 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
May 06, 2024



Large language models (LLMs) have recently achieved state-of-the-art performance across various tasks, yet due to their large computational requirements, they struggle with strict latency and power demands. Deep neural network (DNN) quantization has traditionally addressed these limitations by converting models to low-precision integer formats. Yet recently alternative formats, such as Normal Float (NF4), have been shown to consistently increase model accuracy, albeit at the cost of increased chip area. In this work, we first conduct a large-scale analysis of LLM weights and activations across 30 networks to conclude most distributions follow a Student's t-distribution. We then derive a new theoretically optimal format, Student Float (SF4), with respect to this distribution, that improves over NF4 across modern LLMs, for example increasing the average accuracy on LLaMA2-7B by 0.76% across tasks. Using this format as a high-accuracy reference, we then propose augmenting E2M1 with two variants of supernormal support for higher model accuracy. Finally, we explore the quality and performance frontier across 11 datatypes, including non-traditional formats like Additive-Powers-of-Two (APoT), by evaluating their model accuracy and hardware complexity. We discover a Pareto curve composed of INT4, E2M1, and E2M1 with supernormal support, which offers a continuous tradeoff between model accuracy and chip area. For example, E2M1 with supernormal support increases the accuracy of Phi-2 by up to 2.19% with 1.22% area overhead, enabling more LLM-based applications to be run at four bits.
Bridging the Fairness Divide: Achieving Group and Individual Fairness in Graph Neural Networks
Apr 26, 2024



Graph neural networks (GNNs) have emerged as a powerful tool for analyzing and learning from complex data structured as graphs, demonstrating remarkable effectiveness in various applications, such as social network analysis, recommendation systems, and drug discovery. However, despite their impressive performance, the fairness problem has increasingly gained attention as a crucial aspect to consider. Existing research in graph learning focuses on either group fairness or individual fairness. However, since each concept provides unique insights into fairness from distinct perspectives, integrating them into a fair graph neural network system is crucial. To the best of our knowledge, no study has yet to comprehensively tackle both individual and group fairness simultaneously. In this paper, we propose a new concept of individual fairness within groups and a novel framework named Fairness for Group and Individual (FairGI), which considers both group fairness and individual fairness within groups in the context of graph learning. FairGI employs the similarity matrix of individuals to achieve individual fairness within groups, while leveraging adversarial learning to address group fairness in terms of both Equal Opportunity and Statistical Parity. The experimental results demonstrate that our approach not only outperforms other state-of-the-art models in terms of group fairness and individual fairness within groups, but also exhibits excellent performance in population-level individual fairness, while maintaining comparable prediction accuracy.
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models
Apr 01, 2024



Diffusion Models are vulnerable to backdoor attacks, where malicious attackers inject backdoors by poisoning some parts of the training samples during the training stage. This poses a serious threat to the downstream users, who query the diffusion models through the API or directly download them from the internet. To mitigate the threat of backdoor attacks, there have been a plethora of investigations on backdoor detections. However, none of them designed a specialized backdoor detection method for diffusion models, rendering the area much under-explored. Moreover, these prior methods mainly focus on the traditional neural networks in the classification task, which cannot be adapted to the backdoor detections on the generative task easily. Additionally, most of the prior methods require white-box access to model weights and architectures, or the probability logits as additional information, which are not always practical. In this paper, we propose a Unified Framework for Input-level backdoor Detection (UFID) on the diffusion models, which is motivated by observations in the diffusion models and further validated with a theoretical causality analysis. Extensive experiments across different datasets on both conditional and unconditional diffusion models show that our method achieves a superb performance on detection effectiveness and run-time efficiency. The code is available at https://github.com/GuanZihan/official_UFID.
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024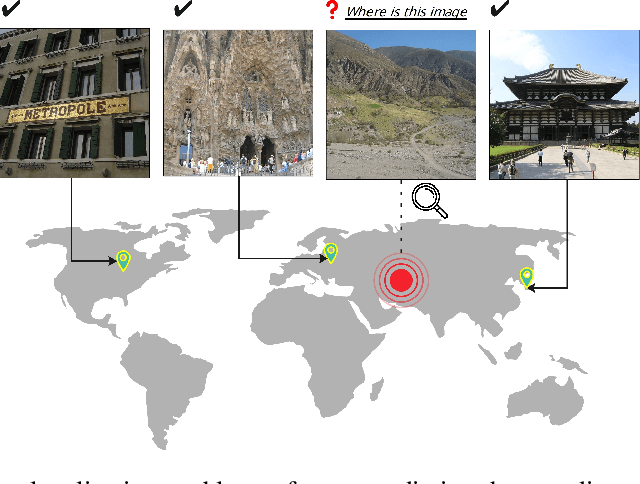
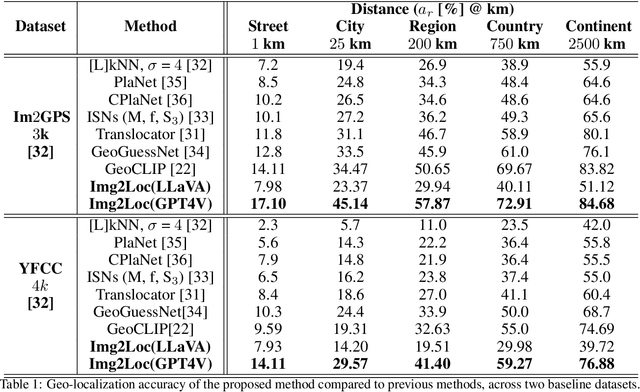
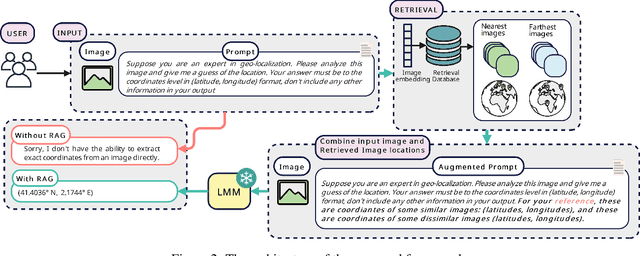
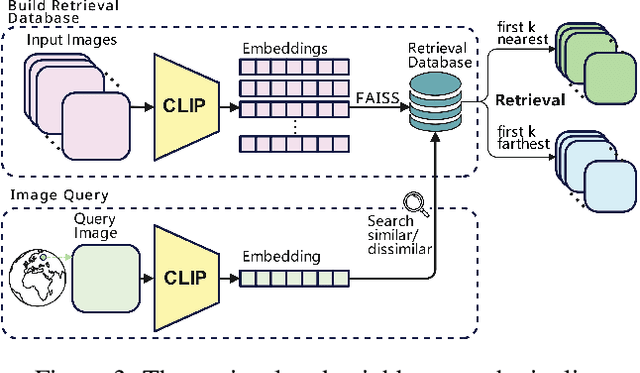
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.
Purified and Unified Steganographic Network
Feb 27, 2024



Steganography is the art of hiding secret data into the cover media for covert communication. In recent years, more and more deep neural network (DNN)-based steganographic schemes are proposed to train steganographic networks for secret embedding and recovery, which are shown to be promising. Compared with the handcrafted steganographic tools, steganographic networks tend to be large in size. It raises concerns on how to imperceptibly and effectively transmit these networks to the sender and receiver to facilitate the covert communication. To address this issue, we propose in this paper a Purified and Unified Steganographic Network (PUSNet). It performs an ordinary machine learning task in a purified network, which could be triggered into steganographic networks for secret embedding or recovery using different keys. We formulate the construction of the PUSNet into a sparse weight filling problem to flexibly switch between the purified and steganographic networks. We further instantiate our PUSNet as an image denoising network with two steganographic networks concealed for secret image embedding and recovery. Comprehensive experiments demonstrate that our PUSNet achieves good performance on secret image embedding, secret image recovery, and image denoising in a single architecture. It is also shown to be capable of imperceptibly carrying the steganographic networks in a purified network. Code is available at \url{https://github.com/albblgb/PUSNet}
Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
Feb 20, 2024



In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
Bridging Causal Discovery and Large Language Models: A Comprehensive Survey of Integrative Approaches and Future Directions
Feb 16, 2024



Causal discovery (CD) and Large Language Models (LLMs) represent two emerging fields of study with significant implications for artificial intelligence. Despite their distinct origins, CD focuses on uncovering cause-effect relationships from data, and LLMs on processing and generating humanlike text, the convergence of these domains offers novel insights and methodologies for understanding complex systems. This paper presents a comprehensive survey of the integration of LLMs, such as GPT4, into CD tasks. We systematically review and compare existing approaches that leverage LLMs for various CD tasks and highlight their innovative use of metadata and natural language to infer causal structures. Our analysis reveals the strengths and potential of LLMs in both enhancing traditional CD methods and as an imperfect expert, alongside the challenges and limitations inherent in current practices. Furthermore, we identify gaps in the literature and propose future research directions aimed at harnessing the full potential of LLMs in causality research. To our knowledge, this is the first survey to offer a unified and detailed examination of the synergy between LLMs and CD, setting the stage for future advancements in the field.
SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing
Jan 30, 2024



There has been a proliferation of artificial intelligence applications, where model training is key to promising high-quality services for these applications. However, the model training process is both time-intensive and energy-intensive, inevitably affecting the user's demand for application efficiency. Layer freezing, an efficient model training technique, has been proposed to improve training efficiency. Although existing layer freezing methods demonstrate the great potential to reduce model training costs, they still remain shortcomings such as lacking generalizability and compromised accuracy. For instance, existing layer freezing methods either require the freeze configurations to be manually defined before training, which does not apply to different networks, or use heuristic freezing criteria that is hard to guarantee decent accuracy in different scenarios. Therefore, there lacks a generic and smart layer freezing method that can automatically perform ``in-situation'' layer freezing for different networks during training processes. To this end, we propose a generic and efficient training framework (SmartFRZ). The core proposed technique in SmartFRZ is attention-guided layer freezing, which can automatically select the appropriate layers to freeze without compromising accuracy. Experimental results show that SmartFRZ effectively reduces the amount of computation in training and achieves significant training acceleration, and outperforms the state-of-the-art layer freezing approaches.
EdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024



Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
MOS-FAD: Improving Fake Audio Detection Via Automatic Mean Opinion Score Prediction
Jan 25, 2024Automatic Mean Opinion Score (MOS) prediction is employed to evaluate the quality of synthetic speech. This study extends the application of predicted MOS to the task of Fake Audio Detection (FAD), as we expect that MOS can be used to assess how close synthesized speech is to the natural human voice. We propose MOS-FAD, where MOS can be leveraged at two key points in FAD: training data selection and model fusion. In training data selection, we demonstrate that MOS enables effective filtering of samples from unbalanced datasets. In the model fusion, our results demonstrate that incorporating MOS as a gating mechanism in FAD model fusion enhances overall performance.