 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Open-Vocabulary Visual Grounding for Remote Sensing Images and Videos
Jun 15, 2026Remote sensing visual grounding (RSVG) aims to localize a referred target in a remote sensing image or video according to a natural language expression. Existing RSVG methods usually rely on task-specific manual annotations, which are costly to collect and inevitably limited in covering the diversity of real-world geospatial scenarios. As a result, they often struggle to generalize to open-vocabulary queries involving novel objects, fine-grained attributes, complex spatial relationships, and functional semantics. In this paper, we propose RSVG-ZeroOV, a training-free framework that leverages frozen generic foundation models for zero-shot open-vocabulary RSVG. RSVG-ZeroOV follows an Overview-Focus-Evolve paradigm, which exploits the distinct yet complementary attention patterns of vision-language models (VLMs) and diffusion models (DMs) to progressively generate precise grounding results. Specifically, (i) Overview utilizes a VLM to extract cross-attention maps that capture semantic correlations between the referring expression and visual regions; (ii) Focus leverages the fine-grained modeling priors of a DM to compensate for object structure and shape information often overlooked by VLM attention; and (iii) Evolve introduces a simple yet effective attention evolution module to suppress irrelevant activations, yielding purified object masks. To handle video inputs, we further present Video RSVG-ZeroOV, which extends image-level grounding to spatio-temporal grounding through a query-relevant key-frame selector and a temporal propagator, enabling efficient and temporally coherent video grounding without video annotations or fine-tuning. Extensive experiments on six image and video grounding benchmarks show that RSVG-ZeroOV consistently outperforms existing zero-shot baselines and achieves competitive or superior performance compared with weakly- and fully-supervised methods.
Efficient Reasoning via Thought Compression for Language Segmentation
Apr 02, 2026Chain-of-thought (CoT) reasoning has significantly improved the performance of large multimodal models in language-guided segmentation, yet its prohibitive computational cost, stemming from generating verbose rationales, limits real-world applicability. We introduce WISE (Wisdom from Internal Self-Exploration), a novel paradigm for efficient reasoning guided by the principle of \textit{thinking twice -- once for learning, once for speed}. WISE trains a model to generate a structured sequence: a concise rationale, the final answer, and then a detailed explanation. By placing the concise rationale first, our method leverages autoregressive conditioning to enforce that the concise rationale acts as a sufficient summary for generating the detailed explanation. This structure is reinforced by a self-distillation objective that jointly rewards semantic fidelity and conciseness, compelling the model to internalize its detailed reasoning into a compact form. At inference, the detailed explanation is omitted. To address the resulting conditional distribution shift, our inference strategy, WISE-S, employs a simple prompting technique that injects a brevity-focused instruction into the user's query. This final adjustment facilitates the robust activation of the learned concise policy, unlocking the full benefits of our framework. Extensive experiments show that WISE-S achieves state-of-the-art zero-shot performance on the ReasonSeg benchmark with 58.3 cIoU, while reducing the average reasoning length by nearly \textbf{5$\times$} -- from 112 to just 23 tokens. Code is available at \href{https://github.com/mrazhou/WISE}{WISE}.
A Benchmark for Multi-Lingual Vision-Language Learning in Remote Sensing Image Captioning
Mar 06, 2025



Remote Sensing Image Captioning (RSIC) is a cross-modal field bridging vision and language, aimed at automatically generating natural language descriptions of features and scenes in remote sensing imagery. Despite significant advances in developing sophisticated methods and large-scale datasets for training vision-language models (VLMs), two critical challenges persist: the scarcity of non-English descriptive datasets and the lack of multilingual capability evaluation for models. These limitations fundamentally impede the progress and practical deployment of RSIC, particularly in the era of large VLMs. To address these challenges, this paper presents several significant contributions to the field. First, we introduce and analyze BRSIC (Bilingual Remote Sensing Image Captioning), a comprehensive bilingual dataset that enriches three established English RSIC datasets with Chinese descriptions, encompassing 13,634 images paired with 68,170 bilingual captions. Building upon this foundation, we develop a systematic evaluation framework that addresses the prevalent inconsistency in evaluation protocols, enabling rigorous assessment of model performance through standardized retraining procedures on BRSIC. Furthermore, we present an extensive empirical study of eight state-of-the-art large vision-language models (LVLMs), examining their capabilities across multiple paradigms including zero-shot inference, supervised fine-tuning, and multi-lingual training. This comprehensive evaluation provides crucial insights into the strengths and limitations of current LVLMs in handling multilingual remote sensing tasks. Additionally, our cross-dataset transfer experiments reveal interesting findings. The code and data will be available at https://github.com/mrazhou/BRSIC.
FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection
Dec 12, 2024



Infrared-visible object detection (IVOD) seeks to harness the complementary information in infrared and visible images, thereby enhancing the performance of detectors in complex environments. However, existing methods often neglect the frequency characteristics of complementary information, such as the abundant high-frequency details in visible images and the valuable low-frequency thermal information in infrared images, thus constraining detection performance. To solve this problem, we introduce a novel Frequency-Driven Feature Decomposition Network for IVOD, called FD2-Net, which effectively captures the unique frequency representations of complementary information across multimodal visual spaces. Specifically, we propose a feature decomposition encoder, wherein the high-frequency unit (HFU) utilizes discrete cosine transform to capture representative high-frequency features, while the low-frequency unit (LFU) employs dynamic receptive fields to model the multi-scale context of diverse objects. Next, we adopt a parameter-free complementary strengths strategy to enhance multimodal features through seamless inter-frequency recoupling. Furthermore, we innovatively design a multimodal reconstruction mechanism that recovers image details lost during feature extraction, further leveraging the complementary information from infrared and visible images to enhance overall representational capacity. Extensive experiments demonstrate that FD2-Net outperforms state-of-the-art (SOTA) models across various IVOD benchmarks, i.e. LLVIP (96.2% mAP), FLIR (82.9% mAP), and M3FD (83.5% mAP).
A Dual Neighborhood Hypergraph Neural Network for Change Detection in VHR Remote Sensing Images
Feb 27, 2022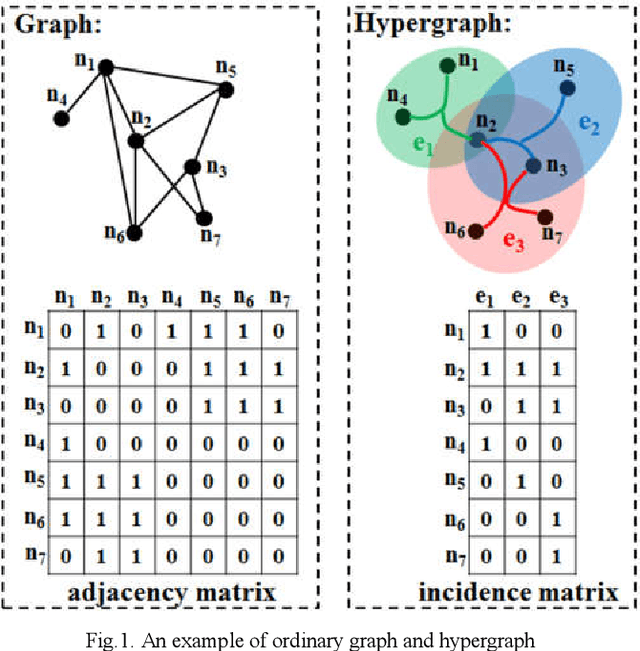
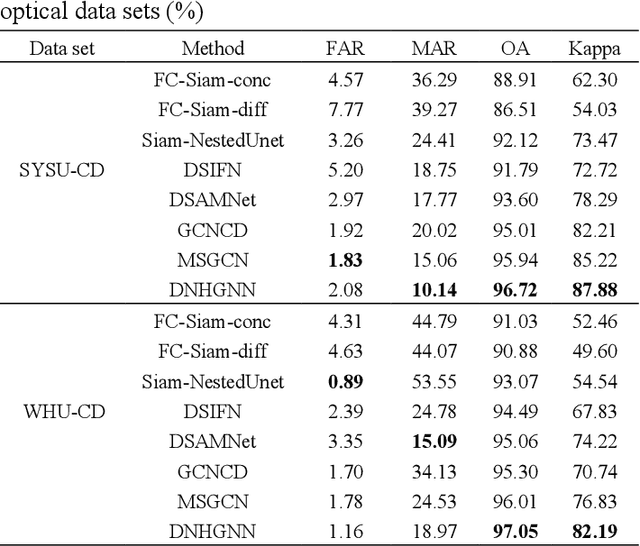
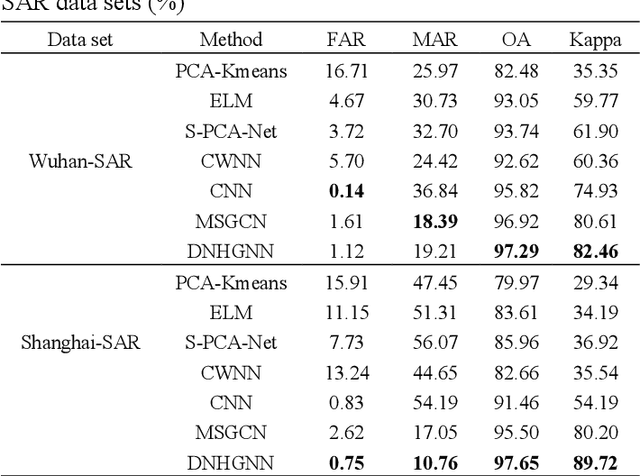
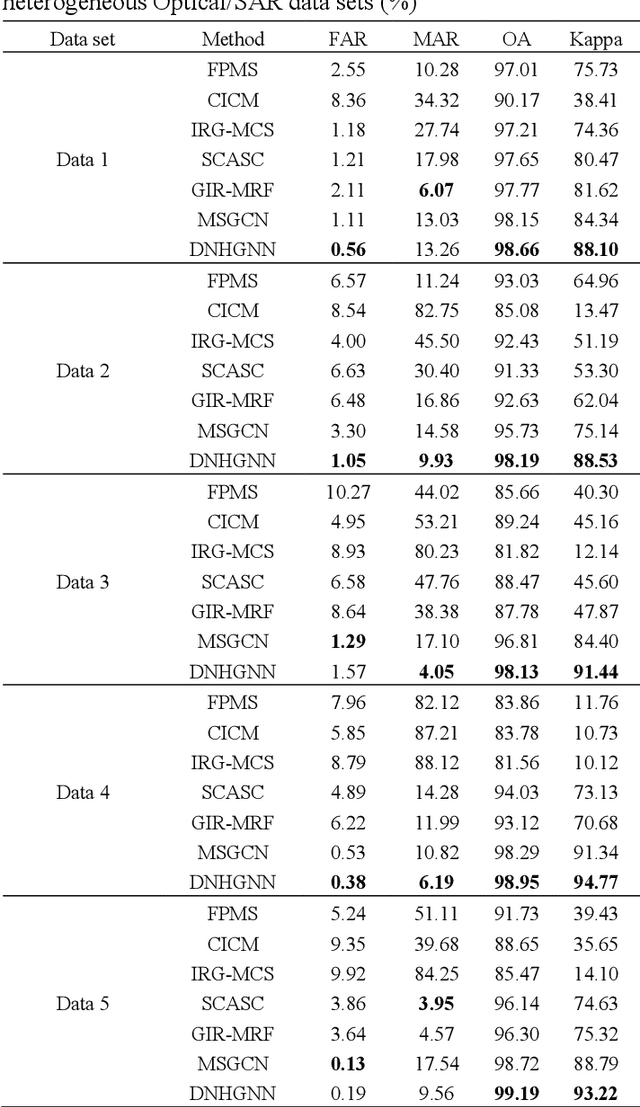
The very high spatial resolution (VHR) remote sensing images have been an extremely valuable source for monitoring changes occurred on the earth surface. However, precisely detecting relevant changes in VHR images still remains a challenge, due to the complexity of the relationships among ground objects. To address this limitation, a dual neighborhood hypergraph neural network is proposed in this article, which combines the multiscale superpixel segmentation and hypergraph convolution to model and exploit the complex relationships. First, the bi-temporal image pairs are segmented under two scales and fed to a pre-trained U-net to obtain node features by treating each object under the fine scale as a node. The dual neighborhood is then defined using the father-child and adjacent relationships of the segmented objects to construct the hypergraph, which permits models to represent the higher-order structured information far more complex than just pairwise relationships. The hypergraph convolutions are conducted on the constructed hypergraph to propagate the label information from a small amount of labeled nodes to the other unlabeled ones by the node-edge-node transform. Moreover, to alleviate the problem of imbalanced sample, the focal loss function is adopted to train the hypergraph neural network. The experimental results on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method comprises better effectiveness and robustness compared to many state-of-the-art methods.
A Multiscale Graph Convolutional Network for Change Detection in Homogeneous and Heterogeneous Remote Sensing Images
Feb 16, 2021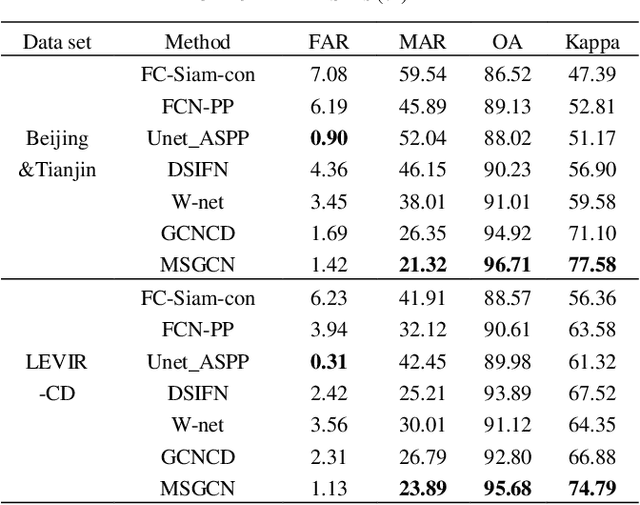
Change detection (CD) in remote sensing images has been an ever-expanding area of research. To date, although many methods have been proposed using various techniques, accurately identifying changes is still a great challenge, especially in the high resolution or heterogeneous situations, due to the difficulties in effectively modeling the features from ground objects with different patterns. In this paper, a novel CD method based on the graph convolutional network (GCN) and multiscale object-based technique is proposed for both homogeneous and heterogeneous images. First, the object-wise high level features are obtained through a pre-trained U-net and the multiscale segmentations. Treating each parcel as a node, the graph representations can be formed and then, fed into the proposed multiscale graph convolutional network with each channel corresponding to one scale. The multiscale GCN propagates the label information from a small number of labeled nodes to the other ones which are unlabeled. Further, to comprehensively incorporate the information from the output channels of multiscale GCN, a fusion strategy is designed using the father-child relationships between scales. Extensive Experiments on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method outperforms some state-of the-art methods in both qualitative and quantitative evaluations. Besides, the Influences of some factors are also discussed.