 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptBoosting: Black-Box Text Classification with Ten Forward Passes
Dec 19, 2022We describe PromptBoosting, a query-efficient procedure for building a text classifier from a neural language model (LM) without access to the LM's parameters, gradients, or hidden representations. This form of "black-box" classifier training has become increasingly important as the cost of training and inference in large-scale LMs grows. But existing black-box LM classifier learning approaches are themselves computationally inefficient, typically specializing LMs to the target task by searching in a large space of (discrete or continuous) prompts using zeroth-order optimization methods. Instead of directly optimizing in prompt space, PromptBoosting obtains a small pool of prompts via a gradient-free approach and then constructs a large pool of weak learners by pairing these prompts with different elements of the LM's output distribution. These weak learners are then ensembled using the AdaBoost algorithm. The entire learning process requires only a small number of forward passes and no backward pass. Experiments show that PromptBoosting achieves state-of-the-art performance in multiple black-box few-shot classification tasks, and matches or outperforms full fine-tuning in both few-shot and standard learning paradigms, while training 10x faster than existing black-box methods.
Uncovering the Disentanglement Capability in Text-to-Image Diffusion Models
Dec 16, 2022Generative models have been widely studied in computer vision. Recently, diffusion models have drawn substantial attention due to the high quality of their generated images. A key desired property of image generative models is the ability to disentangle different attributes, which should enable modification towards a style without changing the semantic content, and the modification parameters should generalize to different images. Previous studies have found that generative adversarial networks (GANs) are inherently endowed with such disentanglement capability, so they can perform disentangled image editing without re-training or fine-tuning the network. In this work, we explore whether diffusion models are also inherently equipped with such a capability. Our finding is that for stable diffusion models, by partially changing the input text embedding from a neutral description (e.g., "a photo of person") to one with style (e.g., "a photo of person with smile") while fixing all the Gaussian random noises introduced during the denoising process, the generated images can be modified towards the target style without changing the semantic content. Based on this finding, we further propose a simple, light-weight image editing algorithm where the mixing weights of the two text embeddings are optimized for style matching and content preservation. This entire process only involves optimizing over around 50 parameters and does not fine-tune the diffusion model itself. Experiments show that the proposed method can modify a wide range of attributes, with the performance outperforming diffusion-model-based image-editing algorithms that require fine-tuning. The optimized weights generalize well to different images. Our code is publicly available at https://github.com/UCSB-NLP-Chang/DiffusionDisentanglement.
CLAWSAT: Towards Both Robust and Accurate Code Models
Nov 22, 2022



We integrate contrastive learning (CL) with adversarial learning to co-optimize the robustness and accuracy of code models. Different from existing works, we show that code obfuscation, a standard code transformation operation, provides novel means to generate complementary `views' of a code that enable us to achieve both robust and accurate code models. To the best of our knowledge, this is the first systematic study to explore and exploit the robustness and accuracy benefits of (multi-view) code obfuscations in code models. Specifically, we first adopt adversarial codes as robustness-promoting views in CL at the self-supervised pre-training phase. This yields improved robustness and transferability for downstream tasks. Next, at the supervised fine-tuning stage, we show that adversarial training with a proper temporally-staggered schedule of adversarial code generation can further improve robustness and accuracy of the pre-trained code model. Built on the above two modules, we develop CLAWSAT, a novel self-supervised learning (SSL) framework for code by integrating $\underline{\textrm{CL}}$ with $\underline{\textrm{a}}$dversarial vie$\underline{\textrm{w}}$s (CLAW) with $\underline{\textrm{s}}$taggered $\underline{\textrm{a}}$dversarial $\underline{\textrm{t}}$raining (SAT). On evaluating three downstream tasks across Python and Java, we show that CLAWSAT consistently yields the best robustness and accuracy ($\textit{e.g.}$ 11$\%$ in robustness and 6$\%$ in accuracy on the code summarization task in Python). We additionally demonstrate the effectiveness of adversarial learning in CLAW by analyzing the characteristics of the loss landscape and interpretability of the pre-trained models.
Data-Model-Circuit Tri-Design for Ultra-Light Video Intelligence on Edge Devices
Oct 18, 2022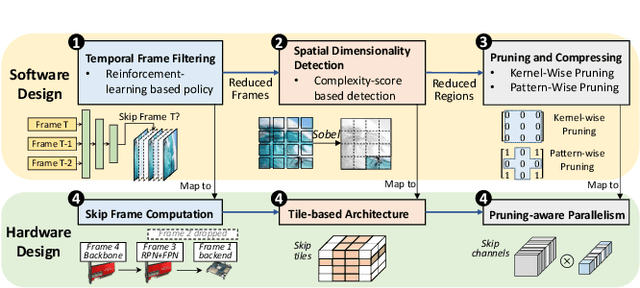
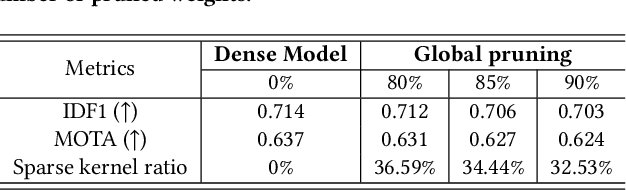


In this paper, we propose a data-model-hardware tri-design framework for high-throughput, low-cost, and high-accuracy multi-object tracking (MOT) on High-Definition (HD) video stream. First, to enable ultra-light video intelligence, we propose temporal frame-filtering and spatial saliency-focusing approaches to reduce the complexity of massive video data. Second, we exploit structure-aware weight sparsity to design a hardware-friendly model compression method. Third, assisted with data and model complexity reduction, we propose a sparsity-aware, scalable, and low-power accelerator design, aiming to deliver real-time performance with high energy efficiency. Different from existing works, we make a solid step towards the synergized software/hardware co-optimization for realistic MOT model implementation. Compared to the state-of-the-art MOT baseline, our tri-design approach can achieve 12.5x latency reduction, 20.9x effective frame rate improvement, 5.83x lower power, and 9.78x better energy efficiency, without much accuracy drop.
Fairness Reprogramming
Sep 21, 2022
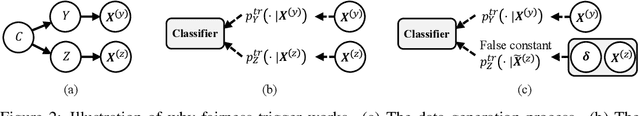
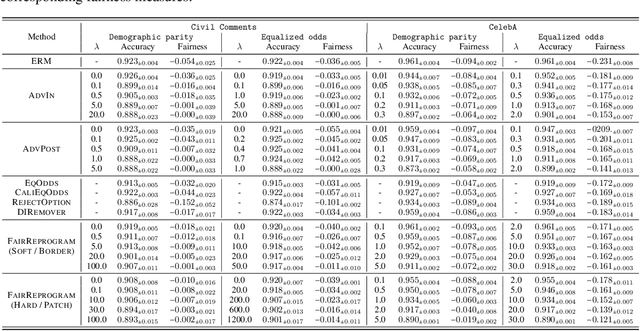
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022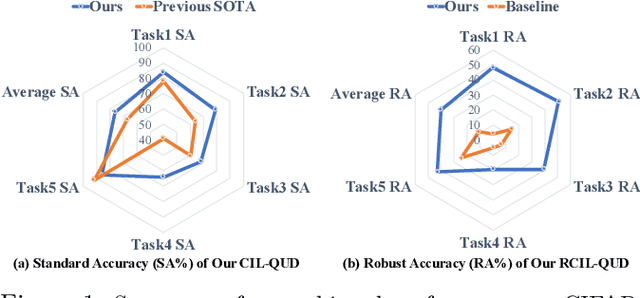
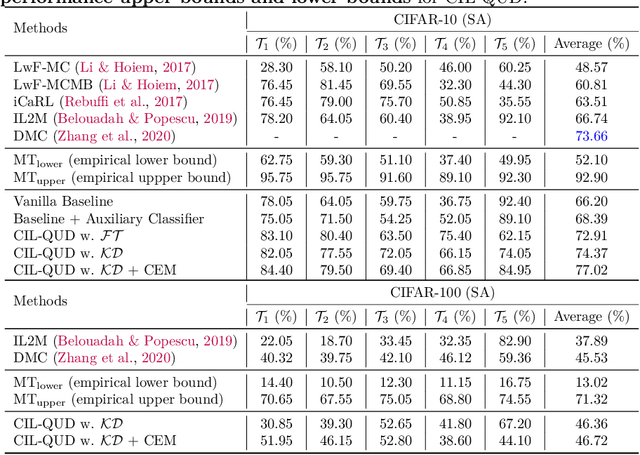
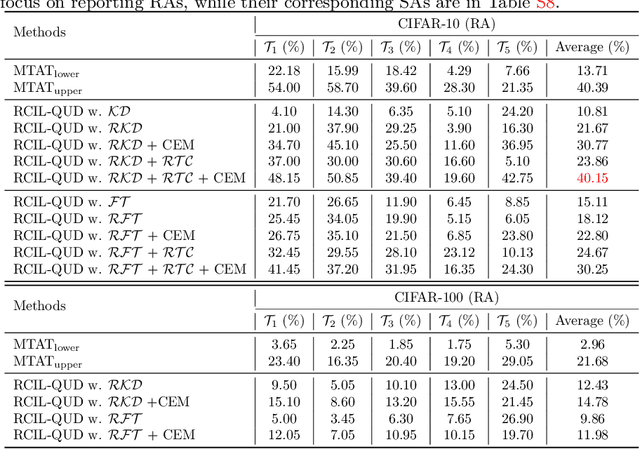
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.
Linearity Grafting: Relaxed Neuron Pruning Helps Certifiable Robustness
Jun 15, 2022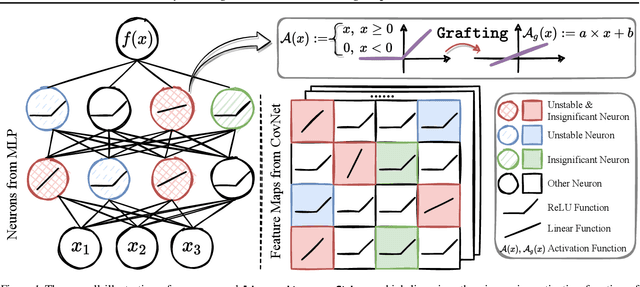
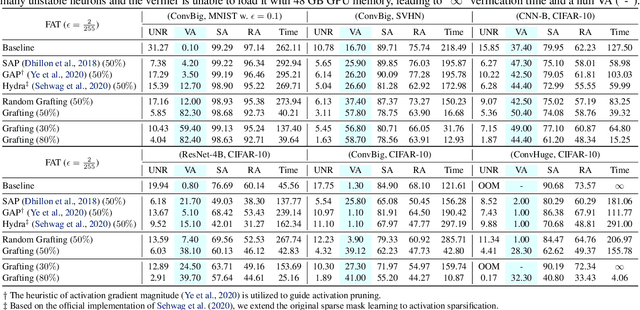
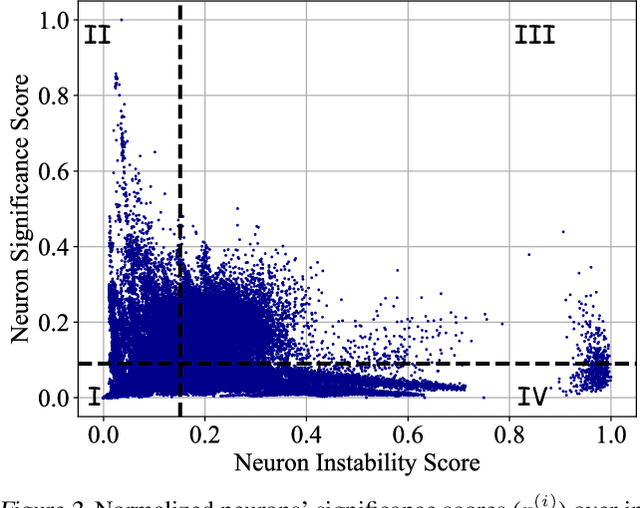
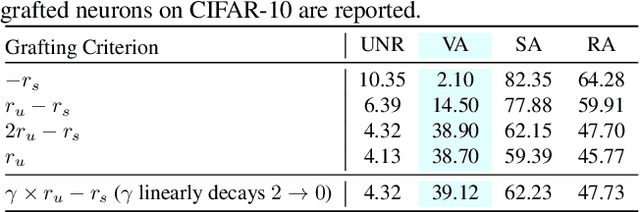
Certifiable robustness is a highly desirable property for adopting deep neural networks (DNNs) in safety-critical scenarios, but often demands tedious computations to establish. The main hurdle lies in the massive amount of non-linearity in large DNNs. To trade off the DNN expressiveness (which calls for more non-linearity) and robustness certification scalability (which prefers more linearity), we propose a novel solution to strategically manipulate neurons, by "grafting" appropriate levels of linearity. The core of our proposal is to first linearize insignificant ReLU neurons, to eliminate the non-linear components that are both redundant for DNN performance and harmful to its certification. We then optimize the associated slopes and intercepts of the replaced linear activations for restoring model performance while maintaining certifiability. Hence, typical neuron pruning could be viewed as a special case of grafting a linear function of the fixed zero slopes and intercept, that might overly restrict the network flexibility and sacrifice its performance. Extensive experiments on multiple datasets and network backbones show that our linearity grafting can (1) effectively tighten certified bounds; (2) achieve competitive certifiable robustness without certified robust training (i.e., over 30% improvements on CIFAR-10 models); and (3) scale up complete verification to large adversarially trained models with 17M parameters. Codes are available at https://github.com/VITA-Group/Linearity-Grafting.
Data-Efficient Double-Win Lottery Tickets from Robust Pre-training
Jun 09, 2022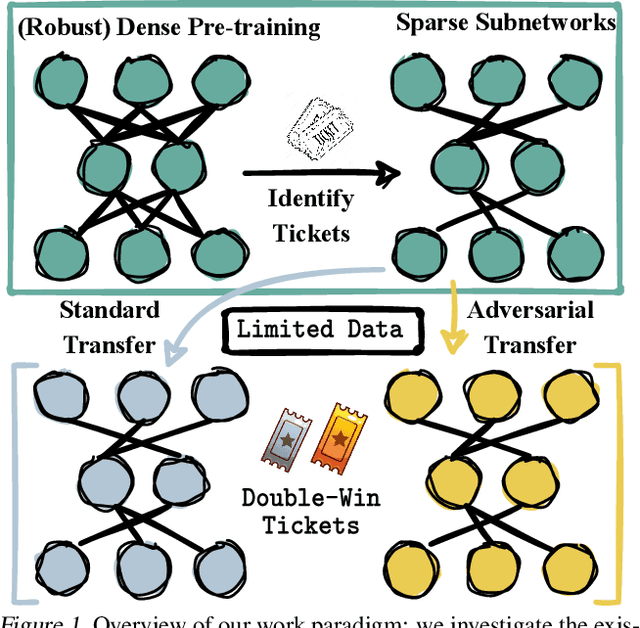
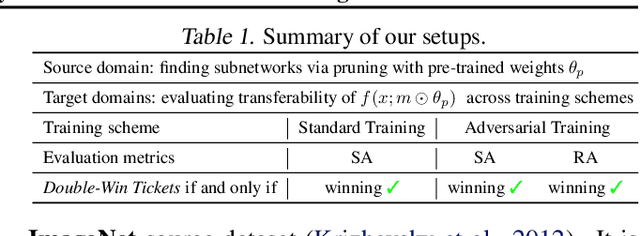

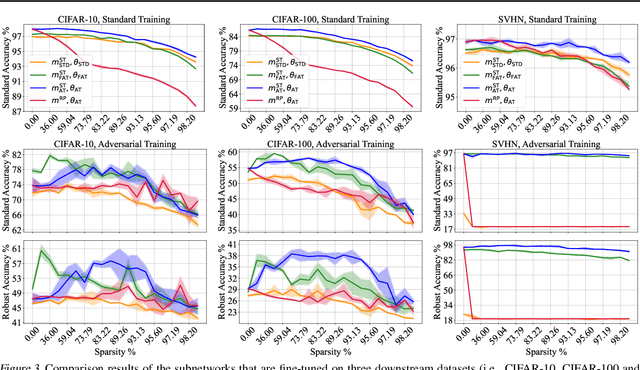
Pre-training serves as a broadly adopted starting point for transfer learning on various downstream tasks. Recent investigations of lottery tickets hypothesis (LTH) demonstrate such enormous pre-trained models can be replaced by extremely sparse subnetworks (a.k.a. matching subnetworks) without sacrificing transferability. However, practical security-crucial applications usually pose more challenging requirements beyond standard transfer, which also demand these subnetworks to overcome adversarial vulnerability. In this paper, we formulate a more rigorous concept, Double-Win Lottery Tickets, in which a located subnetwork from a pre-trained model can be independently transferred on diverse downstream tasks, to reach BOTH the same standard and robust generalization, under BOTH standard and adversarial training regimes, as the full pre-trained model can do. We comprehensively examine various pre-training mechanisms and find that robust pre-training tends to craft sparser double-win lottery tickets with superior performance over the standard counterparts. For example, on downstream CIFAR-10/100 datasets, we identify double-win matching subnetworks with the standard, fast adversarial, and adversarial pre-training from ImageNet, at 89.26%/73.79%, 89.26%/79.03%, and 91.41%/83.22% sparsity, respectively. Furthermore, we observe the obtained double-win lottery tickets can be more data-efficient to transfer, under practical data-limited (e.g., 1% and 10%) downstream schemes. Our results show that the benefits from robust pre-training are amplified by the lottery ticket scheme, as well as the data-limited transfer setting. Codes are available at https://github.com/VITA-Group/Double-Win-LTH.
Quarantine: Sparsity Can Uncover the Trojan Attack Trigger for Free
May 24, 2022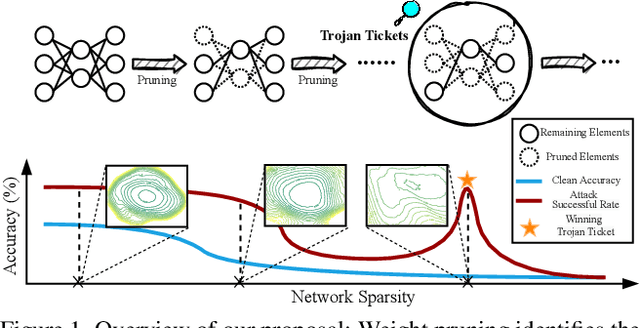

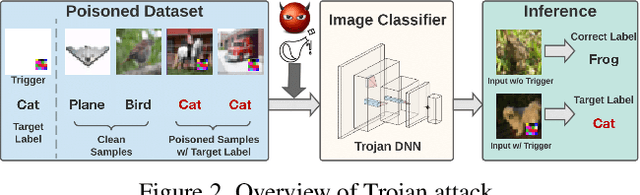

Trojan attacks threaten deep neural networks (DNNs) by poisoning them to behave normally on most samples, yet to produce manipulated results for inputs attached with a particular trigger. Several works attempt to detect whether a given DNN has been injected with a specific trigger during the training. In a parallel line of research, the lottery ticket hypothesis reveals the existence of sparse subnetworks which are capable of reaching competitive performance as the dense network after independent training. Connecting these two dots, we investigate the problem of Trojan DNN detection from the brand new lens of sparsity, even when no clean training data is available. Our crucial observation is that the Trojan features are significantly more stable to network pruning than benign features. Leveraging that, we propose a novel Trojan network detection regime: first locating a "winning Trojan lottery ticket" which preserves nearly full Trojan information yet only chance-level performance on clean inputs; then recovering the trigger embedded in this already isolated subnetwork. Extensive experiments on various datasets, i.e., CIFAR-10, CIFAR-100, and ImageNet, with different network architectures, i.e., VGG-16, ResNet-18, ResNet-20s, and DenseNet-100 demonstrate the effectiveness of our proposal. Codes are available at https://github.com/VITA-Group/Backdoor-LTH.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
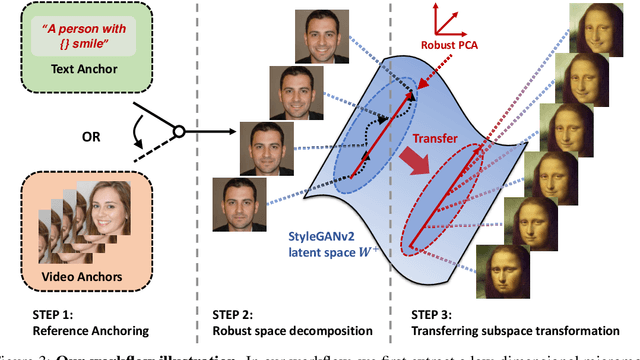


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.