 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Object Detection Using Captions
Nov 20, 2020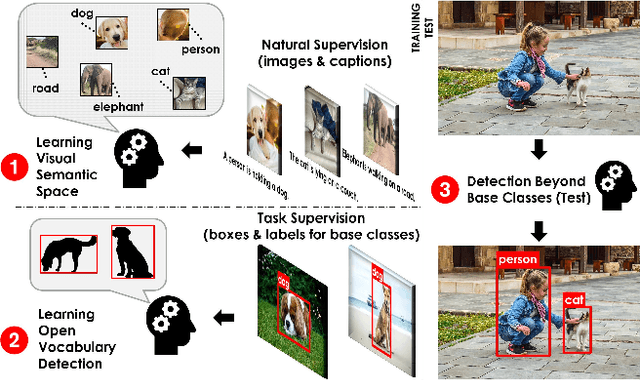
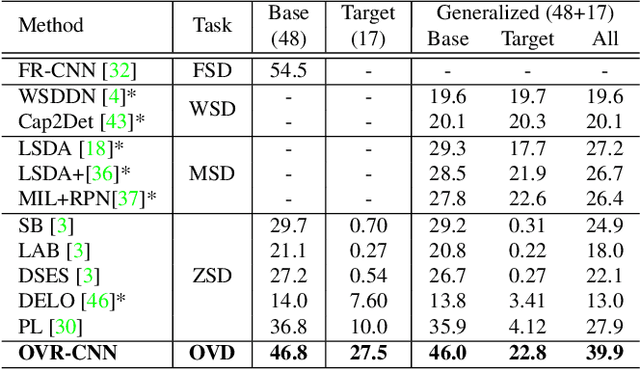
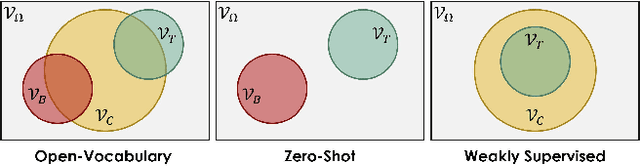
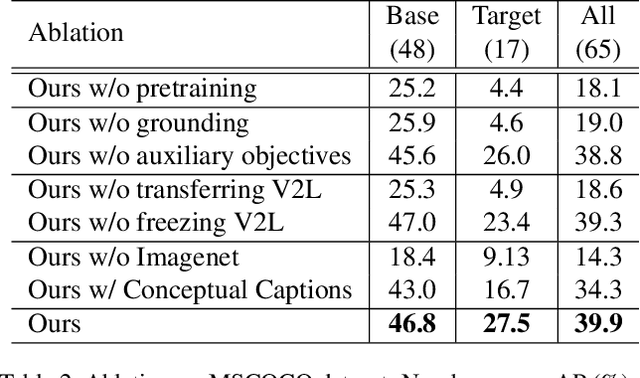
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Nov 18, 2020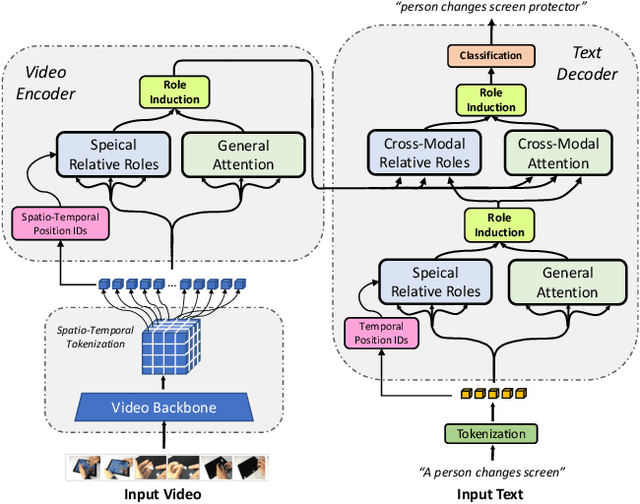
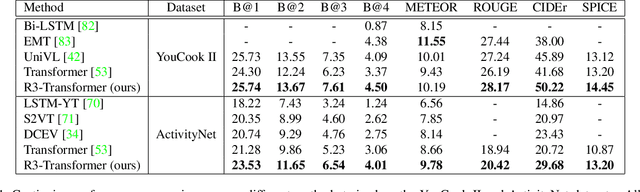
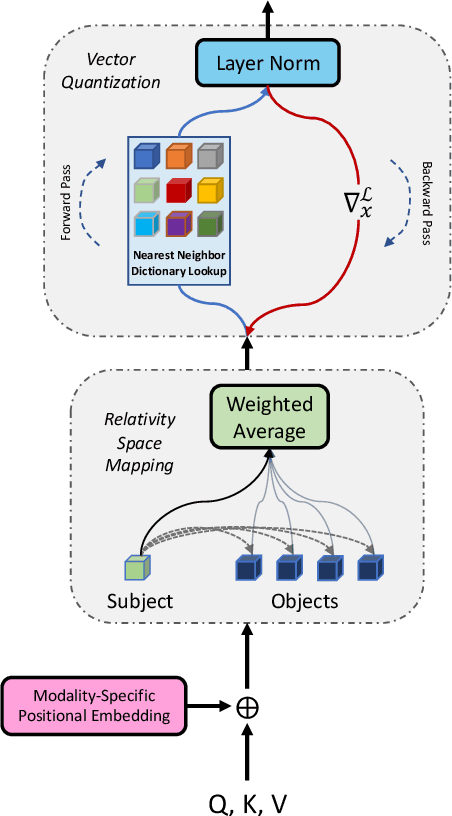
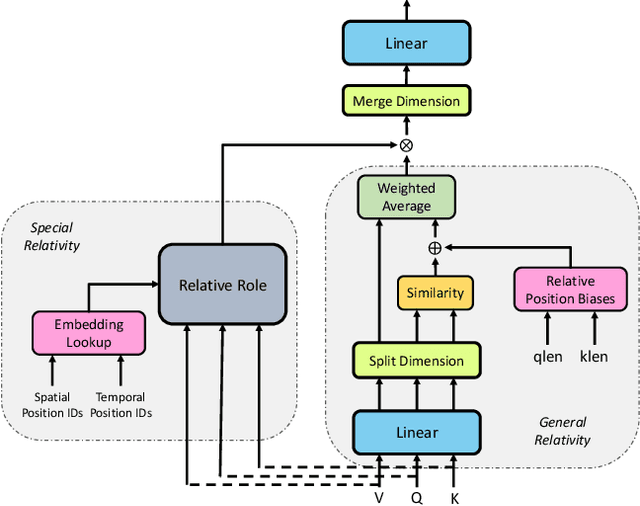
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer
Weakly-supervised VisualBERT: Pre-training without Parallel Images and Captions
Oct 24, 2020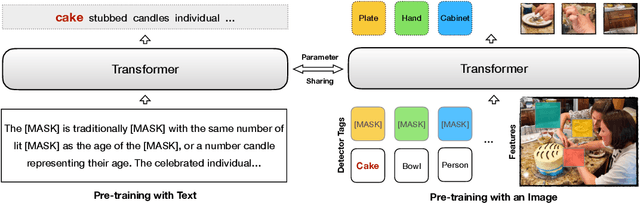
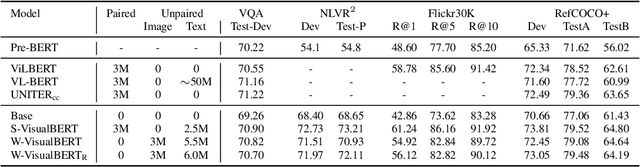

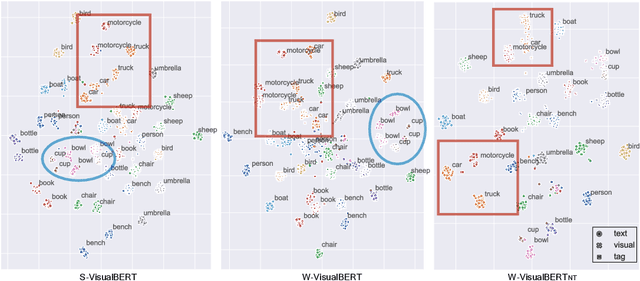
Pre-trained contextual vision-and-language (V&L) models have brought impressive performance improvement on various benchmarks. However, the paired text-image data required for pre-training are hard to collect and scale up. We investigate if a strong V&L representation model can be learned without text-image pairs. We propose Weakly-supervised VisualBERT with the key idea of conducting "mask-and-predict" pre-training on language-only and image-only corpora. Additionally, we introduce the object tags detected by an object recognition model as anchor points to bridge two modalities. Evaluation on four V&L benchmarks shows that Weakly-supervised VisualBERT achieves similar performance with a model pre-trained with paired data. Besides, pre-training on more image-only data further improves a model that already has access to aligned data, suggesting the possibility of utilizing billions of raw images available to enhance V&L models.
Uncertainty-Aware Few-Shot Image Classification
Oct 09, 2020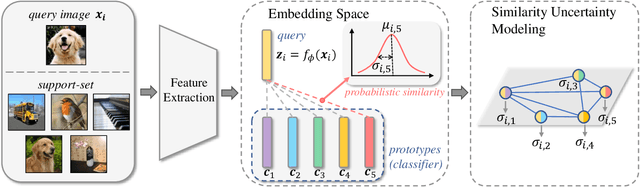

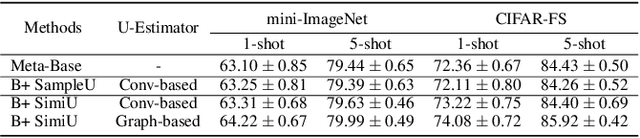
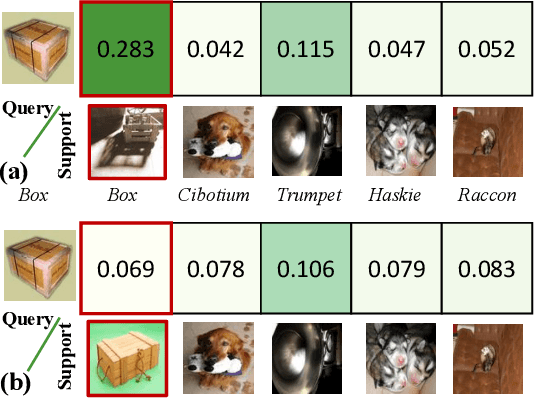
Few-shot image classification aims to learn to recognize new categories from limited labelled data. Recently, metric learning based approaches have been widely investigated which classify a query sample by finding the nearest prototype from the support set based on the feature similarities. For few-shot classification, the calculated similarity of a query-support pair depends on both the query and the support. The network has different confidences/uncertainty on the calculated similarities of the different pairs and there are observation noises on the similarity. Understanding and modeling the uncertainty on the similarity could promote better exploitation of the limited samples in optimization. However, this is still underexplored in few-shot learning. In this work, we propose Uncertainty-Aware Few-Shot (UAFS) image classification by modeling uncertainty of the similarities of query-support pairs and performing uncertainty-aware optimization. Particularly, we design a graph-based model to jointly estimate the uncertainty of similarities between a query and the prototypes in the support set. We optimize the network based on the modeled uncertainty by converting the observed similarity to a probabilistic similarity distribution to be robust to observation noises. Extensive experiments show our proposed method brings significant improvements on top of a strong baseline and achieves the state-of-the-art performance.
Ref-NMS: Breaking Proposal Bottlenecks in Two-Stage Referring Expression Grounding
Sep 03, 2020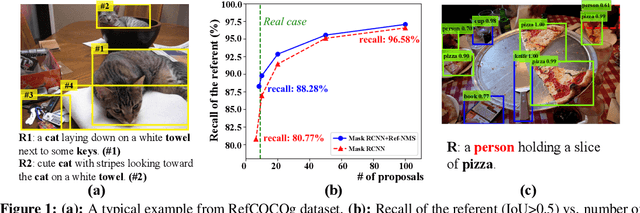
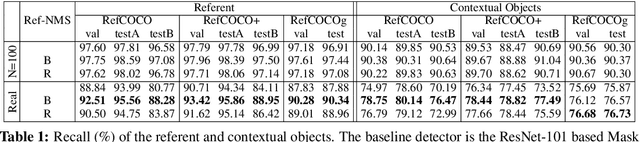
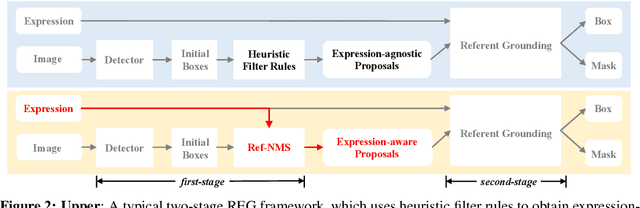
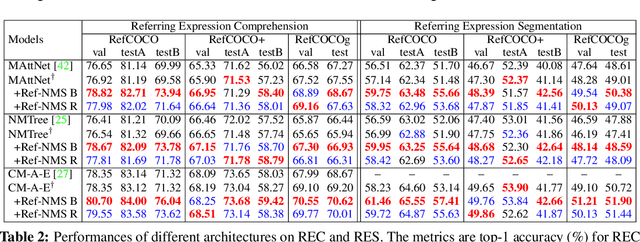
The prevailing framework for solving referring expression grounding is based on a two-stage process: 1) detecting proposals with an object detector and 2) grounding the referent to one of the proposals. Existing two-stage solutions mostly focus on the grounding step, which aims to align the expressions with the proposals. In this paper, we argue that these methods overlook an obvious mismatch between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i.e., expression-agnostic), hoping that the proposals contain all right instances in the expression (i.e., expression-aware). Due to this mismatch, current two-stage methods suffer from a severe performance drop between detected and ground-truth proposals. To this end, we propose Ref-NMS, which is the first method to yield expression-aware proposals at the first stage. Ref-NMS regards all nouns in the expression as critical objects, and introduces a lightweight module to predict a score for aligning each box with a critical object. These scores can guide the NMSoperation to filter out the boxes irrelevant to the expression, increasing the recall of critical objects, resulting in a significantly improved grounding performance. Since Ref-NMS is agnostic to the grounding step, it can be easily integrated into any state-of-the-art two-stage method. Extensive ablation studies on several backbones, benchmarks, and tasks consistently demonstrate the superiority of Ref-NMS.
Analogical Reasoning for Visually Grounded Language Acquisition
Jul 22, 2020
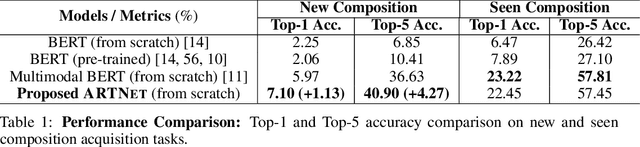
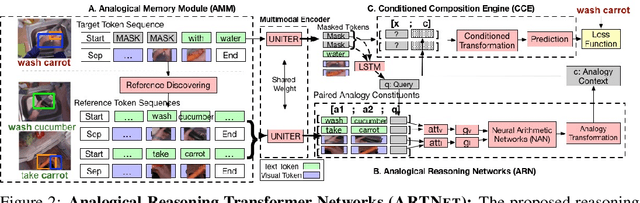

Children acquire language subconsciously by observing the surrounding world and listening to descriptions. They can discover the meaning of words even without explicit language knowledge, and generalize to novel compositions effortlessly. In this paper, we bring this ability to AI, by studying the task of Visually grounded Language Acquisition (VLA). We propose a multimodal transformer model augmented with a novel mechanism for analogical reasoning, which approximates novel compositions by learning semantic mapping and reasoning operations from previously seen compositions. Our proposed method, Analogical Reasoning Transformer Networks (ARTNet), is trained on raw multimedia data (video frames and transcripts), and after observing a set of compositions such as "washing apple" or "cutting carrot", it can generalize and recognize new compositions in new video frames, such as "washing carrot" or "cutting apple". To this end, ARTNet refers to relevant instances in the training data and uses their visual features and captions to establish analogies with the query image. Then it chooses the suitable verb and noun to create a new composition that describes the new image best. Extensive experiments on an instructional video dataset demonstrate that the proposed method achieves significantly better generalization capability and recognition accuracy compared to state-of-the-art transformer models.
COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation
Jul 06, 2020
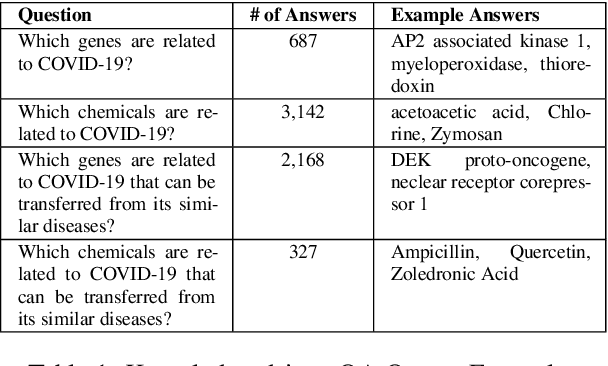
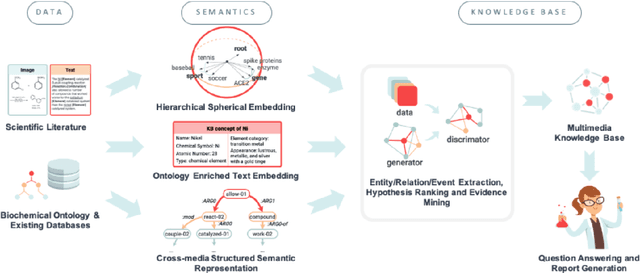
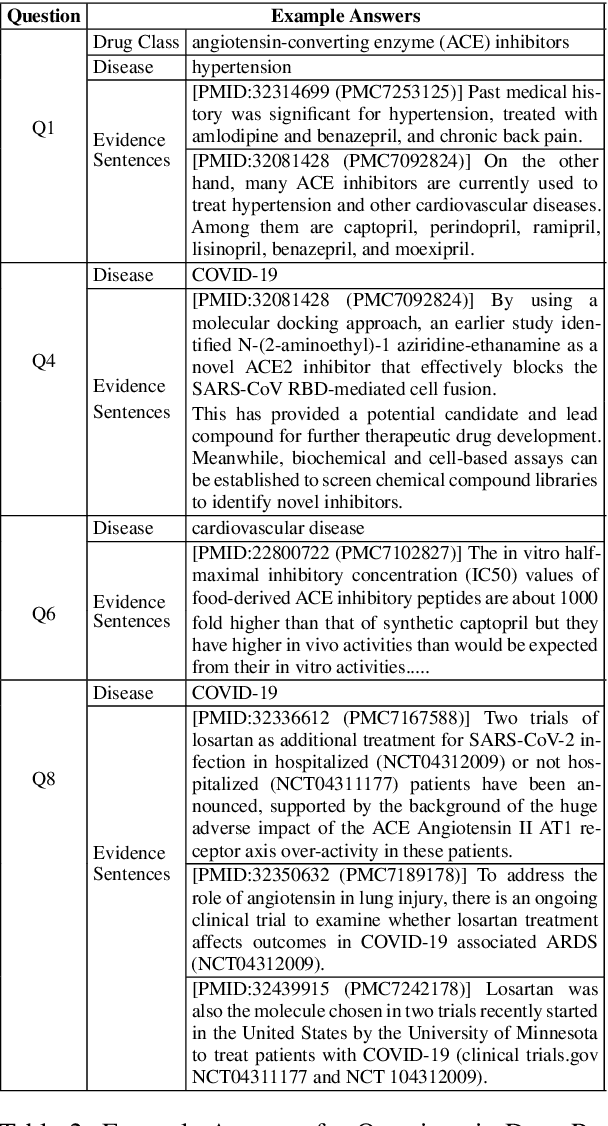
To combat COVID-19, clinicians and scientists all need to digest the vast amount of relevant biomedical knowledge in literature to understand the disease mechanism and the related biological functions. We have developed a novel and comprehensive knowledge discovery framework, COVID-KG, which leverages novel semantic representation and external ontologies to represent text and images in the input literature data, and then performs various extraction components to extract fine-grained multimedia knowledge elements (entities, relations and events). We then exploit the constructed multimedia KGs for question answering and report generation, using drug repurposing as a case study. Our framework also provides detailed contextual sentences, subfigures and knowledge subgraphs as evidence. All of the data, KGs, resources, and shared services are publicly available.
Learning Visual Commonsense for Robust Scene Graph Generation
Jun 17, 2020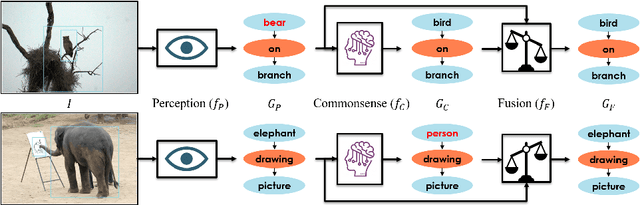

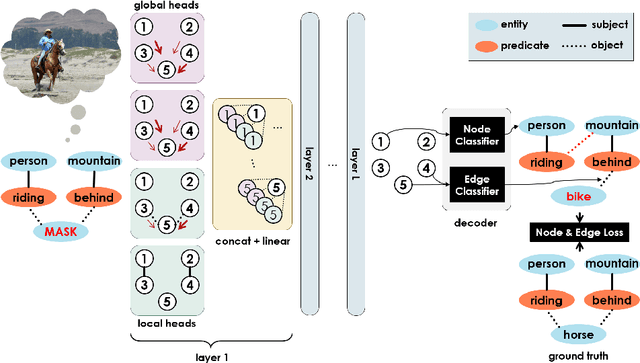
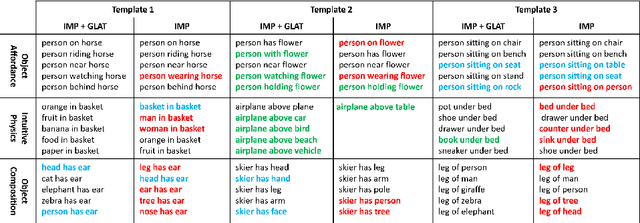
Scene graph generation models understand the scene through object and predicate recognition, but are prone to mistakes due to the challenges of perception in the wild. Perception errors often lead to nonsensical compositions in the output scene graph, which do not follow real-world rules and patterns, and can be corrected using commonsense knowledge. We propose the first method to acquire visual commonsense such as affordance and intuitive physics automatically from data, and use that to enhance scene graph generation. To this end, we extend transformers to incorporate the structure of scene graphs, and train our Global-Local Attention Transformer on a scene graph corpus. Once trained, our commonsense model can be applied on any perception model and correct its obvious mistakes, resulting in a more commonsensical scene graph. We show the proposed model learns commonsense better than any alternative, and improves the accuracy of any scene graph generation model. Nevertheless, strong disproportions in real-world datasets could bias commonsense to miscorrect already confident perceptions. We address this problem by devising a fusion module that compares predictions made by the perception and commonsense models, and the confidence of each, to make a hybrid decision. Our full model learns commonsense and knows when to use it, which is shown effective through experiments, resulting in a new state of the art.
Deep Learning Guided Building Reconstruction from Satellite Imagery-derived Point Clouds
May 19, 2020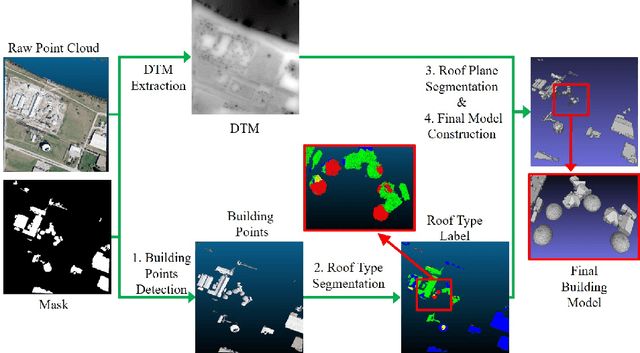
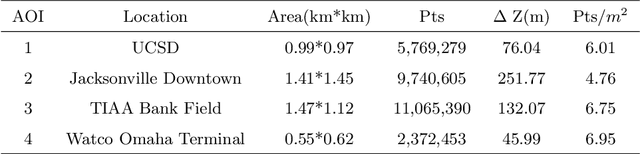
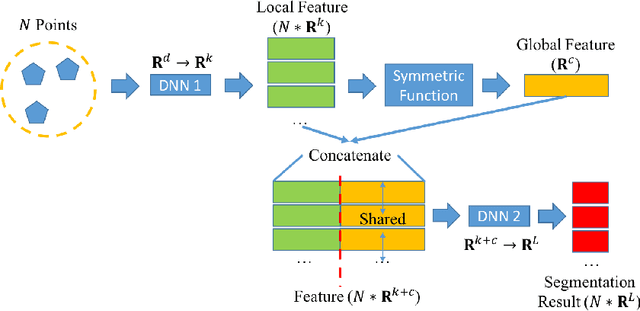
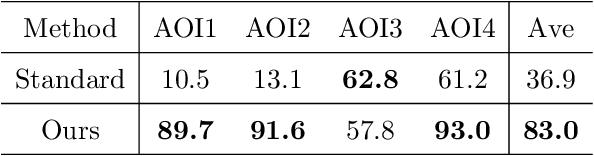
3D urban reconstruction of buildings from remotely sensed imagery has drawn significant attention during the past two decades. While aerial imagery and LiDAR provide higher resolution, satellite imagery is cheaper and more efficient to acquire for large scale need. However, the high, orbital altitude of satellite observation brings intrinsic challenges, like unpredictable atmospheric effect, multi view angles, significant radiometric differences due to the necessary multiple views, diverse land covers and urban structures in a scene, small base-height ratio or narrow field of view, all of which may degrade 3D reconstruction quality. To address these major challenges, we present a reliable and effective approach for building model reconstruction from the point clouds generated from multi-view satellite images. We utilize multiple types of primitive shapes to fit the input point cloud. Specifically, a deep-learning approach is adopted to distinguish the shape of building roofs in complex and yet noisy scenes. For points that belong to the same roof shape, a multi-cue, hierarchical RANSAC approach is proposed for efficient and reliable segmenting and reconstructing the building point cloud. Experimental results over four selected urban areas (0.34 to 2.04 sq km in size) demonstrate the proposed method can generate detailed roof structures under noisy data environments. The average successful rate for building shape recognition is 83.0%, while the overall completeness and correctness are over 70% with reference to ground truth created from airborne lidar. As the first effort to address the public need of large scale city model generation, the development is deployed as open source software.
Cross-media Structured Common Space for Multimedia Event Extraction
May 05, 2020
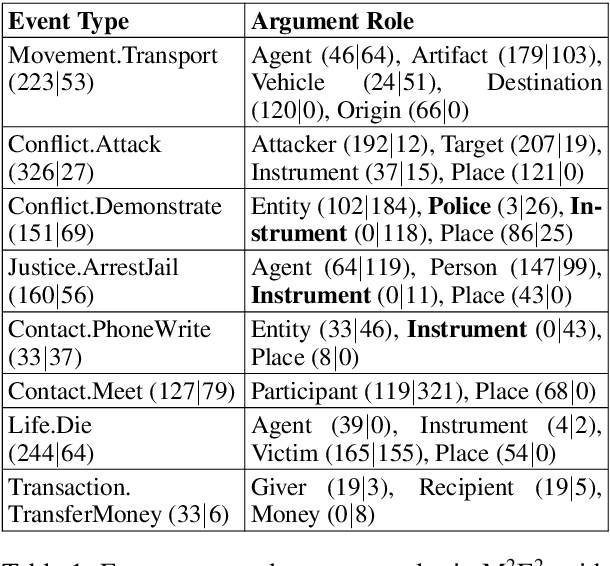

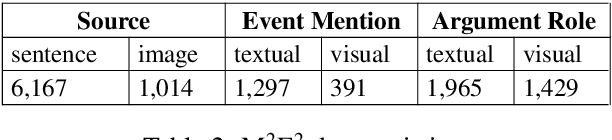
We introduce a new task, MultiMedia Event Extraction (M2E2), which aims to extract events and their arguments from multimedia documents. We develop the first benchmark and collect a dataset of 245 multimedia news articles with extensively annotated events and arguments. We propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. The structures are aligned across modalities by employing a weakly supervised training strategy, which enables exploiting available resources without explicit cross-media annotation. Compared to uni-modal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction. Compared to state-of-the-art multimedia unstructured representations, we achieve 8.3% and 5.0% absolute F-score gains on multimedia event extraction and argument role labeling, respectively. By utilizing images, we extract 21.4% more event mentions than traditional text-only methods.