 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution
May 07, 2019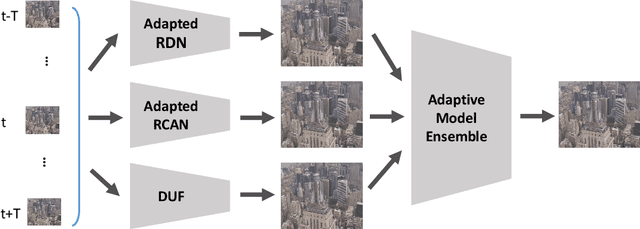
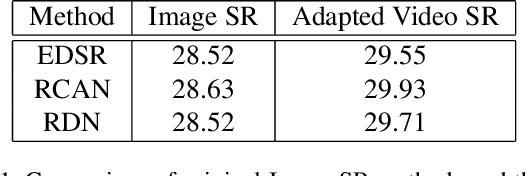
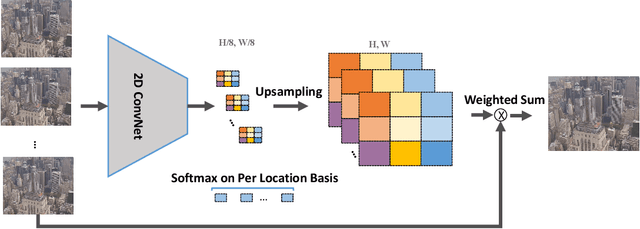
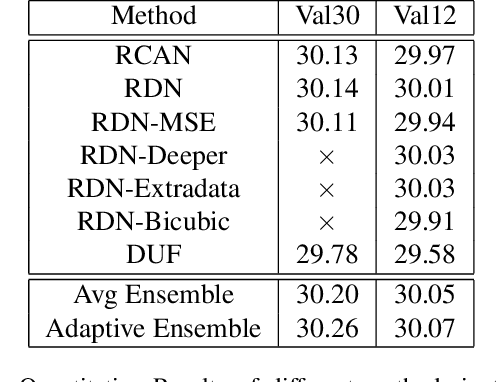
Recently, image super-resolution has been widely studied and achieved significant progress by leveraging the power of deep convolutional neural networks. However, there has been limited advancement in video super-resolution (VSR) due to the complex temporal patterns in videos. In this paper, we investigate how to adapt state-of-the-art methods of image super-resolution for video super-resolution. The proposed adapting method is straightforward. The information among successive frames is well exploited, while the overhead on the original image super-resolution method is negligible. Furthermore, we propose a learning-based method to ensemble the outputs from multiple super-resolution models. Our methods show superior performance and rank second in the NTIRE2019 Video Super-Resolution Challenge Track 1.
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
Apr 22, 2019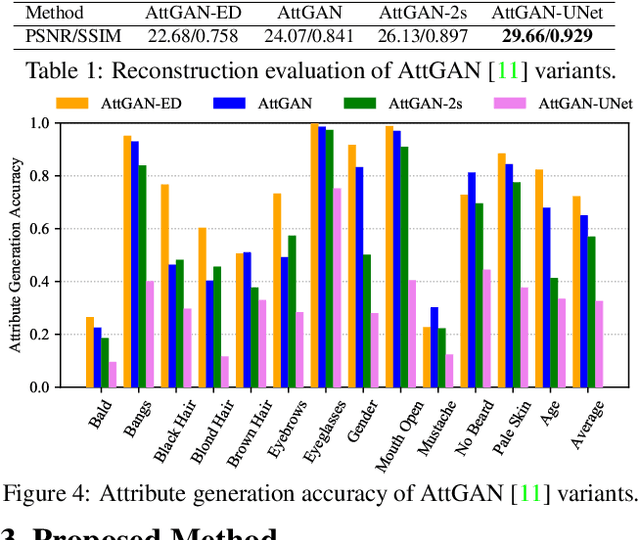



Arbitrary attribute editing generally can be tackled by incorporating encoder-decoder and generative adversarial networks. However, the bottleneck layer in encoder-decoder usually gives rise to blurry and low quality editing result. And adding skip connections improves image quality at the cost of weakened attribute manipulation ability. Moreover, existing methods exploit target attribute vector to guide the flexible translation to desired target domain. In this work, we suggest to address these issues from selective transfer perspective. Considering that specific editing task is certainly only related to the changed attributes instead of all target attributes, our model selectively takes the difference between target and source attribute vectors as input. Furthermore, selective transfer units are incorporated with encoder-decoder to adaptively select and modify encoder feature for enhanced attribute editing. Experiments show that our method (i.e., STGAN) simultaneously improves attribute manipulation accuracy as well as perception quality, and performs favorably against state-of-the-arts in arbitrary facial attribute editing and season translation.
Read, Watch, and Move: Reinforcement Learning for Temporally Grounding Natural Language Descriptions in Videos
Jan 21, 2019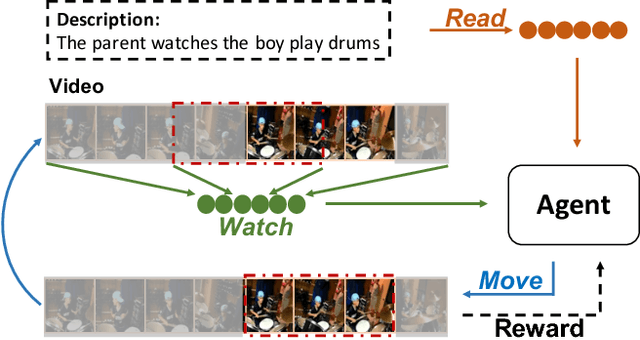
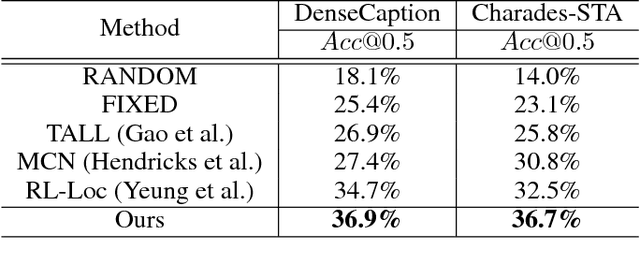
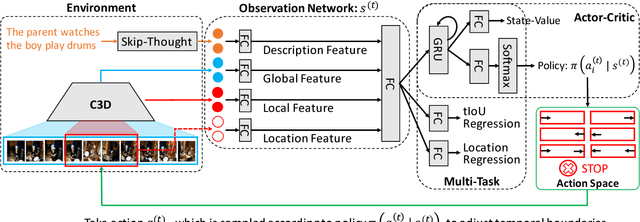
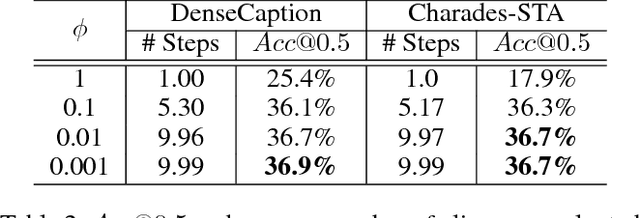
The task of video grounding, which temporally localizes a natural language description in a video, plays an important role in understanding videos. Existing studies have adopted strategies of sliding window over the entire video or exhaustively ranking all possible clip-sentence pairs in a pre-segmented video, which inevitably suffer from exhaustively enumerated candidates. To alleviate this problem, we formulate this task as a problem of sequential decision making by learning an agent which regulates the temporal grounding boundaries progressively based on its policy. Specifically, we propose a reinforcement learning based framework improved by multi-task learning and it shows steady performance gains by considering additional supervised boundary information during training. Our proposed framework achieves state-of-the-art performance on ActivityNet'18 DenseCaption dataset and Charades-STA dataset while observing only 10 or less clips per video.
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
Nov 06, 2018
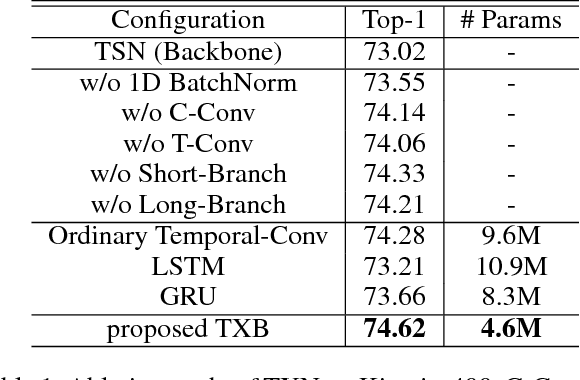
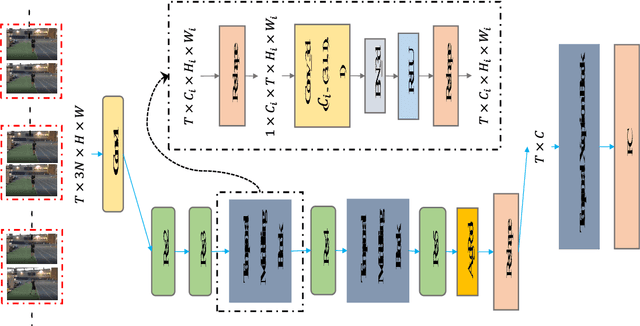
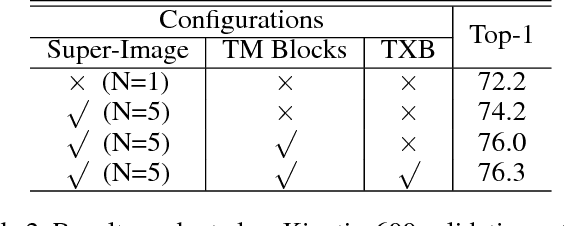
Despite the success of deep learning for static image understanding, it remains unclear what are the most effective network architectures for the spatial-temporal modeling in videos. In this paper, in contrast to the existing CNN+RNN or pure 3D convolution based approaches, we explore a novel spatial temporal network (StNet) architecture for both local and global spatial-temporal modeling in videos. Particularly, StNet stacks N successive video frames into a \emph{super-image} which has 3N channels and applies 2D convolution on super-images to capture local spatial-temporal relationship. To model global spatial-temporal relationship, we apply temporal convolution on the local spatial-temporal feature maps. Specifically, a novel temporal Xception block is proposed in StNet. It employs a separate channel-wise and temporal-wise convolution over the feature sequence of video. Extensive experiments on the Kinetics dataset demonstrate that our framework outperforms several state-of-the-art approaches in action recognition and can strike a satisfying trade-off between recognition accuracy and model complexity. We further demonstrate the generalization performance of the leaned video representations on the UCF101 dataset.
Solution for Large-Scale Hierarchical Object Detection Datasets with Incomplete Annotation and Data Imbalance
Oct 15, 2018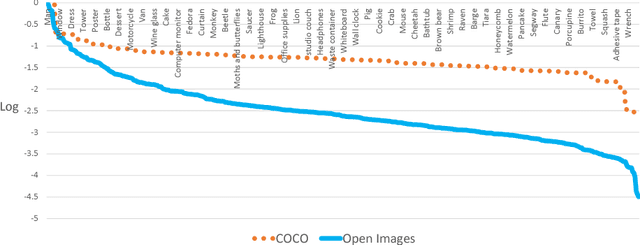


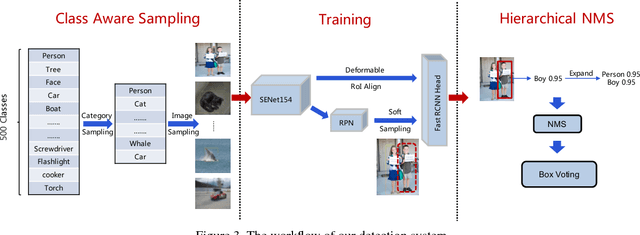
This report demonstrates our solution for the Open Images 2018 Challenge. Based on our detailed analysis on the Open Images Datasets (OID), it is found that there are four typical features: large-scale, hierarchical tag system, severe annotation incompleteness and data imbalance. Considering these characteristics, an amount of strategies are employed, including SNIPER, soft sampling, class-aware sampling (CAS), hierarchical non-maximum suppression (HNMS) and so on. In virtue of these effective strategies, and further using the powerful SENet154 armed with feature pyramid module and deformable ROIalign as the backbone, our best single model could achieve a mAP of 56.9%. After a further ensemble with 9 models, the final mAP is boosted to 62.2% in the public leaderboard (ranked the 2nd place) and 58.6% in the private leaderboard (ranked the 3rd place, slightly inferior to the 1st place by only 0.04 point).
Exploiting Spatial-Temporal Modelling and Multi-Modal Fusion for Human Action Recognition
Jun 27, 2018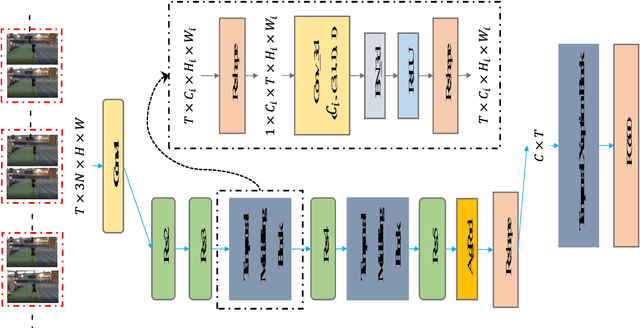

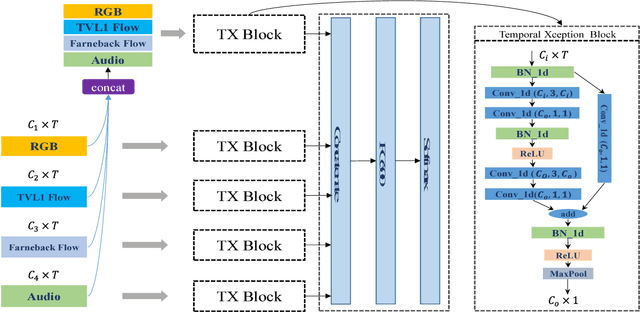

In this report, our approach to tackling the task of ActivityNet 2018 Kinetics-600 challenge is described in detail. Though spatial-temporal modelling methods, which adopt either such end-to-end framework as I3D \cite{i3d} or two-stage frameworks (i.e., CNN+RNN), have been proposed in existing state-of-the-arts for this task, video modelling is far from being well solved. In this challenge, we propose spatial-temporal network (StNet) for better joint spatial-temporal modelling and comprehensively video understanding. Besides, given that multi-modal information is contained in video source, we manage to integrate both early-fusion and later-fusion strategy of multi-modal information via our proposed improved temporal Xception network (iTXN) for video understanding. Our StNet RGB single model achieves 78.99\% top-1 precision in the Kinetics-600 validation set and that of our improved temporal Xception network which integrates RGB, flow and audio modalities is up to 82.35\%. After model ensemble, we achieve top-1 precision as high as 85.0\% on the validation set and rank No.1 among all submissions.
Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification
Nov 27, 2017
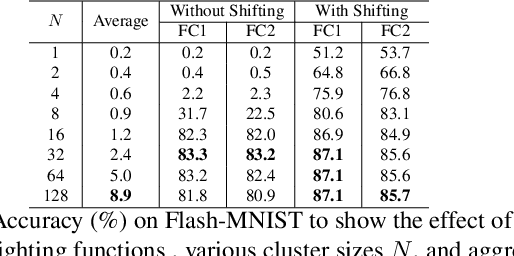
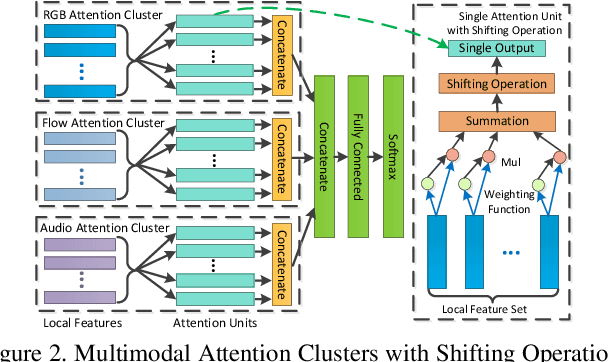
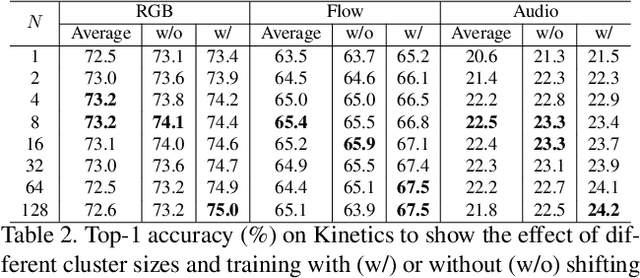
Recently, substantial research effort has focused on how to apply CNNs or RNNs to better extract temporal patterns from videos, so as to improve the accuracy of video classification. In this paper, however, we show that temporal information, especially longer-term patterns, may not be necessary to achieve competitive results on common video classification datasets. We investigate the potential of a purely attention based local feature integration. Accounting for the characteristics of such features in video classification, we propose a local feature integration framework based on attention clusters, and introduce a shifting operation to capture more diverse signals. We carefully analyze and compare the effect of different attention mechanisms, cluster sizes, and the use of the shifting operation, and also investigate the combination of attention clusters for multimodal integration. We demonstrate the effectiveness of our framework on three real-world video classification datasets. Our model achieves competitive results across all of these. In particular, on the large-scale Kinetics dataset, our framework obtains an excellent single model accuracy of 79.4% in terms of the top-1 and 94.0% in terms of the top-5 accuracy on the validation set. The attention clusters are the backbone of our winner solution at ActivityNet Kinetics Challenge 2017. Code and models will be released soon.
Dynamic Computational Time for Visual Attention
Sep 07, 2017
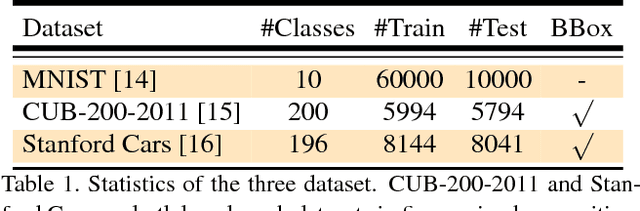
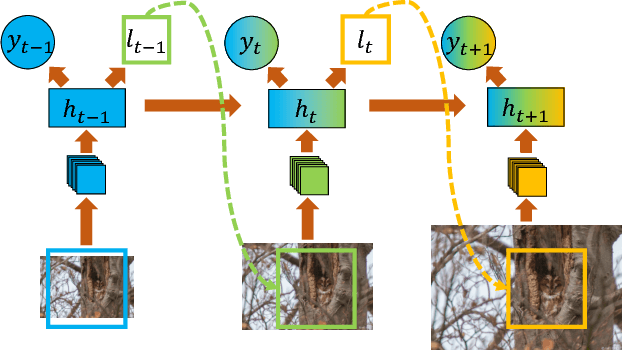

We propose a dynamic computational time model to accelerate the average processing time for recurrent visual attention (RAM). Rather than attention with a fixed number of steps for each input image, the model learns to decide when to stop on the fly. To achieve this, we add an additional continue/stop action per time step to RAM and use reinforcement learning to learn both the optimal attention policy and stopping policy. The modification is simple but could dramatically save the average computational time while keeping the same recognition performance as RAM. Experimental results on CUB-200-2011 and Stanford Cars dataset demonstrate the dynamic computational model can work effectively for fine-grained image recognition.The source code of this paper can be obtained from https://github.com/baidu-research/DT-RAM
Revisiting the Effectiveness of Off-the-shelf Temporal Modeling Approaches for Large-scale Video Classification
Aug 12, 2017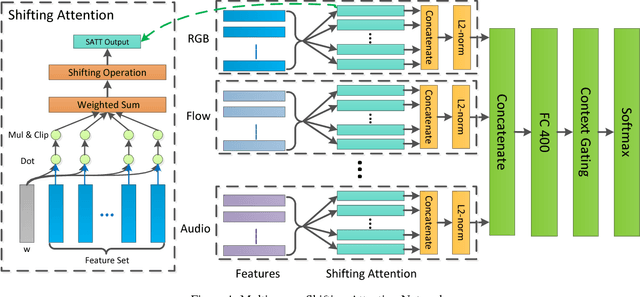
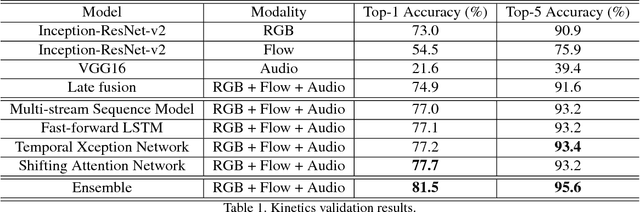
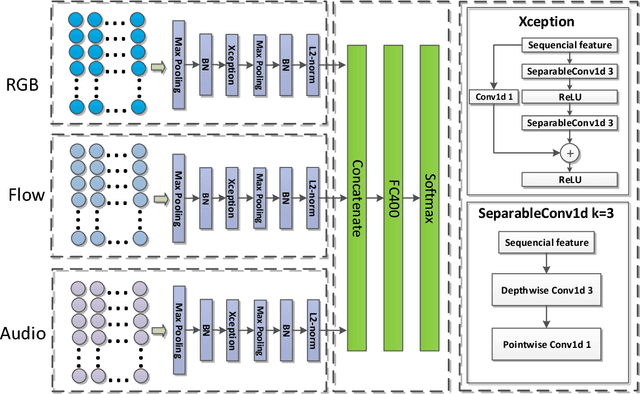
This paper describes our solution for the video recognition task of ActivityNet Kinetics challenge that ranked the 1st place. Most of existing state-of-the-art video recognition approaches are in favor of an end-to-end pipeline. One exception is the framework of DevNet. The merit of DevNet is that they first use the video data to learn a network (i.e. fine-tuning or training from scratch). Instead of directly using the end-to-end classification scores (e.g. softmax scores), they extract the features from the learned network and then fed them into the off-the-shelf machine learning models to conduct video classification. However, the effectiveness of this line work has long-term been ignored and underestimated. In this submission, we extensively use this strategy. Particularly, we investigate four temporal modeling approaches using the learned features: Multi-group Shifting Attention Network, Temporal Xception Network, Multi-stream sequence Model and Fast-Forward Sequence Model. Experiment results on the challenging Kinetics dataset demonstrate that our proposed temporal modeling approaches can significantly improve existing approaches in the large-scale video recognition tasks. Most remarkably, our best single Multi-group Shifting Attention Network can achieve 77.7% in term of top-1 accuracy and 93.2% in term of top-5 accuracy on the validation set.
Deep Metric Learning with Angular Loss
Aug 04, 2017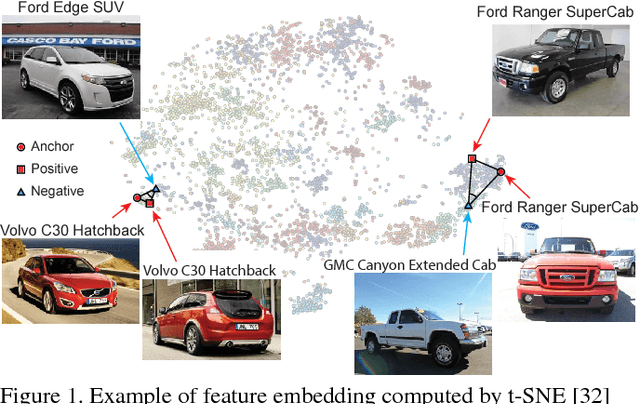
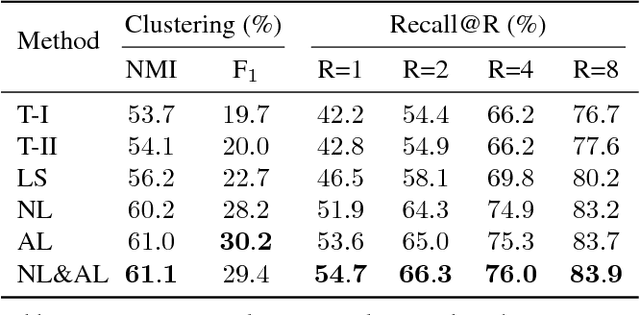
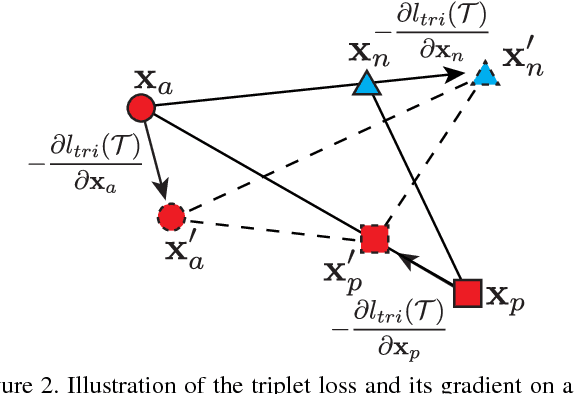
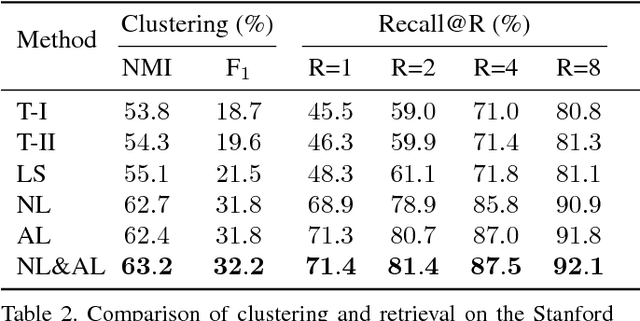
The modern image search system requires semantic understanding of image, and a key yet under-addressed problem is to learn a good metric for measuring the similarity between images. While deep metric learning has yielded impressive performance gains by extracting high level abstractions from image data, a proper objective loss function becomes the central issue to boost the performance. In this paper, we propose a novel angular loss, which takes angle relationship into account, for learning better similarity metric. Whereas previous metric learning methods focus on optimizing the similarity (contrastive loss) or relative similarity (triplet loss) of image pairs, our proposed method aims at constraining the angle at the negative point of triplet triangles. Several favorable properties are observed when compared with conventional methods. First, scale invariance is introduced, improving the robustness of objective against feature variance. Second, a third-order geometric constraint is inherently imposed, capturing additional local structure of triplet triangles than contrastive loss or triplet loss. Third, better convergence has been demonstrated by experiments on three publicly available datasets.