 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE-Cascade: Cost-Adaptive Vision-Language Routing for Chart Question Answering
Jun 17, 2026Vision-language models (VLMs) are powerful for chart question answering, but invoking a VLM for every query can be unnecessarily expensive when many questions are answerable from OCR text and lightweight language reasoning. We demonstrate SAFE-Cascade, an interactive system for cost-adaptive chart question answering. Given a chart image and a natural-language question, SAFE-Cascade first extracts chart text with OCR, obtains a provisional answer from a text-only language model, and then uses a learned router to decide whether to accept the text answer or escalate to a VLM. The demo exposes this decision process to users: OCR evidence, text-only answer, routing probability, escalation decision, final answer, estimated cost, and estimated latency are shown side by side. SAFE-Cascade is designed as a transparent interface for understanding when visual grounding is actually needed. Users can upload or select charts, ask questions, inspect the evidence used by each pathway, compare text-only and VLM answers, and adjust the escalation threshold to explore the accuracy-cost frontier. The system is implemented with Azure Document Intelligence for OCR, gpt-5-mini as the text-only model, gemini-2.5-flash-image as the VLM, and a Random Forest router trained on inference-time features. On a held-out ChartQA test split of 375 examples from a 2,500-example experiment, SAFE-Cascade achieves 69.1% unified accuracy with 73.1% VLM invocation, compared with 67.7% accuracy and 100% VLM invocation for the full-VLM baseline. The observed +1.4 percentage-point difference is statistically uncertain, so we interpret SAFE-Cascade as matching full-VLM performance while reducing VLM calls by 26.9% and estimated cost by 9.3%. The demonstration shows how selective modality routing can make multimodal knowledge systems more transparent, tunable, and cost-aware.
LoReC: Rethinking Large Language Models for Graph Data Analysis
Apr 20, 2026The advent of Large Language Models (LLMs) has fundamentally reshaped the way we interact with graphs, giving rise to a new paradigm called GraphLLM. As revealed in recent studies, graph learning can benefit from LLMs. However, we observe limited benefits when we directly utilize LLMs to make predictions for graph-related tasks within GraphLLM paradigm, which even yields suboptimal results compared to conventional GNN-based approaches. Through in-depth analysis, we find this failure can be attributed to LLMs' limited capability for processing graph data and their tendency to overlook graph information. To address this issue, we propose LoReC (Look, Remember, and Contrast), a novel plug-and-play method for GraphLLM paradigm, which enhances LLM's understanding of graph data through three stages: (1) Look: redistributing attention to graph; (2) Remember: re-injecting graph information into the Feed-Forward Network (FFN); (3) Contrast: rectifying the vanilla logits produced in the decoding process. Extensive experiments demonstrate that LoReC brings notable improvements over current GraphLLM methods and outperforms GNN-based approaches across diverse datasets. The implementation is available at https://github.com/Git-King-Zhan/LoReC.
Online Fault Tolerance Strategy for Abrupt Reachability Constraint Changes
Jan 03, 2025

When a system's constraints change abruptly, the system's reachability safety does no longer sustain. Thus, the system can reach a forbidden/dangerous value. Conventional remedy practically involves online controller redesign (OCR) to re-establish the reachability's compliance with the new constraints, which, however, is usually too slow. There is a need for an online strategy capable of managing runtime changes in reachability constraints. However, to the best of the authors' knowledge, this topic has not been addressed in the existing literature. In this paper, we propose a fast fault tolerance strategy to recover the system's reachability safety in runtime. Instead of redesigning the system's controller, we propose to change the system's reference state to modify the system's reachability to comply with the new constraints. We frame the reference state search as an optimization problem and employ the Karush-Kuhn-Tucker (KKT) method as well as the Interior Point Method (IPM) based Newton's method (as a fallback for the KKT method) for fast solution derivation. The optimization also allows more future fault tolerance. Numerical simulations demonstrate that our method outperforms the conventional OCR method in terms of computational efficiency and success rate. Specifically, the results show that the proposed method finds a solution $10^{2}$ (with the IPM based Newton's method) $\sim 10^{4}$ (with the KKT method) times faster than the OCR method. Additionally, the improvement rate of the success rate of our method over the OCR method is $40.81\%$ without considering the deadline of run time. The success rate remains at $49.44\%$ for the proposed method, while it becomes $0\%$ for the OCR method when a deadline of $1.5 \; seconds$ is imposed.
Fuzzy Logic Guided Reward Function Variation: An Oracle for Testing Reinforcement Learning Programs
Jun 28, 2024



Reinforcement Learning (RL) has gained significant attention across various domains. However, the increasing complexity of RL programs presents testing challenges, particularly the oracle problem: defining the correctness of the RL program. Conventional human oracles struggle to cope with the complexity, leading to inefficiencies and potential unreliability in RL testing. To alleviate this problem, we propose an automated oracle approach that leverages RL properties using fuzzy logic. Our oracle quantifies an agent's behavioral compliance with reward policies and analyzes its trend over training episodes. It labels an RL program as "Buggy" if the compliance trend violates expectations derived from RL characteristics. We evaluate our oracle on RL programs with varying complexities and compare it with human oracles. Results show that while human oracles perform well in simpler testing scenarios, our fuzzy oracle demonstrates superior performance in complex environments. The proposed approach shows promise in addressing the oracle problem for RL testing, particularly in complex cases where manual testing falls short. It offers a potential solution to improve the efficiency, reliability, and scalability of RL program testing. This research takes a step towards automated testing of RL programs and highlights the potential of fuzzy logic-based oracles in tackling the oracle problem.
Phy-Taylor: Physics-Model-Based Deep Neural Networks
Sep 27, 2022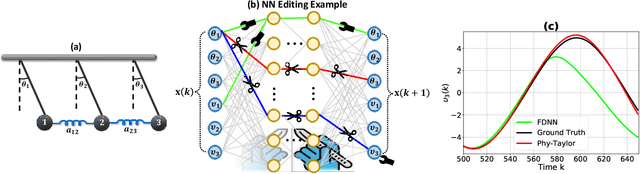
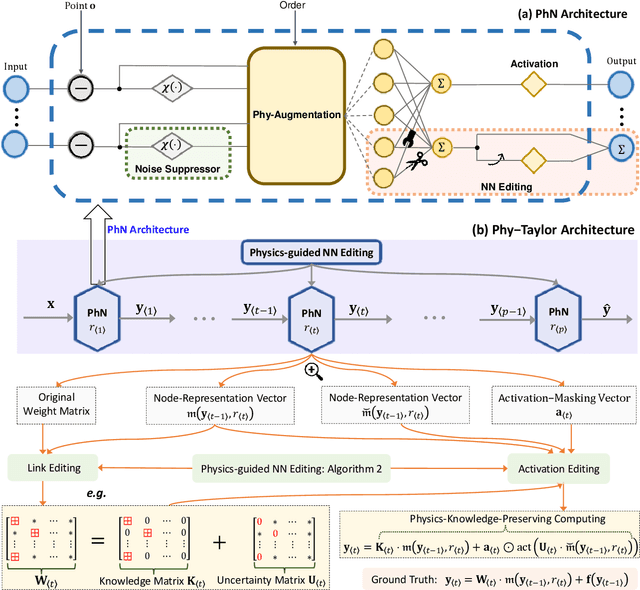
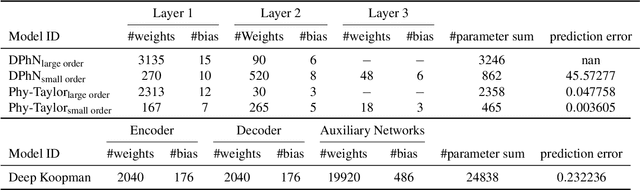
Purely data-driven deep neural networks (DNNs) applied to physical engineering systems can infer relations that violate physics laws, thus leading to unexpected consequences. To address this challenge, we propose a physics-model-based DNN framework, called Phy-Taylor, that accelerates learning compliant representations with physical knowledge. The Phy-Taylor framework makes two key contributions; it introduces a new architectural Physics-compatible neural network (PhN), and features a novel compliance mechanism, we call {\em Physics-guided Neural Network Editing\/}. The PhN aims to directly capture nonlinearities inspired by physical quantities, such as kinetic energy, potential energy, electrical power, and aerodynamic drag force. To do so, the PhN augments neural network layers with two key components: (i) monomials of Taylor series expansion of nonlinear functions capturing physical knowledge, and (ii) a suppressor for mitigating the influence of noise. The neural-network editing mechanism further modifies network links and activation functions consistently with physical knowledge. As an extension, we also propose a self-correcting Phy-Taylor framework that introduces two additional capabilities: (i) physics-model-based safety relationship learning, and (ii) automatic output correction when violations of safety occur. Through experiments, we show that (by expressing hard-to-learn nonlinearities directly and by constraining dependencies) Phy-Taylor features considerably fewer parameters, and a remarkably accelerated training process, while offering enhanced model robustness and accuracy.
Non-destructive three-dimensional measurement of hand vein based on self-supervised network
Jun 29, 2019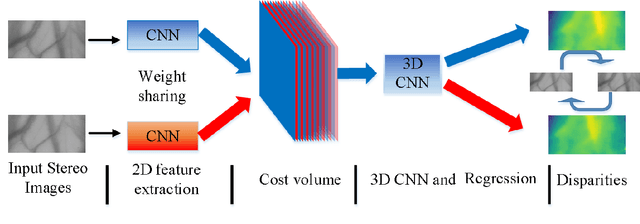
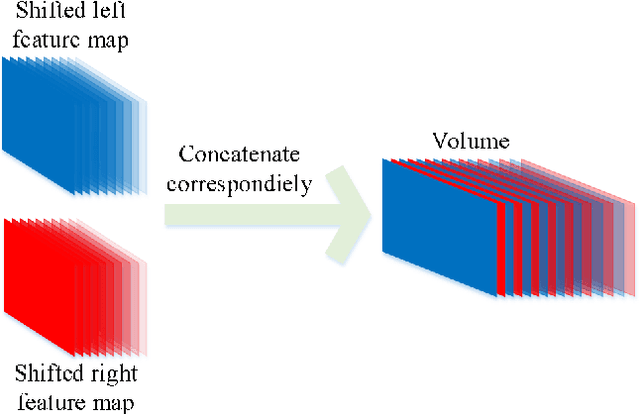
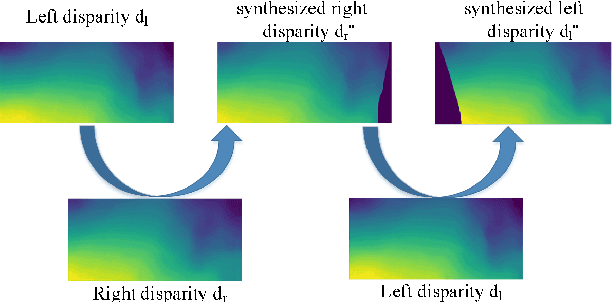
At present, supervised stereo methods based on deep neural network have achieved impressive results. However, in some scenarios, accurate three-dimensional labels are inaccessible for supervised training. In this paper, a self-supervised network is proposed for binocular disparity matching (SDMNet), which computes dense disparity maps from stereo image pairs without disparity labels: In the self-supervised training, we match the stereo images densely to approximate the disparity maps and use them to warp the left and right images to estimate the right and left images; we build the loss function between estimated images and original images for self-supervised training, which adopts perceptual loss to help improve the quality of disparity maps in both detail and structure. Then, we use SDMNet to obtain disparities of hand vein. SDMNet has achieved excellent results on KITTI 2012, KITTI 2015, simulated vein dataset and real vein dataset, outperforming many state-of-the-art supervised matching methods.
Chinese Song Iambics Generation with Neural Attention-based Model
Jun 21, 2016
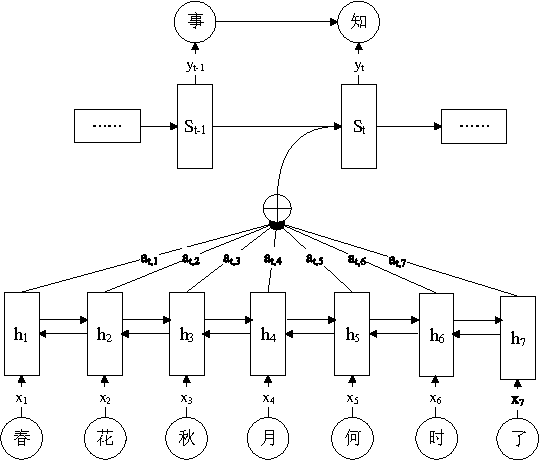


Learning and generating Chinese poems is a charming yet challenging task. Traditional approaches involve various language modeling and machine translation techniques, however, they perform not as well when generating poems with complex pattern constraints, for example Song iambics, a famous type of poems that involve variable-length sentences and strict rhythmic patterns. This paper applies the attention-based sequence-to-sequence model to generate Chinese Song iambics. Specifically, we encode the cue sentences by a bi-directional Long-Short Term Memory (LSTM) model and then predict the entire iambic with the information provided by the encoder, in the form of an attention-based LSTM that can regularize the generation process by the fine structure of the input cues. Several techniques are investigated to improve the model, including global context integration, hybrid style training, character vector initialization and adaptation. Both the automatic and subjective evaluation results show that our model indeed can learn the complex structural and rhythmic patterns of Song iambics, and the generation is rather successful.
Can Machine Generate Traditional Chinese Poetry? A Feigenbaum Test
Jun 19, 2016
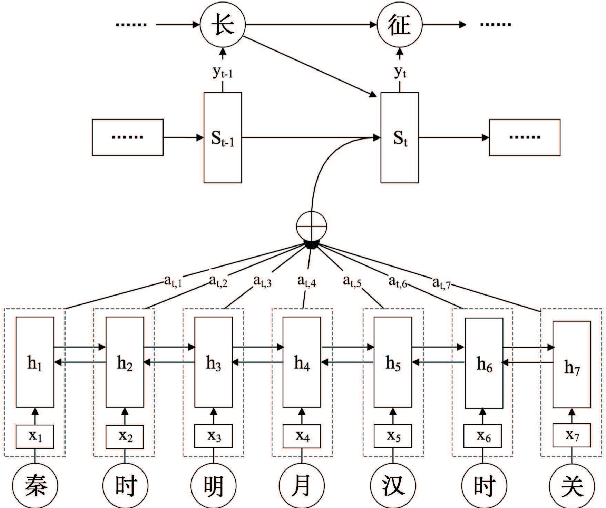
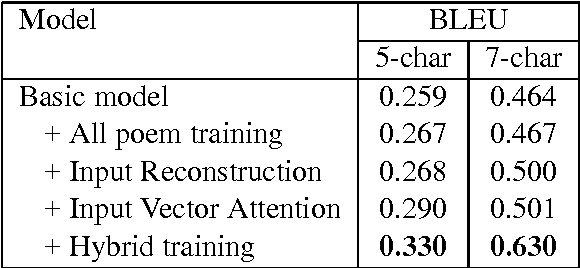
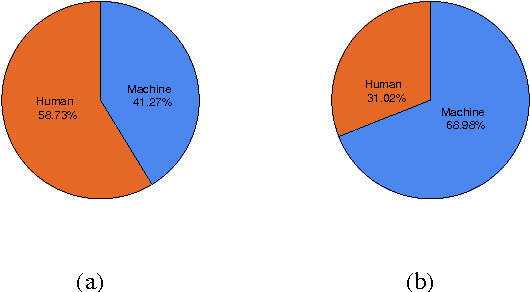
Recent progress in neural learning demonstrated that machines can do well in regularized tasks, e.g., the game of Go. However, artistic activities such as poem generation are still widely regarded as human's special capability. In this paper, we demonstrate that a simple neural model can imitate human in some tasks of art generation. We particularly focus on traditional Chinese poetry, and show that machines can do as well as many contemporary poets and weakly pass the Feigenbaum Test, a variant of Turing test in professional domains. Our method is based on an attention-based recurrent neural network, which accepts a set of keywords as the theme and generates poems by looking at each keyword during the generation. A number of techniques are proposed to improve the model, including character vector initialization, attention to input and hybrid-style training. Compared to existing poetry generation methods, our model can generate much more theme-consistent and semantic-rich poems.