 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
Jul 20, 2022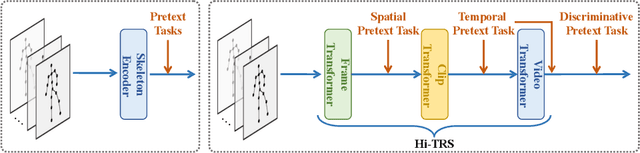
Despite the success of fully-supervised human skeleton sequence modeling, utilizing self-supervised pre-training for skeleton sequence representation learning has been an active field because acquiring task-specific skeleton annotations at large scales is difficult. Recent studies focus on learning video-level temporal and discriminative information using contrastive learning, but overlook the hierarchical spatial-temporal nature of human skeletons. Different from such superficial supervision at the video level, we propose a self-supervised hierarchical pre-training scheme incorporated into a hierarchical Transformer-based skeleton sequence encoder (Hi-TRS), to explicitly capture spatial, short-term, and long-term temporal dependencies at frame, clip, and video levels, respectively. To evaluate the proposed self-supervised pre-training scheme with Hi-TRS, we conduct extensive experiments covering three skeleton-based downstream tasks including action recognition, action detection, and motion prediction. Under both supervised and semi-supervised evaluation protocols, our method achieves the state-of-the-art performance. Additionally, we demonstrate that the prior knowledge learned by our model in the pre-training stage has strong transfer capability for different downstream tasks.
Explainable Fairness in Recommendation
Apr 24, 2022
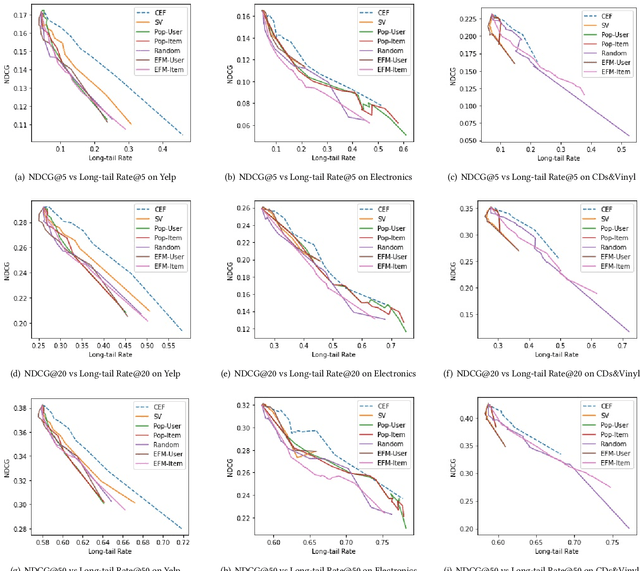
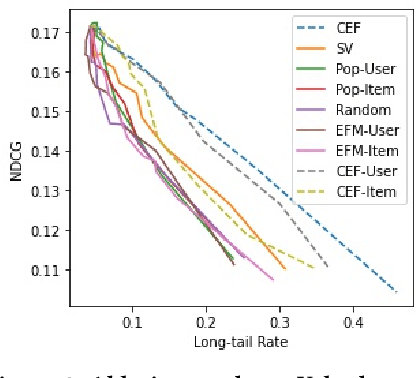
Existing research on fairness-aware recommendation has mainly focused on the quantification of fairness and the development of fair recommendation models, neither of which studies a more substantial problem--identifying the underlying reason of model disparity in recommendation. This information is critical for recommender system designers to understand the intrinsic recommendation mechanism and provides insights on how to improve model fairness to decision makers. Fortunately, with the rapid development of Explainable AI, we can use model explainability to gain insights into model (un)fairness. In this paper, we study the problem of explainable fairness, which helps to gain insights about why a system is fair or unfair, and guides the design of fair recommender systems with a more informed and unified methodology. Particularly, we focus on a common setting with feature-aware recommendation and exposure unfairness, but the proposed explainable fairness framework is general and can be applied to other recommendation settings and fairness definitions. We propose a Counterfactual Explainable Fairness framework, called CEF, which generates explanations about model fairness that can improve the fairness without significantly hurting the performance.The CEF framework formulates an optimization problem to learn the "minimal" change of the input features that changes the recommendation results to a certain level of fairness. Based on the counterfactual recommendation result of each feature, we calculate an explainability score in terms of the fairness-utility trade-off to rank all the feature-based explanations, and select the top ones as fairness explanations.
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
Apr 06, 2022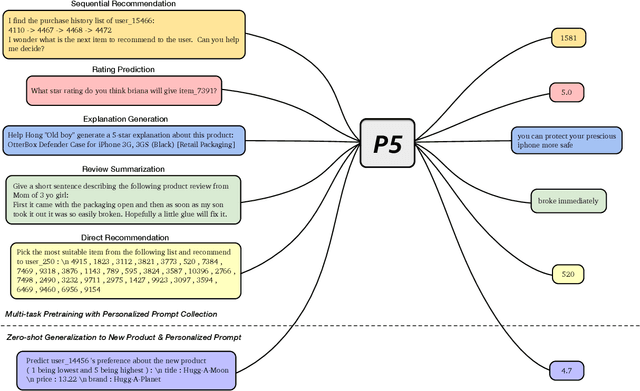
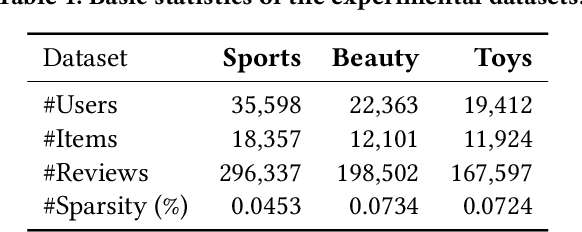
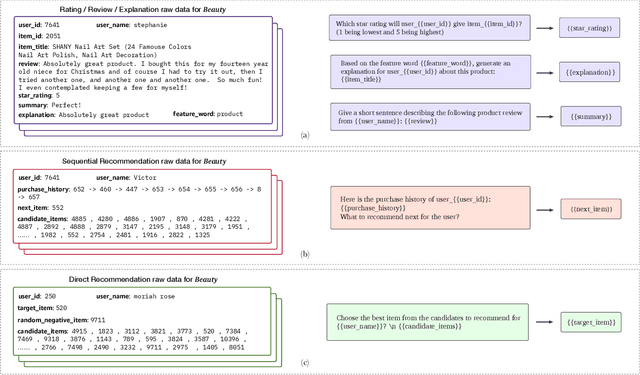
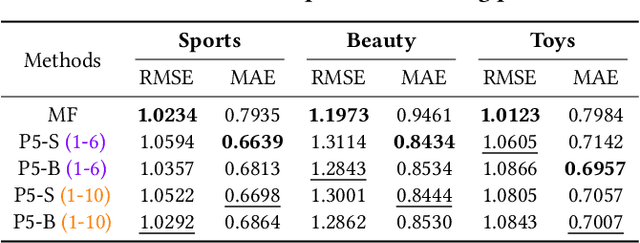
For a long period, different recommendation tasks typically require designing task-specific architectures and training objectives. As a result, it is hard to transfer the learned knowledge and representations from one task to another, thus restricting the generalization ability of existing recommendation approaches, e.g., a sequential recommendation model can hardly be applied or transferred to a review generation method. To deal with such issues, considering that language grounding is a powerful medium to describe and represent various problems or tasks, we present a flexible and unified text-to-text paradigm called "Pretrain, Personalized Prompt, and Predict Paradigm" (P5) for recommendation, which unifies various recommendation tasks in a shared framework. In P5, all data such as user-item interactions, item metadata, and user reviews are converted to a common format -- natural language sequences. The rich information from natural language assist P5 to capture deeper semantics for recommendation. P5 learns different tasks with the same language modeling objective during pretraining. Thus, it possesses the potential to serve as the foundation model for downstream recommendation tasks, allows easy integration with other modalities, and enables instruction-based recommendation, which will revolutionize the technical form of recommender system towards universal recommendation engine. With adaptive personalized prompt for different users, P5 is able to make predictions in a zero-shot or few-shot manner and largely reduces the necessity for extensive fine-tuning. On several recommendation benchmarks, we conduct experiments to show the effectiveness of our generative approach. We will release our prompts and pretrained P5 language model to help advance future research on Recommendation as Language Processing (RLP) and Personalized Foundation Models.
Learning and Evaluating Graph Neural Network Explanations based on Counterfactual and Factual Reasoning
Feb 17, 2022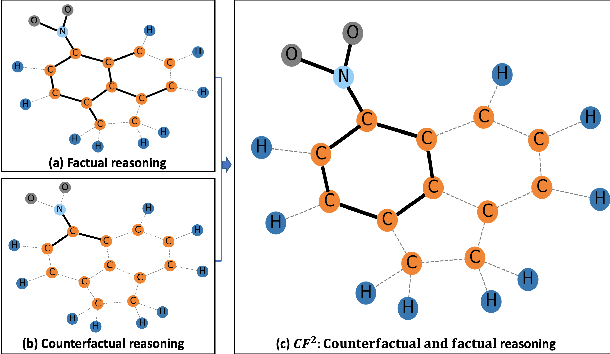
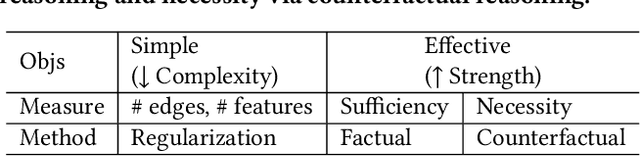

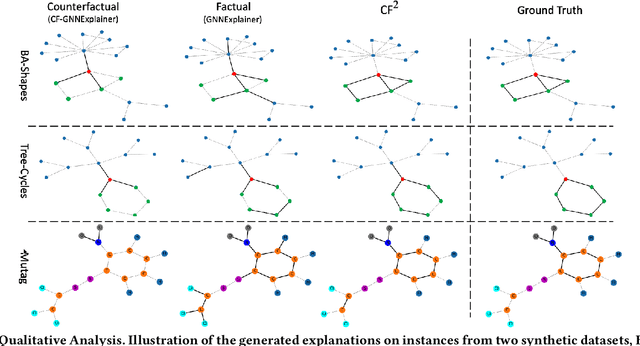
Structural data well exists in Web applications, such as social networks in social media, citation networks in academic websites, and threads data in online forums. Due to the complex topology, it is difficult to process and make use of the rich information within such data. Graph Neural Networks (GNNs) have shown great advantages on learning representations for structural data. However, the non-transparency of the deep learning models makes it non-trivial to explain and interpret the predictions made by GNNs. Meanwhile, it is also a big challenge to evaluate the GNN explanations, since in many cases, the ground-truth explanations are unavailable. In this paper, we take insights of Counterfactual and Factual (CF^2) reasoning from causal inference theory, to solve both the learning and evaluation problems in explainable GNNs. For generating explanations, we propose a model-agnostic framework by formulating an optimization problem based on both of the two casual perspectives. This distinguishes CF^2 from previous explainable GNNs that only consider one of them. Another contribution of the work is the evaluation of GNN explanations. For quantitatively evaluating the generated explanations without the requirement of ground-truth, we design metrics based on Counterfactual and Factual reasoning to evaluate the necessity and sufficiency of the explanations. Experiments show that no matter ground-truth explanations are available or not, CF^2 generates better explanations than previous state-of-the-art methods on real-world datasets. Moreover, the statistic analysis justifies the correlation between the performance on ground-truth evaluation and our proposed metrics.
COMPOSER: Compositional Learning of Group Activity in Videos
Dec 11, 2021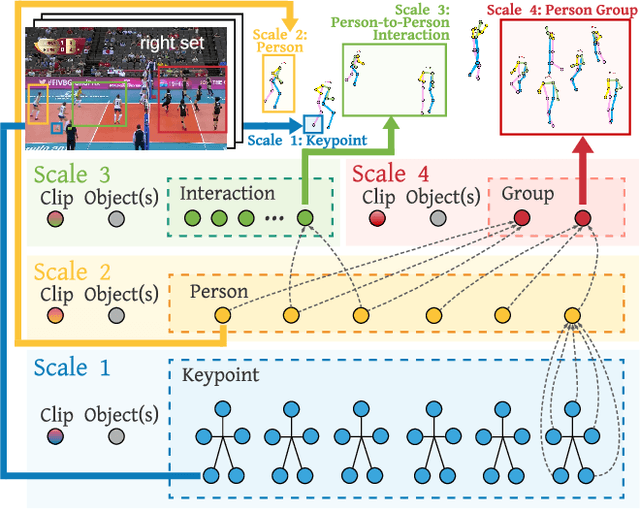

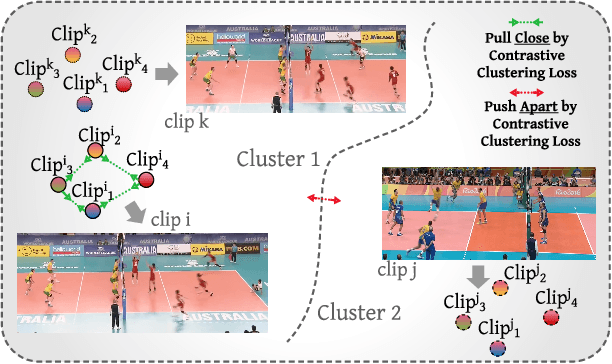
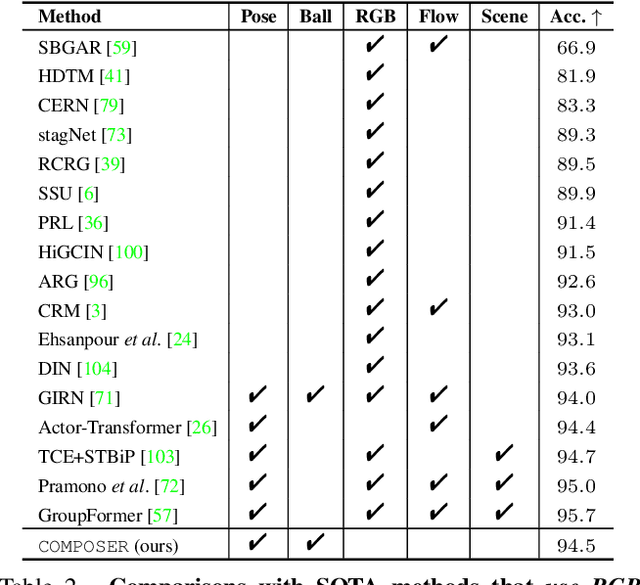
Group Activity Recognition (GAR) detects the activity performed by a group of actors in a short video clip. The task requires the compositional understanding of scene entities and relational reasoning between them. We approach GAR by modeling the video as a series of tokens that represent the multi-scale semantic concepts in the video. We propose COMPOSER, a Multiscale Transformer based architecture that performs attention-based reasoning over tokens at each scale and learns group activity compositionally. In addition, we only use the keypoint modality which reduces scene biases and improves the generalization ability of the model. We improve the multi-scale representations in COMPOSER by clustering the intermediate scale representations, while maintaining consistent cluster assignments between scales. Finally, we use techniques such as auxiliary prediction and novel data augmentations (e.g., Actor Dropout) to aid model training. We demonstrate the model's strength and interpretability on the challenging Volleyball dataset. COMPOSER achieves a new state-of-the-art 94.5% accuracy with the keypoint-only modality. COMPOSER outperforms the latest GAR methods that rely on RGB signals, and performs favorably compared against methods that exploit multiple modalities. Our code will be available.
A Simple Long-Tailed Recognition Baseline via Vision-Language Model
Nov 29, 2021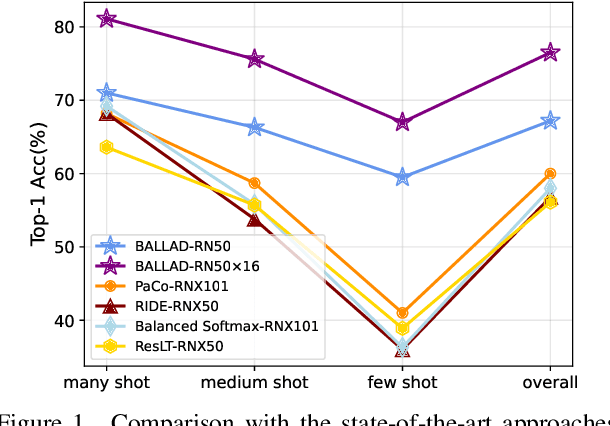
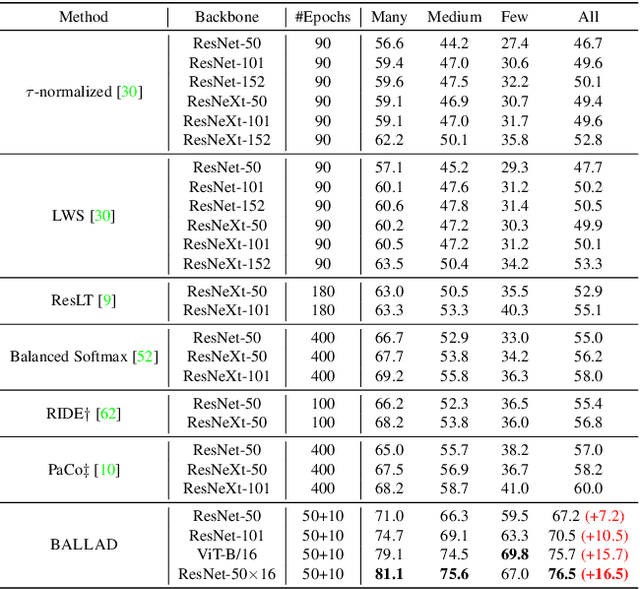
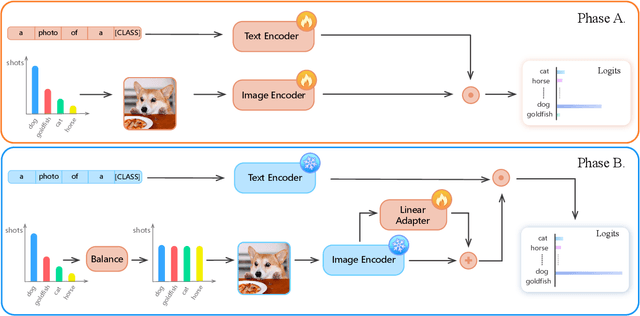
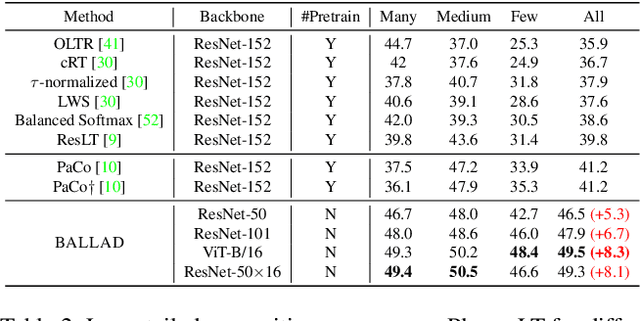
The visual world naturally exhibits a long-tailed distribution of open classes, which poses great challenges to modern visual systems. Existing approaches either perform class re-balancing strategies or directly improve network modules to address the problem. However, they still train models with a finite set of predefined labels, limiting their supervision information and restricting their transferability to novel instances. Recent advances in large-scale contrastive visual-language pretraining shed light on a new pathway for visual recognition. With open-vocabulary supervisions, pretrained contrastive vision-language models learn powerful multimodal representations that are promising to handle data deficiency and unseen concepts. By calculating the semantic similarity between visual and text inputs, visual recognition is converted to a vision-language matching problem. Inspired by this, we propose BALLAD to leverage contrastive vision-language models for long-tailed recognition. We first continue pretraining the vision-language backbone through contrastive learning on a specific long-tailed target dataset. Afterward, we freeze the backbone and further employ an additional adapter layer to enhance the representations of tail classes on balanced training samples built with re-sampling strategies. Extensive experiments have been conducted on three popular long-tailed recognition benchmarks. As a result, our simple and effective approach sets the new state-of-the-art performances and outperforms competitive baselines with a large margin. Code is released at https://github.com/gaopengcuhk/BALLAD.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021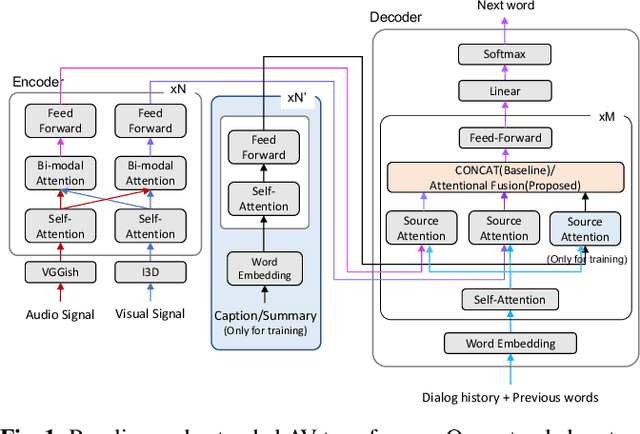
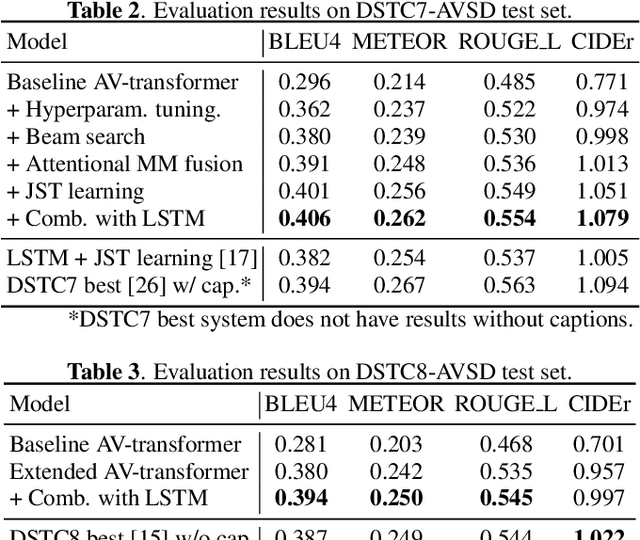
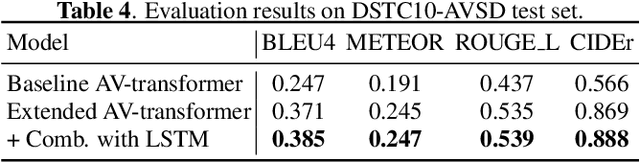
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
CLIP-Adapter: Better Vision-Language Models with Feature Adapters
Oct 09, 2021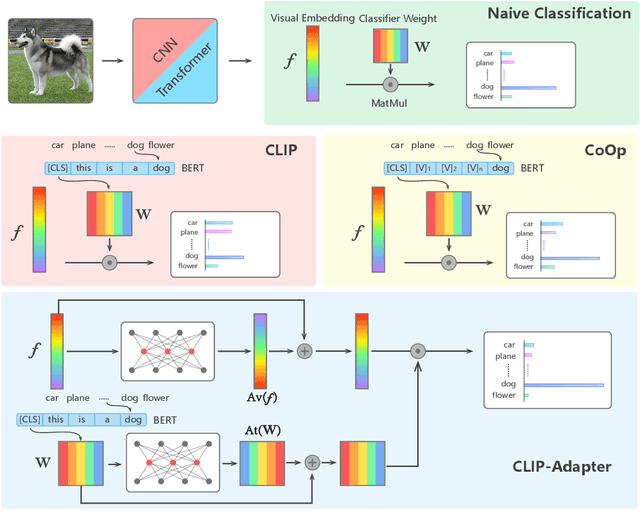
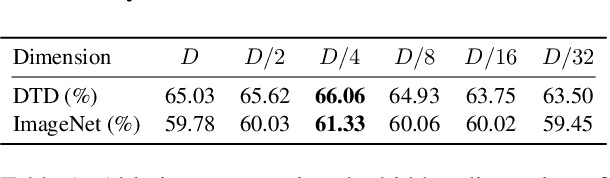
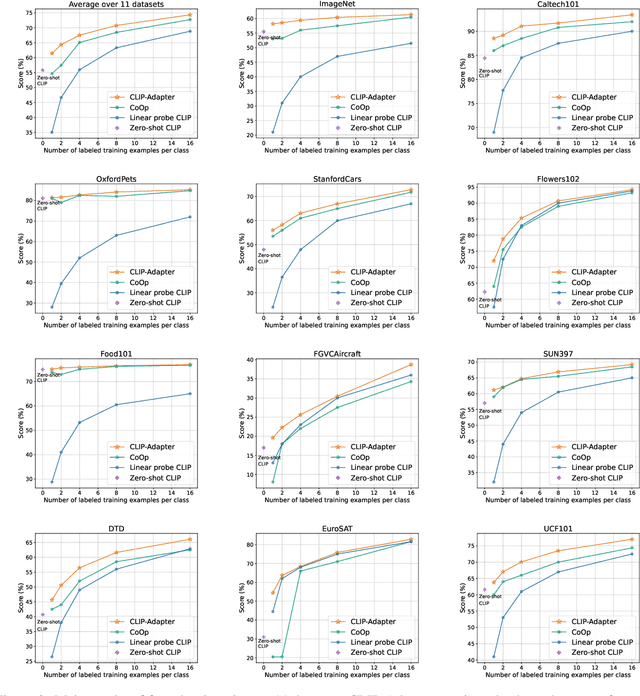
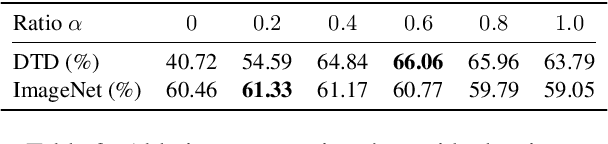
Large-scale contrastive vision-language pre-training has shown significant progress in visual representation learning. Unlike traditional visual systems trained by a fixed set of discrete labels, a new paradigm was introduced in \cite{radford2021learning} to directly learn to align images with raw texts in an open-vocabulary setting. On downstream tasks, a carefully chosen text prompt is employed to make zero-shot predictions.~To avoid non-trivial prompt engineering, context optimization \cite{zhou2021coop} has been proposed to learn continuous vectors as task-specific prompts with few-shot training examples.~In this paper, we show that there is an alternative path to achieve better vision-language models other than prompt tuning.~While prompt tuning is for the textual inputs, we propose CLIP-Adapter to conduct fine-tuning with feature adapters on either visual or language branch. Specifically, CLIP-Adapter adopts an additional bottleneck layer to learn new features and performs residual-style feature blending with the original pre-trained features.~As a consequence, CLIP-Adapter is able to outperform context optimization while maintains a simple design. Experiments and extensive ablation studies on various visual classification tasks demonstrate the effectiveness of our approach.
Dense Contrastive Visual-Linguistic Pretraining
Sep 24, 2021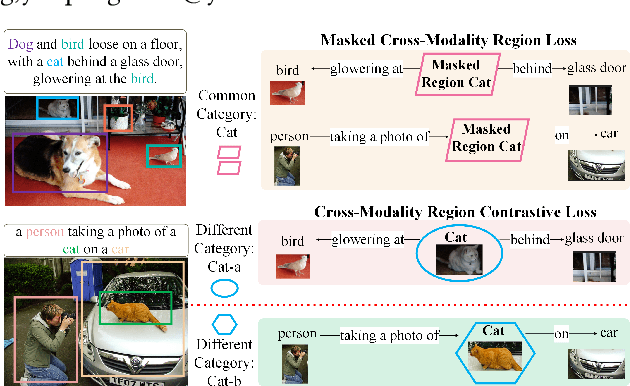

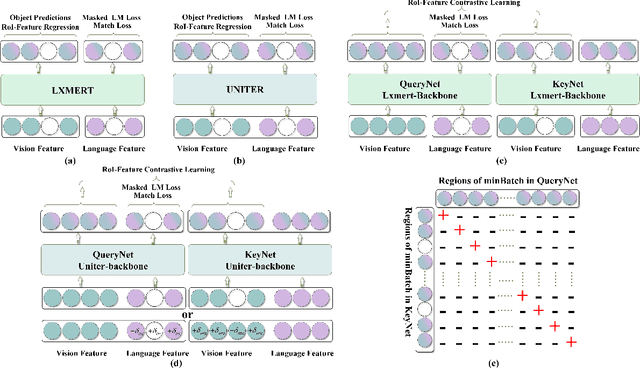
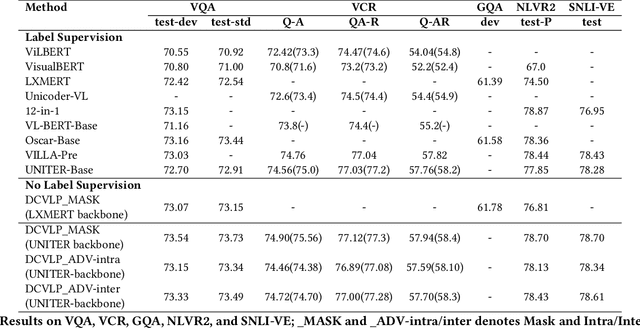
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.
Counterfactual Evaluation for Explainable AI
Sep 05, 2021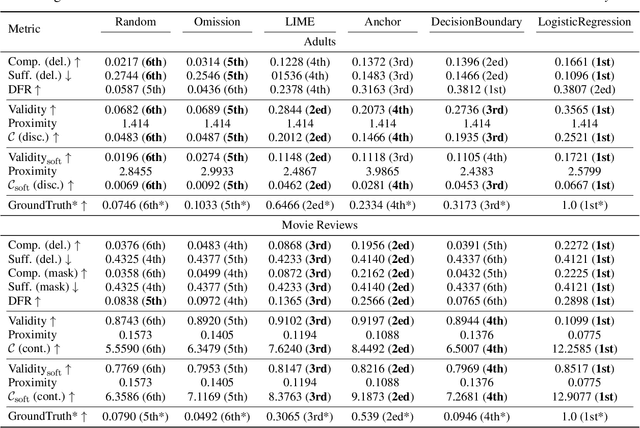
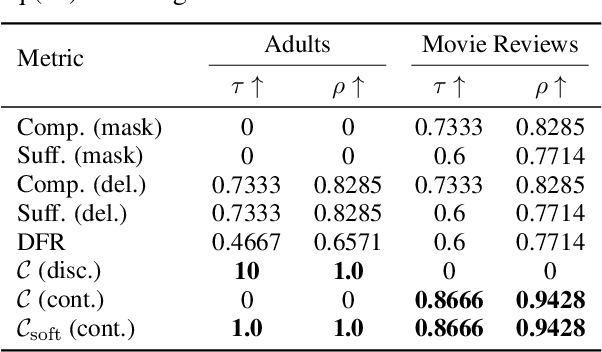
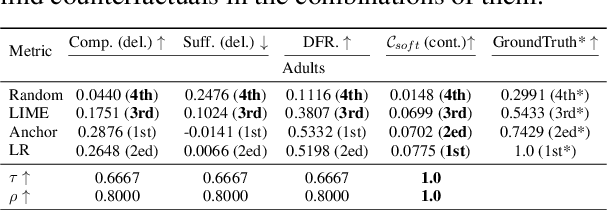
While recent years have witnessed the emergence of various explainable methods in machine learning, to what degree the explanations really represent the reasoning process behind the model prediction -- namely, the faithfulness of explanation -- is still an open problem. One commonly used way to measure faithfulness is \textit{erasure-based} criteria. Though conceptually simple, erasure-based criterion could inevitably introduce biases and artifacts. We propose a new methodology to evaluate the faithfulness of explanations from the \textit{counterfactual reasoning} perspective: the model should produce substantially different outputs for the original input and its corresponding counterfactual edited on a faithful feature. Specially, we introduce two algorithms to find the proper counterfactuals in both discrete and continuous scenarios and then use the acquired counterfactuals to measure faithfulness. Empirical results on several datasets show that compared with existing metrics, our proposed counterfactual evaluation method can achieve top correlation with the ground truth under diffe