 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stable Canonical Worlds for Novel View Synthesis and Beyond
Jun 25, 2026Feed-forward Gaussian splatting (FFGS) facilitates real-time novel view synthesis, yet current methods often remain tied to view-dependent predictions. As more input views are added, they may accumulate noisy or redundant evidence instead of converging to a stable scene representation. In this paper, we introduce CanonicalGS, a feed-forward pipeline that maps cluttered multi-view observations into a stable, scene-centric representation. CanonicalGS first extracts view-centric evidence from depth, semantic features, and uncertainty estimates, and then aggregates this evidence in a canonical latent world using uncertainty-aware fusion. By emphasizing reliable observations while suppressing uncertain or redundant ones, CanonicalGS produces representations that scale more effectively for novel view synthesis and transfer to downstream visual perception tasks. Experiments show up to a $2.5$ dB improvement in peak signal-to-noise ratio for synthesizing novel views and an $11\%$ gain in semantic segmentation accuracy.
PTDL:Multi-Terrain Fall Recovery via Phase-Terrain Decoupled Learning
Jun 08, 2026Humanoid robots can fall on slopes, gravel, and uneven ground in unstructured environments. We target integrated fall recovery and locomotion: rebuilding balance from a fallen state using proprioception alone and resuming velocity-commanded walking at the fall site. Prior methods often stop at quasi-static rise, neglect the post-fall ground-contact phase, or, when trained on mixed terrains without separating recovery and locomotion phases or per-surface constraints, collapse to a single compromise get-up across surfaces. We propose Phase--Terrain Decoupled Learning (PTDL), which decouples training supervision along phase and terrain axes while deploying one proprioceptive policy. On the phase axis, projected-gravity-gated dual motion-prior discriminators and a probe-to-walk transition link post-fall recovery to commanded walking. On the terrain axis, terrain-stratified recovery shaping assigns surface-specific training supervision on flat ground, gravel, and slopes; terrain labels are training-only and withheld from policy observations, enabling implicit post-fall strategy selection at deployment. We validate PTDL on a 29-DoF Unitree G1 across flat ground, gravel, and slopes up to 20 degrees in simulation and on hardware, achieving stable cross-terrain recovery, smooth recovery-to-locomotion transitions, and differentiated post-fall rise behaviors under one deployed policy.
From Craft to Kernel: A Governance-First Execution Architecture and Semantic ISA for Agentic Computers
Apr 20, 2026The transition of agentic AI from brittle prototypes to production systems is stalled by a pervasive crisis of craft. We suggest that the prevailing orchestration paradigm-delegating the system control loop to large language models and merely patching with heuristic guardrails-is the root cause of this fragility. Instead, we propose Arbiter-K, a Governance-First execution architecture that reconceptualizes the underlying model as a Probabilistic Processing Unit encapsulated by a deterministic, neuro-symbolic kernel. Arbiter-K implements a Semantic Instruction Set Architecture (ISA) to reify probabilistic messages into discrete instructions. This allows the kernel to maintain a Security Context Registry and construct an Instruction Dependency Graph at runtime, enabling active taint propagation based on the data-flow pedigree of each reasoning node. By leveraging this mechanism, Arbiter-K precisely interdicts unsafe trajectories at deterministic sinks (e.g., high-risk tool calls or unauthorized network egress) and enables autonomous execution correction and architectural rollback when security policies are triggered. Evaluations on OpenClaw and NanoBot demonstrate that Arbiter-K enforces security as a microarchitectural property, achieving 76% to 95% unsafe interception for a 92.79% absolute gain over native policies. The code is publicly available at https://github.com/cure-lab/ArbiterOS.
Reasoning Fails Where Step Flow Breaks
Apr 08, 2026Large reasoning models (LRMs) that generate long chains of thought now perform well on multi-step math, science, and coding tasks. However, their behavior is still unstable and hard to interpret, and existing analysis tools struggle with such long, structured reasoning traces. We introduce Step-Saliency, which pools attention--gradient scores into step-to-step maps along the question--thinking--summary trajectory. Across several models, Step-Saliency reveals two recurring information-flow failures: Shallow Lock-in, where shallow layers over-focus on the current step and barely use earlier context, and Deep Decay, where deep layers gradually lose saliency on the thinking segment and the summary increasingly attends to itself and the last few steps. Motivated by these patterns, we propose StepFlow, a saliency-inspired test-time intervention that adjusts shallow saliency patterns measured by Step-Saliency via Odds-Equal Bridge and adds a small step-level residual in deep layers via Step Momentum Injection. StepFlow improves accuracy on math, science, and coding tasks across multiple LRMs without retraining, indicating that repairing information flow can recover part of their missing reasoning performance.
MDS-VQA: Model-Informed Data Selection for Video Quality Assessment
Mar 12, 2026Learning-based video quality assessment (VQA) has advanced rapidly, yet progress is increasingly constrained by a disconnect between model design and dataset curation. Model-centric approaches often iterate on fixed benchmarks, while data-centric efforts collect new human labels without systematically targeting the weaknesses of existing VQA models. Here, we describe MDS-VQA, a model-informed data selection mechanism for curating unlabeled videos that are both difficult for the base VQA model and diverse in content. Difficulty is estimated by a failure predictor trained with a ranking objective, and diversity is measured using deep semantic video features, with a greedy procedure balancing the two under a constrained labeling budget. Experiments across multiple VQA datasets and models demonstrate that MDS-VQA identifies diverse, challenging samples that are particularly informative for active fine-tuning. With only a 5% selected subset per target domain, the fine-tuned model improves mean SRCC from 0.651 to 0.722 and achieves the top gMAD rank, indicating strong adaptation and generalization.
Aesthetic Camera Viewpoint Suggestion with 3D Aesthetic Field
Feb 23, 2026The aesthetic quality of a scene depends strongly on camera viewpoint. Existing approaches for aesthetic viewpoint suggestion are either single-view adjustments, predicting limited camera adjustments from a single image without understanding scene geometry, or 3D exploration approaches, which rely on dense captures or prebuilt 3D environments coupled with costly reinforcement learning (RL) searches. In this work, we introduce the notion of 3D aesthetic field that enables geometry-grounded aesthetic reasoning in 3D with sparse captures, allowing efficient viewpoint suggestions in contrast to costly RL searches. We opt to learn this 3D aesthetic field using a feedforward 3D Gaussian Splatting network that distills high-level aesthetic knowledge from a pretrained 2D aesthetic model into 3D space, enabling aesthetic prediction for novel viewpoints from only sparse input views. Building on this field, we propose a two-stage search pipeline that combines coarse viewpoint sampling with gradient-based refinement, efficiently identifying aesthetically appealing viewpoints without dense captures or RL exploration. Extensive experiments show that our method consistently suggests viewpoints with superior framing and composition compared to existing approaches, establishing a new direction toward 3D-aware aesthetic modeling.
FIT: Defying Catastrophic Forgetting in Continual LLM Unlearning
Jan 29, 2026Large language models (LLMs) demonstrate impressive capabilities across diverse tasks but raise concerns about privacy, copyright, and harmful materials. Existing LLM unlearning methods rarely consider the continual and high-volume nature of real-world deletion requests, which can cause utility degradation and catastrophic forgetting as requests accumulate. To address this challenge, we introduce \fit, a framework for continual unlearning that handles large numbers of deletion requests while maintaining robustness against both catastrophic forgetting and post-unlearning recovery. \fit mitigates degradation through rigorous data \underline{F}iltering, \underline{I}mportance-aware updates, and \underline{T}argeted layer attribution, enabling stable performance across long sequences of unlearning operations and achieving a favorable balance between forgetting effectiveness and utility retention. To support realistic evaluation, we present \textbf{PCH}, a benchmark covering \textbf{P}ersonal information, \textbf{C}opyright, and \textbf{H}armful content in sequential deletion scenarios, along with two symmetric metrics, Forget Degree (F.D.) and Retain Utility (R.U.), which jointly assess forgetting quality and utility preservation. Extensive experiments on four open-source LLMs with hundreds of deletion requests show that \fit achieves the strongest trade-off between F.D. and R.U., surpasses existing methods on MMLU, CommonsenseQA, and GSM8K, and remains resistant against both relearning and quantization recovery attacks.
From Domains to Instances: Dual-Granularity Data Synthesis for LLM Unlearning
Jan 07, 2026Although machine unlearning is essential for removing private, harmful, or copyrighted content from LLMs, current benchmarks often fail to faithfully represent the true "forgetting scope" learned by the model. We formalize two distinct unlearning granularities, domain-level and instance-level, and propose BiForget, an automated framework for synthesizing high-quality forget sets. Unlike prior work relying on external generators, BiForget exploits the target model per se to elicit data that matches its internal knowledge distribution through seed-guided and adversarial prompting. Our experiments across diverse benchmarks show that it achieves a superior balance of relevance, diversity, and efficiency. Quantitatively, in the Harry Potter domain, it improves relevance by ${\sim}20$ and diversity by ${\sim}$0.05 while halving the total data size compared to SOTAs. Ultimately, it facilitates more robust forgetting and better utility preservation, providing a more rigorous foundation for evaluating LLM unlearning.
AutoLugano: A Deep Learning Framework for Fully Automated Lymphoma Segmentation and Lugano Staging on FDG-PET/CT
Dec 08, 2025



Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.
Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in LLMs
May 22, 2025
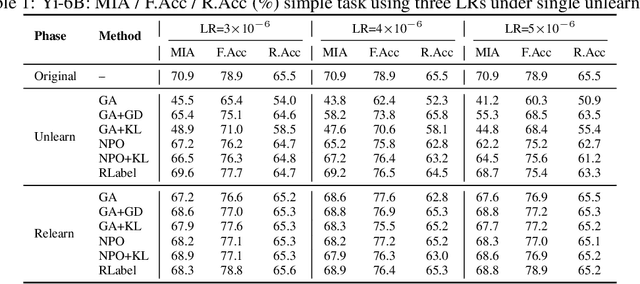

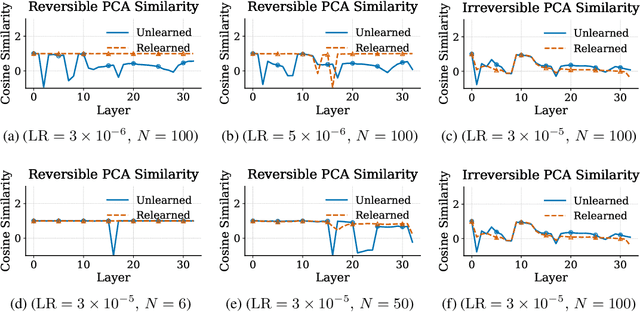
Unlearning in large language models (LLMs) is intended to remove the influence of specific data, yet current evaluations rely heavily on token-level metrics such as accuracy and perplexity. We show that these metrics can be misleading: models often appear to forget, but their original behavior can be rapidly restored with minimal fine-tuning, revealing that unlearning may obscure information rather than erase it. To diagnose this phenomenon, we introduce a representation-level evaluation framework using PCA-based similarity and shift, centered kernel alignment, and Fisher information. Applying this toolkit across six unlearning methods, three domains (text, code, math), and two open-source LLMs, we uncover a critical distinction between reversible and irreversible forgetting. In reversible cases, models suffer token-level collapse yet retain latent features; in irreversible cases, deeper representational damage occurs. We further provide a theoretical account linking shallow weight perturbations near output layers to misleading unlearning signals, and show that reversibility is modulated by task type and hyperparameters. Our findings reveal a fundamental gap in current evaluation practices and establish a new diagnostic foundation for trustworthy unlearning in LLMs. We provide a unified toolkit for analyzing LLM representation changes under unlearning and relearning: https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git.