic consistency. Second, we propose a modality-aware prompt learning framework with dual-prompt contrastive alignment. By assigning independent prompts to RGB-aligned and rendering features, our method captures complementary semantics across modalities, while the contrastive alignment further enhances prompt representations to improve discriminability. Extensive experiments on MVTec3D-AD, Eyecandies, and Real3D-AD demonstrate that Align3D-AD consistently outperforms existing zero-shot methods under both one-vs-rest and cross-dataset settings, highlighting its generalization capability and robustness. Code and the dataset will be made available once our paper is accepted.
SGANet: Semantic and Geometric Alignment for Multimodal Multi-view Anomaly Detection
Apr 07, 2026Multi-view anomaly detection aims to identify surface defects on complex objects using observations captured from multiple viewpoints. However, existing unsupervised methods often suffer from feature inconsistency arising from viewpoint variations and modality discrepancies. To address these challenges, we propose a Semantic and Geometric Alignment Network (SGANet), a unified framework for multimodal multi-view anomaly detection that effectively combines semantic and geometric alignment to learn physically coherent feature representations across viewpoints and modalities. SGANet consists of three key components. The Selective Cross-view Feature Refinement Module (SCFRM) selectively aggregates informative patch features from adjacent views to enhance cross-view feature interaction. The Semantic-Structural Patch Alignment (SSPA) enforces semantic alignment across modalities while maintaining structural consistency under viewpoint transformations. The Multi-View Geometric Alignment (MVGA) further aligns geometrically corresponding patches across viewpoints. By jointly modeling feature interaction, semantic and structural consistency, and global geometric correspondence, SGANet effectively enhances anomaly detection performance in multimodal multi-view settings. Extensive experiments on the SiM3D and Eyecandies datasets demonstrate that SGANet achieves state-of-the-art performance in both anomaly detection and localization, validating its effectiveness in realistic industrial scenarios.
Rainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
May 06, 2025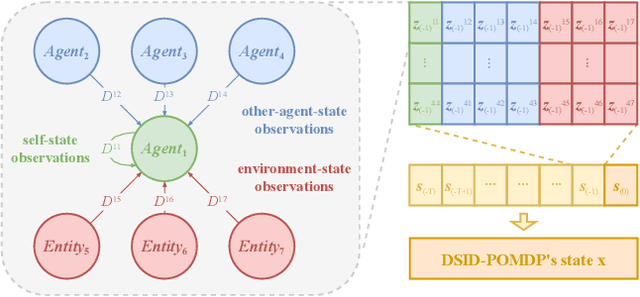

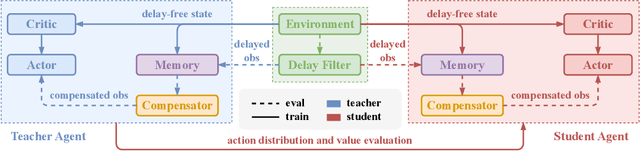
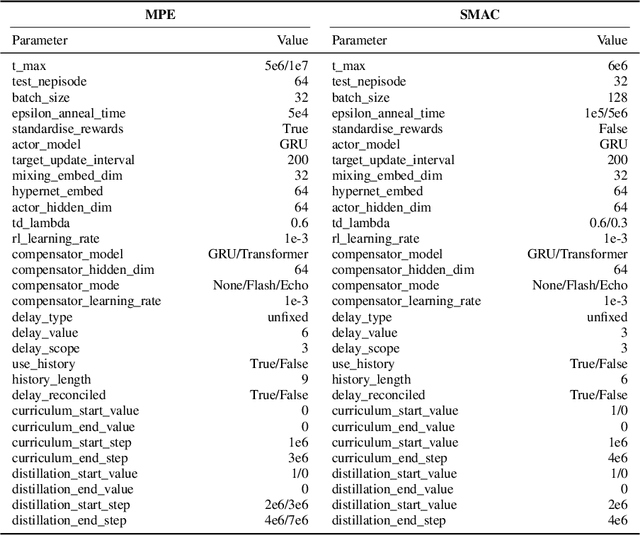
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalization capability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework.