 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning via Thought Compression for Language Segmentation
Apr 02, 2026Chain-of-thought (CoT) reasoning has significantly improved the performance of large multimodal models in language-guided segmentation, yet its prohibitive computational cost, stemming from generating verbose rationales, limits real-world applicability. We introduce WISE (Wisdom from Internal Self-Exploration), a novel paradigm for efficient reasoning guided by the principle of \textit{thinking twice -- once for learning, once for speed}. WISE trains a model to generate a structured sequence: a concise rationale, the final answer, and then a detailed explanation. By placing the concise rationale first, our method leverages autoregressive conditioning to enforce that the concise rationale acts as a sufficient summary for generating the detailed explanation. This structure is reinforced by a self-distillation objective that jointly rewards semantic fidelity and conciseness, compelling the model to internalize its detailed reasoning into a compact form. At inference, the detailed explanation is omitted. To address the resulting conditional distribution shift, our inference strategy, WISE-S, employs a simple prompting technique that injects a brevity-focused instruction into the user's query. This final adjustment facilitates the robust activation of the learned concise policy, unlocking the full benefits of our framework. Extensive experiments show that WISE-S achieves state-of-the-art zero-shot performance on the ReasonSeg benchmark with 58.3 cIoU, while reducing the average reasoning length by nearly \textbf{5$\times$} -- from 112 to just 23 tokens. Code is available at \href{https://github.com/mrazhou/WISE}{WISE}.
PGR-Net: Prior-Guided ROI Reasoning Network for Brain Tumor MRI Segmentation
Mar 23, 2026Brain tumor MRI segmentation is essential for clinical diagnosis and treatment planning, enabling accurate lesion detection and radiotherapy target delineation. However, tumor lesions occupy only a small fraction of the volumetric space, resulting in severe spatial sparsity, while existing segmentation networks often overlook clinically observed spatial priors of tumor occurrence, leading to redundant feature computation over extensive background regions. To address this issue, we propose PGR-Net (Prior-Guided ROI Reasoning Network) - an explicit ROI-aware framework that incorporates a data-driven spatial prior set to capture the distribution and scale characteristics of tumor lesions, providing global guidance for more stable segmentation. Leveraging these priors, PGR-Net introduces a hierarchical Top-K ROI decision mechanism that progressively selects the most confident lesion candidate regions across encoder layers to improve localization precision. We further develop the WinGS-ROI (Windowed Gaussian-Spatial Decay ROI) module, which uses multi-window Gaussian templates with a spatial decay function to produce center-enhanced guidance maps, thus directing feature learning throughout the network. With these ROI features, a windowed RetNet backbone is adopted to enhance localization reliability. Experiments on BraTS-2019/2023 and MSD Task01 show that PGR-Net consistently outperforms existing approaches while using only 8.64M Params, achieving Dice scores of 89.02%, 91.82%, and 89.67% on the Whole Tumor region. Code is available at https://github.com/CNU-MedAI-Lab/PGR-Net.
DSA-SRGS: Super-Resolution Gaussian Splatting for Dynamic Sparse-View DSA Reconstruction
Mar 05, 2026Digital subtraction angiography (DSA) is a key imaging technique for the auxiliary diagnosis and treatment of cerebrovascular diseases. Recent advancements in gaussian splatting and dynamic neural representations have enabled robust 3D vessel reconstruction from sparse dynamic inputs. However, these methods are fundamentally constrained by the resolution of input projections, where performing naive upsampling to enhance rendering resolution inevitably results in severe blurring and aliasing artifacts. Such lack of super-resolution capability prevents the reconstructed 4D models from recovering fine-grained vascular details and intricate branching structures, which restricts their application in precision diagnosis and treatment. To solve this problem, this paper proposes DSA-SRGS, the first super-resolution gaussian splatting framework for dynamic sparse-view DSA reconstruction. Specifically, we introduce a Multi-Fidelity Texture Learning Module that integrates high-quality priors from a fine-tuned DSA-specific super-resolution model, into the 4D reconstruction optimization. To mitigate potential hallucination artifacts from pseudo-labels, this module employs a Confidence-Aware Strategy to adaptively weight supervision signals between the original low-resolution projections and the generated high-resolution pseudo-labels. Furthermore, we develop Radiative Sub-Pixel Densification, an adaptive strategy that leverages gradient accumulation from high-resolution sub-pixel sampling to refine the 4D radiative gaussian kernels. Extensive experiments on two clinical DSA datasets demonstrate that DSA-SRGS significantly outperforms state-of-the-art methods in both quantitative metrics and qualitative visual fidelity.
From Domains to Instances: Dual-Granularity Data Synthesis for LLM Unlearning
Jan 07, 2026Although machine unlearning is essential for removing private, harmful, or copyrighted content from LLMs, current benchmarks often fail to faithfully represent the true "forgetting scope" learned by the model. We formalize two distinct unlearning granularities, domain-level and instance-level, and propose BiForget, an automated framework for synthesizing high-quality forget sets. Unlike prior work relying on external generators, BiForget exploits the target model per se to elicit data that matches its internal knowledge distribution through seed-guided and adversarial prompting. Our experiments across diverse benchmarks show that it achieves a superior balance of relevance, diversity, and efficiency. Quantitatively, in the Harry Potter domain, it improves relevance by ${\sim}20$ and diversity by ${\sim}$0.05 while halving the total data size compared to SOTAs. Ultimately, it facilitates more robust forgetting and better utility preservation, providing a more rigorous foundation for evaluating LLM unlearning.
M-Net: MRI Brain Tumor Sequential Segmentation Network via Mesh-Cast
Jul 28, 2025MRI tumor segmentation remains a critical challenge in medical imaging, where volumetric analysis faces unique computational demands due to the complexity of 3D data. The spatially sequential arrangement of adjacent MRI slices provides valuable information that enhances segmentation continuity and accuracy, yet this characteristic remains underutilized in many existing models. The spatial correlations between adjacent MRI slices can be regarded as "temporal-like" data, similar to frame sequences in video segmentation tasks. To bridge this gap, we propose M-Net, a flexible framework specifically designed for sequential image segmentation. M-Net introduces the novel Mesh-Cast mechanism, which seamlessly integrates arbitrary sequential models into the processing of both channel and temporal information, thereby systematically capturing the inherent "temporal-like" spatial correlations between MRI slices. Additionally, we define an MRI sequential input pattern and design a Two-Phase Sequential (TPS) training strategy, which first focuses on learning common patterns across sequences before refining slice-specific feature extraction. This approach leverages temporal modeling techniques to preserve volumetric contextual information while avoiding the high computational cost of full 3D convolutions, thereby enhancing the generalizability and robustness of M-Net in sequential segmentation tasks. Experiments on the BraTS2019 and BraTS2023 datasets demonstrate that M-Net outperforms existing methods across all key metrics, establishing itself as a robust solution for temporally-aware MRI tumor segmentation.
Dual-Modal Prototype Joint Learning for Compositional Zero-Shot Learning
Jan 23, 2025



Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions of attributes and objects by leveraging knowledge learned from seen compositions. Recent approaches have explored the use of Vision-Language Models (VLMs) to align textual and visual modalities. These methods typically employ prompt engineering, parameter-tuning, and modality fusion to generate rich textual prototypes that serve as class prototypes for CZSL. However, the modality gap results in textual prototypes being unable to fully capture the optimal representations of all class prototypes, particularly those with fine-grained features, which can be directly obtained from the visual modality. In this paper, we propose a novel Dual-Modal Prototype Joint Learning framework for the CZSL task. Our approach, based on VLMs, introduces prototypes in both the textual and visual modalities. The textual prototype is optimized to capture broad conceptual information, aiding the model's generalization across unseen compositions. Meanwhile, the visual prototype is used to mitigate the classification errors caused by the modality gap and capture fine-grained details to distinguish images with similar appearances. To effectively optimize these prototypes, we design specialized decomposition modules and a joint learning strategy that enrich the features from both modalities. These prototypes not only capture key category information during training but also serve as crucial reference targets during inference. Experimental results demonstrate that our approach achieves state-of-the-art performance in the closed-world setting and competitive performance in the open-world setting across three publicly available CZSL benchmarks. These findings validate the effectiveness of our method in advancing compositional generalization.
Fuzzy Logic Guided Reward Function Variation: An Oracle for Testing Reinforcement Learning Programs
Jun 28, 2024



Reinforcement Learning (RL) has gained significant attention across various domains. However, the increasing complexity of RL programs presents testing challenges, particularly the oracle problem: defining the correctness of the RL program. Conventional human oracles struggle to cope with the complexity, leading to inefficiencies and potential unreliability in RL testing. To alleviate this problem, we propose an automated oracle approach that leverages RL properties using fuzzy logic. Our oracle quantifies an agent's behavioral compliance with reward policies and analyzes its trend over training episodes. It labels an RL program as "Buggy" if the compliance trend violates expectations derived from RL characteristics. We evaluate our oracle on RL programs with varying complexities and compare it with human oracles. Results show that while human oracles perform well in simpler testing scenarios, our fuzzy oracle demonstrates superior performance in complex environments. The proposed approach shows promise in addressing the oracle problem for RL testing, particularly in complex cases where manual testing falls short. It offers a potential solution to improve the efficiency, reliability, and scalability of RL program testing. This research takes a step towards automated testing of RL programs and highlights the potential of fuzzy logic-based oracles in tackling the oracle problem.
Explore the difficulty of words and its influential attributes based on the Wordle game
May 03, 2023

We adopt the distribution and expectation of guessing times in game Wordle as metrics to predict the difficulty of words and explore their influence factors. In order to predictthe difficulty distribution, we use Monte Carlo to simulate the guessing process of players and then narrow the gap between raw and actual distribution of guessing times for each word with Markov which generates the associativity of words. Afterwards, we take advantage of lasso regression to predict the deviation of guessing times expectation and quadratic programming to obtain the correction of the original distribution.To predict the difficulty levels, we first use hierarchical clustering to classify the difficulty levels based on the expectation of guessing times. Afterwards we downscale the variables of lexical attributes based on factor analysis. Significant factors include the number of neighboring words, letter similarity, sub-string similarity, and word frequency. Finally, we build the relationship between lexical attributes and difficulty levels through ordered logistic regression.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023



In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
TENET: Transformer Encoding Network for Effective Temporal Flow on Motion Prediction
Jun 30, 2022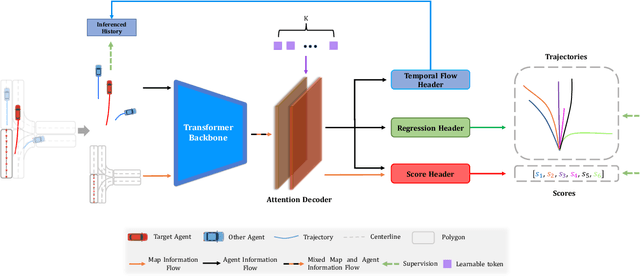

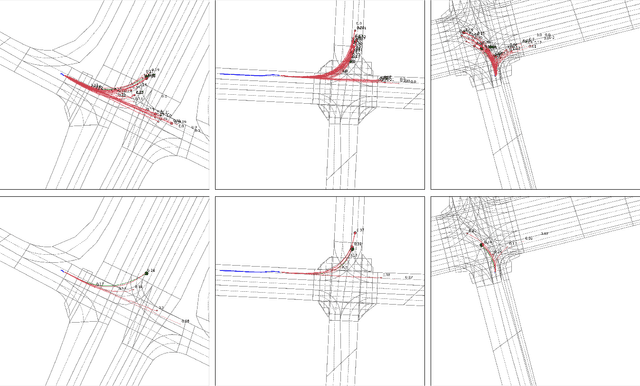
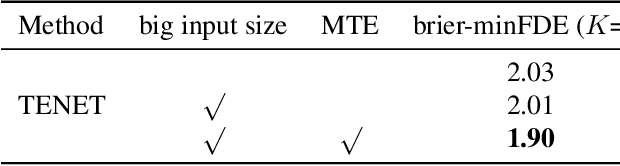
This technical report presents an effective method for motion prediction in autonomous driving. We develop a Transformer-based method for input encoding and trajectory prediction. Besides, we propose the Temporal Flow Header to enhance the trajectory encoding. In the end, an efficient K-means ensemble method is used. Using our Transformer network and ensemble method, we win the first place of Argoverse 2 Motion Forecasting Challenge with the state-of-the-art brier-minFDE score of 1.90.