 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIT: Defying Catastrophic Forgetting in Continual LLM Unlearning
Jan 29, 2026Large language models (LLMs) demonstrate impressive capabilities across diverse tasks but raise concerns about privacy, copyright, and harmful materials. Existing LLM unlearning methods rarely consider the continual and high-volume nature of real-world deletion requests, which can cause utility degradation and catastrophic forgetting as requests accumulate. To address this challenge, we introduce \fit, a framework for continual unlearning that handles large numbers of deletion requests while maintaining robustness against both catastrophic forgetting and post-unlearning recovery. \fit mitigates degradation through rigorous data \underline{F}iltering, \underline{I}mportance-aware updates, and \underline{T}argeted layer attribution, enabling stable performance across long sequences of unlearning operations and achieving a favorable balance between forgetting effectiveness and utility retention. To support realistic evaluation, we present \textbf{PCH}, a benchmark covering \textbf{P}ersonal information, \textbf{C}opyright, and \textbf{H}armful content in sequential deletion scenarios, along with two symmetric metrics, Forget Degree (F.D.) and Retain Utility (R.U.), which jointly assess forgetting quality and utility preservation. Extensive experiments on four open-source LLMs with hundreds of deletion requests show that \fit achieves the strongest trade-off between F.D. and R.U., surpasses existing methods on MMLU, CommonsenseQA, and GSM8K, and remains resistant against both relearning and quantization recovery attacks.
From Domains to Instances: Dual-Granularity Data Synthesis for LLM Unlearning
Jan 07, 2026Although machine unlearning is essential for removing private, harmful, or copyrighted content from LLMs, current benchmarks often fail to faithfully represent the true "forgetting scope" learned by the model. We formalize two distinct unlearning granularities, domain-level and instance-level, and propose BiForget, an automated framework for synthesizing high-quality forget sets. Unlike prior work relying on external generators, BiForget exploits the target model per se to elicit data that matches its internal knowledge distribution through seed-guided and adversarial prompting. Our experiments across diverse benchmarks show that it achieves a superior balance of relevance, diversity, and efficiency. Quantitatively, in the Harry Potter domain, it improves relevance by ${\sim}20$ and diversity by ${\sim}$0.05 while halving the total data size compared to SOTAs. Ultimately, it facilitates more robust forgetting and better utility preservation, providing a more rigorous foundation for evaluating LLM unlearning.
Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in LLMs
May 22, 2025
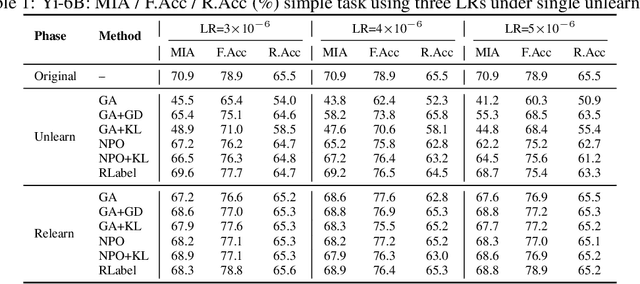

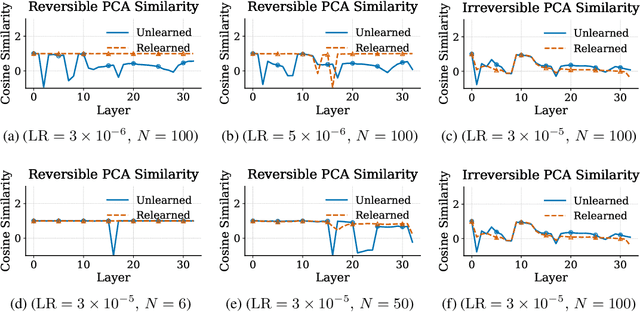
Unlearning in large language models (LLMs) is intended to remove the influence of specific data, yet current evaluations rely heavily on token-level metrics such as accuracy and perplexity. We show that these metrics can be misleading: models often appear to forget, but their original behavior can be rapidly restored with minimal fine-tuning, revealing that unlearning may obscure information rather than erase it. To diagnose this phenomenon, we introduce a representation-level evaluation framework using PCA-based similarity and shift, centered kernel alignment, and Fisher information. Applying this toolkit across six unlearning methods, three domains (text, code, math), and two open-source LLMs, we uncover a critical distinction between reversible and irreversible forgetting. In reversible cases, models suffer token-level collapse yet retain latent features; in irreversible cases, deeper representational damage occurs. We further provide a theoretical account linking shallow weight perturbations near output layers to misleading unlearning signals, and show that reversibility is modulated by task type and hyperparameters. Our findings reveal a fundamental gap in current evaluation practices and establish a new diagnostic foundation for trustworthy unlearning in LLMs. We provide a unified toolkit for analyzing LLM representation changes under unlearning and relearning: https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git.
OBLIVIATE: Robust and Practical Machine Unlearning for Large Language Models
May 07, 2025Large language models (LLMs) trained over extensive corpora risk memorizing sensitive, copyrighted, or toxic content. To address this, we propose OBLIVIATE, a robust unlearning framework that removes targeted data while preserving model utility. The framework follows a structured process: extracting target tokens, building retain sets, and fine-tuning with a tailored loss function comprising three components -- masking, distillation, and world fact. Using low-rank adapters (LoRA), it ensures efficiency without compromising unlearning quality. We conduct experiments on multiple datasets, including the Harry Potter series, WMDP, and TOFU, using a comprehensive suite of metrics: forget quality (new document-level memorization score), model utility, and fluency. Results demonstrate its effectiveness in resisting membership inference attacks, minimizing the impact on retained data, and maintaining robustness across diverse scenarios.
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
Differential Privacy for Text Analytics via Natural Text Sanitization
Jun 02, 2021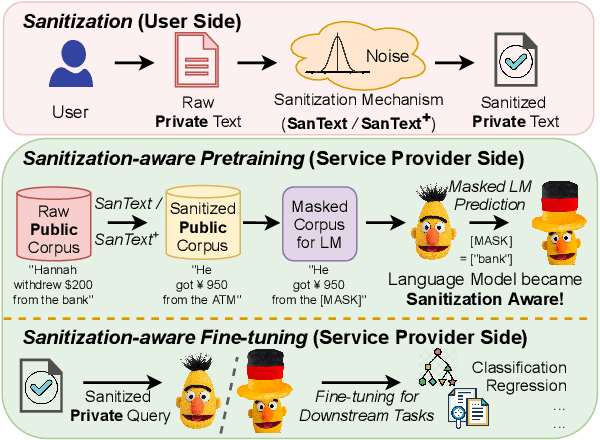
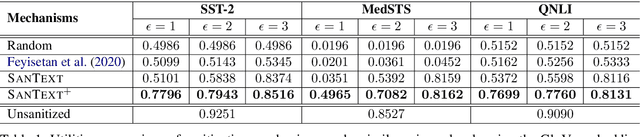
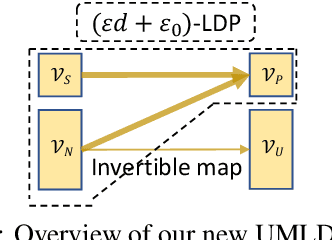
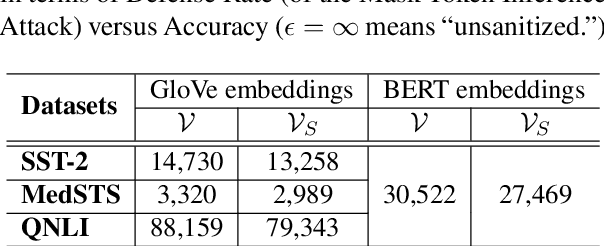
Texts convey sophisticated knowledge. However, texts also convey sensitive information. Despite the success of general-purpose language models and domain-specific mechanisms with differential privacy (DP), existing text sanitization mechanisms still provide low utility, as cursed by the high-dimensional text representation. The companion issue of utilizing sanitized texts for downstream analytics is also under-explored. This paper takes a direct approach to text sanitization. Our insight is to consider both sensitivity and similarity via our new local DP notion. The sanitized texts also contribute to our sanitization-aware pretraining and fine-tuning, enabling privacy-preserving natural language processing over the BERT language model with promising utility. Surprisingly, the high utility does not boost up the success rate of inference attacks.
Optimizing Privacy-Preserving Outsourced Convolutional Neural Network Predictions
Mar 09, 2020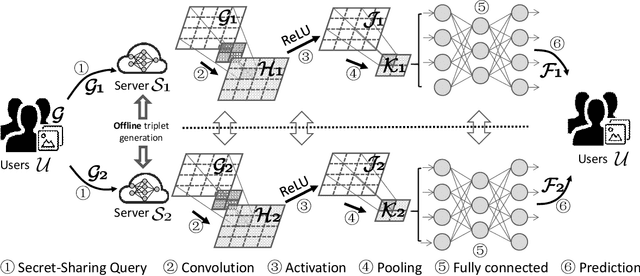
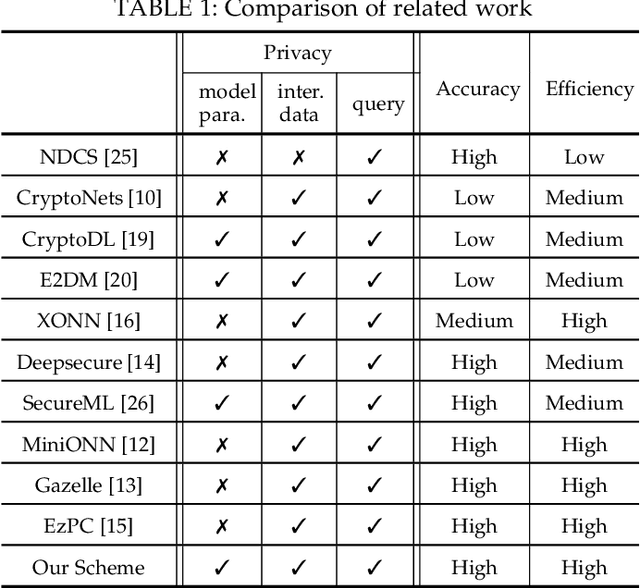
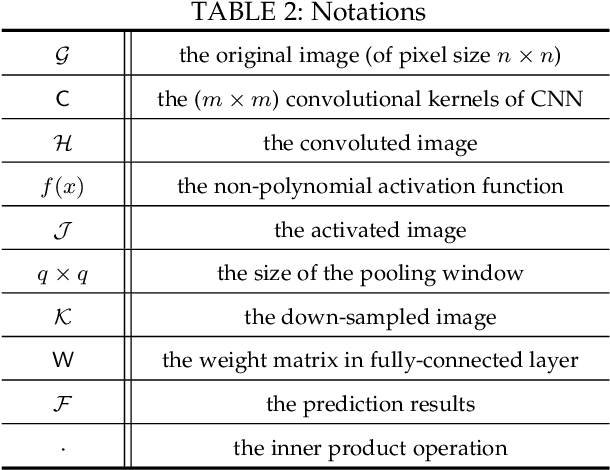

Neural networks provide better prediction performance than previous techniques. Prediction-as-a-service thus becomes popular, especially in the outsourced setting since it involves extensive computation. Recent researches focus on the privacy of the query and results, but they do not provide model privacy against the model-hosting server and may leak partial information about the results. Some of them further require frequent interactions with the querier or heavy computation overheads. This paper proposes a new scheme for privacy-preserving neural network prediction in the outsourced setting, i.e., the server cannot learn the query, (intermediate) results, and the model. Similar to SecureML (S&P'17), a representative work which provides model privacy, we leverage two non-colluding servers with secret sharing and triplet generation to minimize the usage of heavyweight cryptography. Further, we adopt asynchronous computation to improve the throughput, and design garbled circuits for the non-polynomial activation function to keep the same accuracy as the underlying network (instead of approximating it). Our experiments on four neural network architectures show that our scheme achieves an average of 282 improvements in reducing latency compared to SecureML. Compared to MiniONN (CCS'17) and EzPC (EuroS&P'19), both without model privacy, our scheme achieves a lower latency by a factor of 18 and 10, respectively. For the communication costs, our scheme outperforms SecureML by 122, MiniONN by 49, and EzPC by 38 times.