 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONAR: Self-Distilled Continual Pre-training for Domain Adaptive Audio Representation
Sep 19, 2025Self-supervised learning (SSL) on large-scale datasets like AudioSet has become the dominant paradigm for audio representation learning. While the continuous influx of new, unlabeled audio presents an opportunity to enrich these static representations, a naive approach is to retrain the model from scratch using all available data. However, this method is computationally prohibitive and discards the valuable knowledge embedded in the previously trained model weights. To address this inefficiency, we propose SONAR (Self-distilled cONtinual pre-training for domain adaptive Audio Representation), a continual pre-training framework built upon BEATs. SONAR effectively adapts to new domains while mitigating catastrophic forgetting by tackling three key challenges: implementing a joint sampling strategy for new and prior data, applying regularization to balance specificity and generality, and dynamically expanding the tokenizer codebook for novel acoustic patterns. Experiments across four distinct domains demonstrate that our method achieves both high adaptability and robust resistance to forgetting.
Disentangling Age and Identity with a Mutual Information Minimization Approach for Cross-Age Speaker Verification
Sep 24, 2024



There has been an increasing research interest in cross-age speaker verification~(CASV). However, existing speaker verification systems perform poorly in CASV due to the great individual differences in voice caused by aging. In this paper, we propose a disentangled representation learning framework for CASV based on mutual information~(MI) minimization. In our method, a backbone model is trained to disentangle the identity- and age-related embeddings from speaker information, and an MI estimator is trained to minimize the correlation between age- and identity-related embeddings via MI minimization, resulting in age-invariant speaker embeddings. Furthermore, by using the age gaps between positive and negative samples, we propose an aging-aware MI minimization loss function that allows the backbone model to focus more on the vocal changes with large age gaps. Experimental results show that the proposed method outperforms other methods on multiple Cross-Age test sets of Vox-CA.
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Sep 12, 2024



This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
LAFMA: A Latent Flow Matching Model for Text-to-Audio Generation
Jun 12, 2024



Recently, the application of diffusion models has facilitated the significant development of speech and audio generation. Nevertheless, the quality of samples generated by diffusion models still needs improvement. And the effectiveness of the method is accompanied by the extensive number of sampling steps, leading to an extended synthesis time necessary for generating high-quality audio. Previous Text-to-Audio (TTA) methods mostly used diffusion models in the latent space for audio generation. In this paper, we explore the integration of the Flow Matching (FM) model into the audio latent space for audio generation. The FM is an alternative simulation-free method that trains continuous normalization flows (CNF) based on regressing vector fields. We demonstrate that our model significantly enhances the quality of generated audio samples, achieving better performance than prior models. Moreover, it reduces the number of inference steps to ten steps almost without sacrificing performance.
MOS-FAD: Improving Fake Audio Detection Via Automatic Mean Opinion Score Prediction
Jan 25, 2024Automatic Mean Opinion Score (MOS) prediction is employed to evaluate the quality of synthetic speech. This study extends the application of predicted MOS to the task of Fake Audio Detection (FAD), as we expect that MOS can be used to assess how close synthesized speech is to the natural human voice. We propose MOS-FAD, where MOS can be leveraged at two key points in FAD: training data selection and model fusion. In training data selection, we demonstrate that MOS enables effective filtering of samples from unbalanced datasets. In the model fusion, our results demonstrate that incorporating MOS as a gating mechanism in FAD model fusion enhances overall performance.
LE-SSL-MOS: Self-Supervised Learning MOS Prediction with Listener Enhancement
Nov 17, 2023



Recently, researchers have shown an increasing interest in automatically predicting the subjective evaluation for speech synthesis systems. This prediction is a challenging task, especially on the out-of-domain test set. In this paper, we proposed a novel fusion model for MOS prediction that combines supervised and unsupervised approaches. In the supervised aspect, we developed an SSL-based predictor called LE-SSL-MOS. The LE-SSL-MOS utilizes pre-trained self-supervised learning models and further improves prediction accuracy by utilizing the opinion scores of each utterance in the listener enhancement branch. In the unsupervised aspect, two steps are contained: we fine-tuned the unit language model (ULM) using highly intelligible domain data to improve the correlation of an unsupervised metric - SpeechLMScore. Another is that we utilized ASR confidence as a new metric with the help of ensemble learning. To our knowledge, this is the first architecture that fuses supervised and unsupervised methods for MOS prediction. With these approaches, our experimental results on the VoiceMOS Challenge 2023 show that LE-SSL-MOS performs better than the baseline. Our fusion system achieved an absolute improvement of 13% over LE-SSL-MOS on the noisy and enhanced speech track. Our system ranked 1st and 2nd, respectively, in the French speech synthesis track and the challenge's noisy and enhanced speech track.
Fusion of Self-supervised Learned Models for MOS Prediction
Apr 11, 2022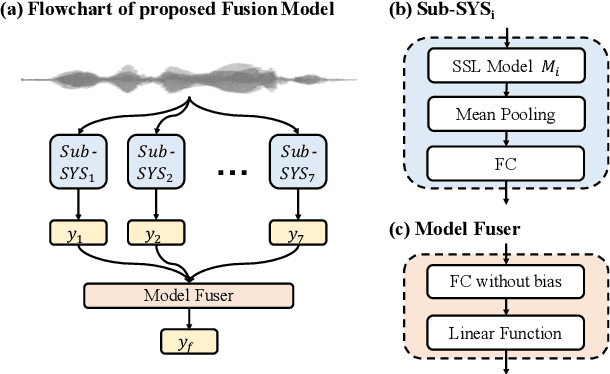
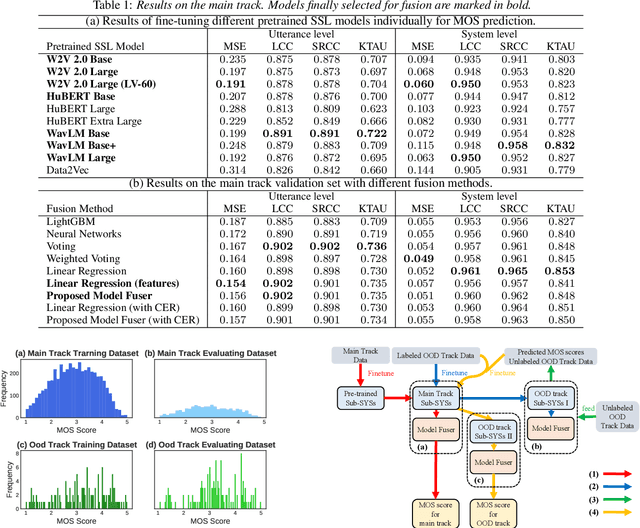
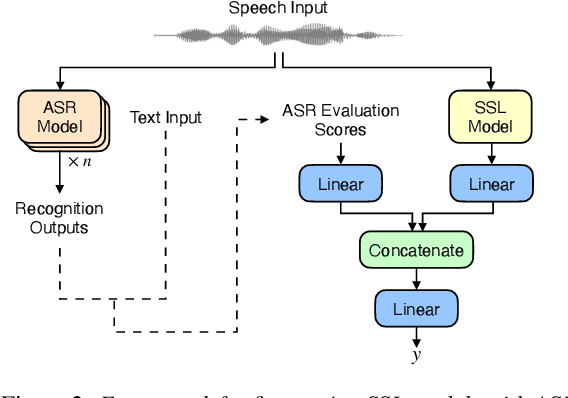
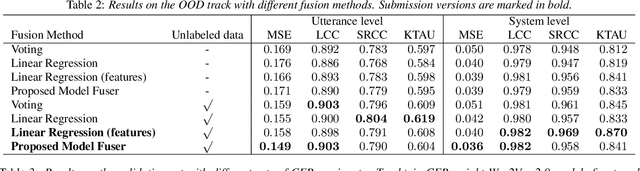
We participated in the mean opinion score (MOS) prediction challenge, 2022. This challenge aims to predict MOS scores of synthetic speech on two tracks, the main track and a more challenging sub-track: out-of-domain (OOD). To improve the accuracy of the predicted scores, we have explored several model fusion-related strategies and proposed a fused framework in which seven pretrained self-supervised learned (SSL) models have been engaged. These pretrained SSL models are derived from three ASR frameworks, including Wav2Vec, Hubert, and WavLM. For the OOD track, we followed the 7 SSL models selected on the main track and adopted a semi-supervised learning method to exploit the unlabeled data. According to the official analysis results, our system has achieved 1st rank in 6 out of 16 metrics and is one of the top 3 systems for 13 out of 16 metrics. Specifically, we have achieved the highest LCC, SRCC, and KTAU scores at the system level on main track, as well as the best performance on the LCC, SRCC, and KTAU evaluation metrics at the utterance level on OOD track. Compared with the basic SSL models, the prediction accuracy of the fused system has been largely improved, especially on OOD sub-track.