 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFF-PNet: A Pyramid Network Based on Feature and Field for Brain Image Registration
May 08, 2025In recent years, deformable medical image registration techniques have made significant progress. However, existing models still lack efficiency in parallel extraction of coarse and fine-grained features. To address this, we construct a new pyramid registration network based on feature and deformation field (FF-PNet). For coarse-grained feature extraction, we design a Residual Feature Fusion Module (RFFM), for fine-grained image deformation, we propose a Residual Deformation Field Fusion Module (RDFFM). Through the parallel operation of these two modules, the model can effectively handle complex image deformations. It is worth emphasizing that the encoding stage of FF-PNet only employs traditional convolutional neural networks without any attention mechanisms or multilayer perceptrons, yet it still achieves remarkable improvements in registration accuracy, fully demonstrating the superior feature decoding capabilities of RFFM and RDFFM. We conducted extensive experiments on the LPBA and OASIS datasets. The results show our network consistently outperforms popular methods in metrics like the Dice Similarity Coefficient.
Tetrahedron-Net for Medical Image Registration
May 07, 2025Medical image registration plays a vital role in medical image processing. Extracting expressive representations for medical images is crucial for improving the registration quality. One common practice for this end is constructing a convolutional backbone to enable interactions with skip connections among feature extraction layers. The de facto structure, U-Net-like networks, has attempted to design skip connections such as nested or full-scale ones to connect one single encoder and one single decoder to improve its representation capacity. Despite being effective, it still does not fully explore interactions with a single encoder and decoder architectures. In this paper, we embrace this observation and introduce a simple yet effective alternative strategy to enhance the representations for registrations by appending one additional decoder. The new decoder is designed to interact with both the original encoder and decoder. In this way, it not only reuses feature presentation from corresponding layers in the encoder but also interacts with the original decoder to corporately give more accurate registration results. The new architecture is concise yet generalized, with only one encoder and two decoders forming a ``Tetrahedron'' structure, thereby dubbed Tetrahedron-Net. Three instantiations of Tetrahedron-Net are further constructed regarding the different structures of the appended decoder. Our extensive experiments prove that superior performance can be obtained on several representative benchmarks of medical image registration. Finally, such a ``Tetrahedron'' design can also be easily integrated into popular U-Net-like architectures including VoxelMorph, ViT-V-Net, and TransMorph, leading to consistent performance gains.
Online Robot Motion Planning Methodology Guided by Group Social Proxemics Feature
Feb 07, 2025Nowadays robot is supposed to demonstrate human-like perception, reasoning and behavior pattern in social or service application. However, most of the existing motion planning methods are incompatible with above requirement. A potential reason is that the existing navigation algorithms usually intend to treat people as another kind of obstacle, and hardly take the social principle or awareness into consideration. In this paper, we attempt to model the proxemics of group and blend it into the scenario perception and navigation of robot. For this purpose, a group clustering method considering both social relevance and spatial confidence is introduced. It can enable robot to identify individuals and divide them into groups. Next, we propose defining the individual proxemics within magnetic dipole model, and further established the group proxemics and scenario map through vector-field superposition. On the basis of the group clustering and proxemics modeling, we present the method to obtain the optimal observation positions (OOPs) of group. Once the OOPs grid and scenario map are established, a heuristic path is employed to generate path that guide robot cruising among the groups for interactive purpose. A series of experiments are conducted to validate the proposed methodology on the practical robot, the results have demonstrated that our methodology has achieved promising performance on group recognition accuracy and path-generation efficiency. This concludes that the group awareness evolved as an important module to make robot socially behave in the practical scenario.
Sewer Image Super-Resolution with Depth Priors and Its Lightweight Network
Jul 27, 2024



The Quick-view (QV) technique serves as a primary method for detecting defects within sewerage systems. However, the effectiveness of QV is impeded by the limited visual range of its hardware, resulting in suboptimal image quality for distant portions of the sewer network. Image super-resolution is an effective way to improve image quality and has been applied in a variety of scenes. However, research on super-resolution for sewer images remains considerably unexplored. In response, this study leverages the inherent depth relationships present within QV images and introduces a novel Depth-guided, Reference-based Super-Resolution framework denoted as DSRNet. It comprises two core components: a depth extraction module and a depth information matching module (DMM). DSRNet utilizes the adjacent frames of the low-resolution image as reference images and helps them recover texture information based on the correlation. By combining these modules, the integration of depth priors significantly enhances both visual quality and performance benchmarks. Besides, in pursuit of computational efficiency and compactness, our paper introduces a super-resolution knowledge distillation model based on an attention mechanism. This mechanism facilitates the acquisition of feature similarity between a more complex teacher model and a streamlined student model, the latter being a lightweight version of DSRNet. Experimental results demonstrate that DSRNet significantly improves PSNR and SSIM compared with other methods. This study also conducts experiments on sewer defect semantic segmentation, object detection, and classification on the Pipe dataset and Sewer-ML dataset. Experiments show that the method can improve the performance of low-resolution sewer images in these tasks.
Dynamic Backtracking in GFlowNets: Enhancing Decision Steps with Reward-Dependent Adjustment Mechanisms
Apr 09, 2024Generative Flow Networks (GFlowNets) are probabilistic models predicated on Markov flows, employing specific amortization algorithms to learn stochastic policies that generate compositional substances including biomolecules, chemical materials, and more. Demonstrating formidable prowess in generating high-performance biochemical molecules, GFlowNets accelerate the discovery of scientific substances, effectively circumventing the time-consuming, labor-intensive, and costly shortcomings intrinsic to conventional material discovery. However, previous work often struggles to accumulate exploratory experience and is prone to becoming disoriented within expansive sampling spaces. Attempts to address this issue, such as LS-GFN, are limited to local greedy searches and lack broader global adjustments. This paper introduces a novel GFlowNets variant, the Dynamic Backtracking GFN (DB-GFN), which enhances the adaptability of decision-making steps through a reward-based dynamic backtracking mechanism. DB-GFN permits backtracking during the network construction process according to the current state's reward value, thus correcting disadvantageous decisions and exploring alternative pathways during the exploration process. Applied to generative tasks of biochemical molecules and genetic material sequences, DB-GFN surpasses existing GFlowNets models and traditional reinforcement learning methods in terms of sample quality, exploration sample quantity, and training convergence speed. Furthermore, the orthogonal nature of DB-GFN suggests its potential as a powerful tool for future improvements in GFlowNets, with the promise of integrating with other strategies to achieve more efficient search performance.
Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
Mar 04, 2024



Novel-view synthesis with sparse input views is important for real-world applications like AR/VR and autonomous driving. Recent methods have integrated depth information into NeRFs for sparse input synthesis, leveraging depth prior for geometric and spatial understanding. However, most existing works tend to overlook inaccuracies within depth maps and have low time efficiency. To address these issues, we propose a depth-guided robust and fast point cloud fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel grid of features. A point cloud is constructed for each input view, characterized within the voxel grid using matrices and vectors. We accumulate the point cloud of each input view to construct the fused point cloud of the entire scene. Each voxel determines its density and appearance by referring to the point cloud of the entire scene. Through point cloud fusion and voxel grid fine-tuning, inaccuracies in depth values are refined or substituted by those from other views. Moreover, our method can achieve faster reconstruction and greater compactness through effective vector-matrix decomposition. Experimental results underline the superior performance and time efficiency of our approach compared to state-of-the-art baselines.
Joint Attention-Guided Feature Fusion Network for Saliency Detection of Surface Defects
Feb 05, 2024Surface defect inspection plays an important role in the process of industrial manufacture and production. Though Convolutional Neural Network (CNN) based defect inspection methods have made huge leaps, they still confront a lot of challenges such as defect scale variation, complex background, low contrast, and so on. To address these issues, we propose a joint attention-guided feature fusion network (JAFFNet) for saliency detection of surface defects based on the encoder-decoder network. JAFFNet mainly incorporates a joint attention-guided feature fusion (JAFF) module into decoding stages to adaptively fuse low-level and high-level features. The JAFF module learns to emphasize defect features and suppress background noise during feature fusion, which is beneficial for detecting low-contrast defects. In addition, JAFFNet introduces a dense receptive field (DRF) module following the encoder to capture features with rich context information, which helps detect defects of different scales. The JAFF module mainly utilizes a learned joint channel-spatial attention map provided by high-level semantic features to guide feature fusion. The attention map makes the model pay more attention to defect features. The DRF module utilizes a sequence of multi-receptive-field (MRF) units with each taking as inputs all the preceding MRF feature maps and the original input. The obtained DRF features capture rich context information with a large range of receptive fields. Extensive experiments conducted on SD-saliency-900, Magnetic tile, and DAGM 2007 indicate that our method achieves promising performance in comparison with other state-of-the-art methods. Meanwhile, our method reaches a real-time defect detection speed of 66 FPS.
Self-supervised Learning for Electroencephalogram: A Systematic Survey
Jan 09, 2024



Electroencephalogram (EEG) is a non-invasive technique to record bioelectrical signals. Integrating supervised deep learning techniques with EEG signals has recently facilitated automatic analysis across diverse EEG-based tasks. However, the label issues of EEG signals have constrained the development of EEG-based deep models. Obtaining EEG annotations is difficult that requires domain experts to guide collection and labeling, and the variability of EEG signals among different subjects causes significant label shifts. To solve the above challenges, self-supervised learning (SSL) has been proposed to extract representations from unlabeled samples through well-designed pretext tasks. This paper concentrates on integrating SSL frameworks with temporal EEG signals to achieve efficient representation and proposes a systematic review of the SSL for EEG signals. In this paper, 1) we introduce the concept and theory of self-supervised learning and typical SSL frameworks. 2) We provide a comprehensive review of SSL for EEG analysis, including taxonomy, methodology, and technique details of the existing EEG-based SSL frameworks, and discuss the difference between these methods. 3) We investigate the adaptation of the SSL approach to various downstream tasks, including the task description and related benchmark datasets. 4) Finally, we discuss the potential directions for future SSL-EEG research.
Multi-GradSpeech: Towards Diffusion-based Multi-Speaker Text-to-speech Using Consistent Diffusion Models
Aug 31, 2023

Despite imperfect score-matching causing drift in training and sampling distributions of diffusion models, recent advances in diffusion-based acoustic models have revolutionized data-sufficient single-speaker Text-to-Speech (TTS) approaches, with Grad-TTS being a prime example. However, the sampling drift problem leads to these approaches struggling in multi-speaker scenarios in practice due to more complex target data distribution compared to single-speaker scenarios. In this paper, we present Multi-GradSpeech, a multi-speaker diffusion-based acoustic models which introduces the Consistent Diffusion Model (CDM) as a generative modeling approach. We enforce the consistency property of CDM during the training process to alleviate the sampling drift problem in the inference stage, resulting in significant improvements in multi-speaker TTS performance. Our experimental results corroborate that our proposed approach can improve the performance of different speakers involved in multi-speaker TTS compared to Grad-TTS, even outperforming the fine-tuning approach. Audio samples are available at https://welkinyang.github.io/multi-gradspeech/
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022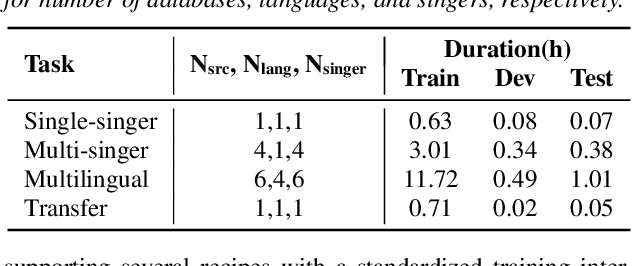
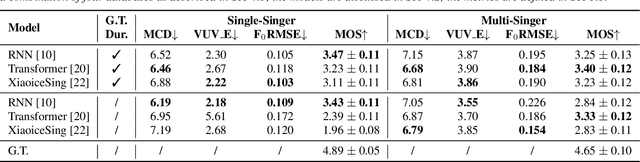
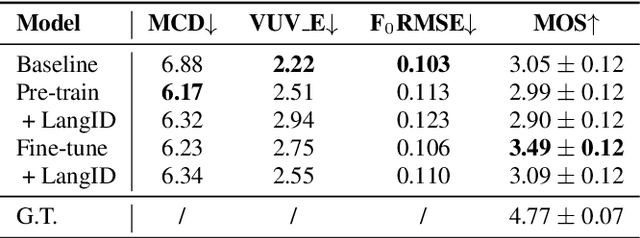
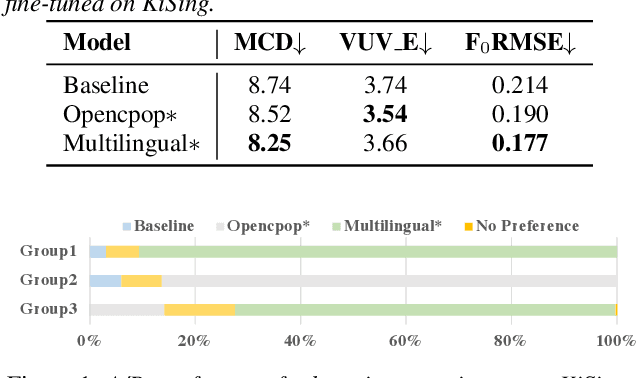
This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.