 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRvS: What is Essential for Offline RL via Supervised Learning?
Dec 20, 2021



Recent work has shown that supervised learning alone, without temporal difference (TD) learning, can be remarkably effective for offline RL. When does this hold true, and which algorithmic components are necessary? Through extensive experiments, we boil supervised learning for offline RL down to its essential elements. In every environment suite we consider, simply maximizing likelihood with a two-layer feedforward MLP is competitive with state-of-the-art results of substantially more complex methods based on TD learning or sequence modeling with Transformers. Carefully choosing model capacity (e.g., via regularization or architecture) and choosing which information to condition on (e.g., goals or rewards) are critical for performance. These insights serve as a field guide for practitioners doing Reinforcement Learning via Supervised Learning (which we coin "RvS learning"). They also probe the limits of existing RvS methods, which are comparatively weak on random data, and suggest a number of open problems.
Autonomous Reinforcement Learning: Formalism and Benchmarking
Dec 17, 2021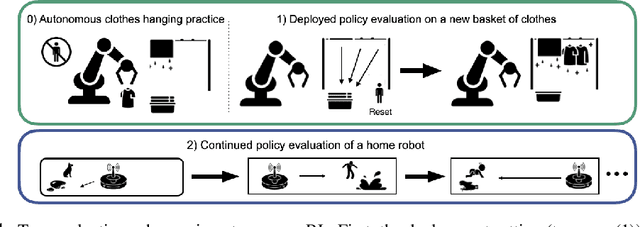

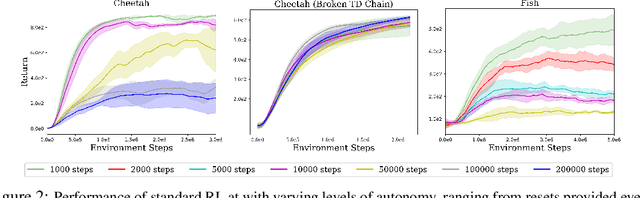

Reinforcement learning (RL) provides a naturalistic framing for learning through trial and error, which is appealing both because of its simplicity and effectiveness and because of its resemblance to how humans and animals acquire skills through experience. However, real-world embodied learning, such as that performed by humans and animals, is situated in a continual, non-episodic world, whereas common benchmark tasks in RL are episodic, with the environment resetting between trials to provide the agent with multiple attempts. This discrepancy presents a major challenge when attempting to take RL algorithms developed for episodic simulated environments and run them on real-world platforms, such as robots. In this paper, we aim to address this discrepancy by laying out a framework for Autonomous Reinforcement Learning (ARL): reinforcement learning where the agent not only learns through its own experience, but also contends with lack of human supervision to reset between trials. We introduce a simulated benchmark EARL around this framework, containing a set of diverse and challenging simulated tasks reflective of the hurdles introduced to learning when only a minimal reliance on extrinsic intervention can be assumed. We show that standard approaches to episodic RL and existing approaches struggle as interventions are minimized, underscoring the need for developing new algorithms for reinforcement learning with a greater focus on autonomy.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

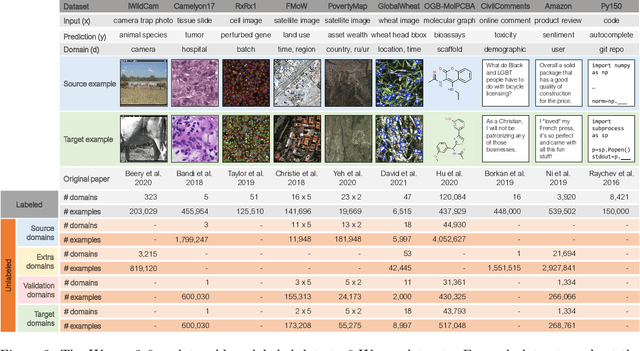
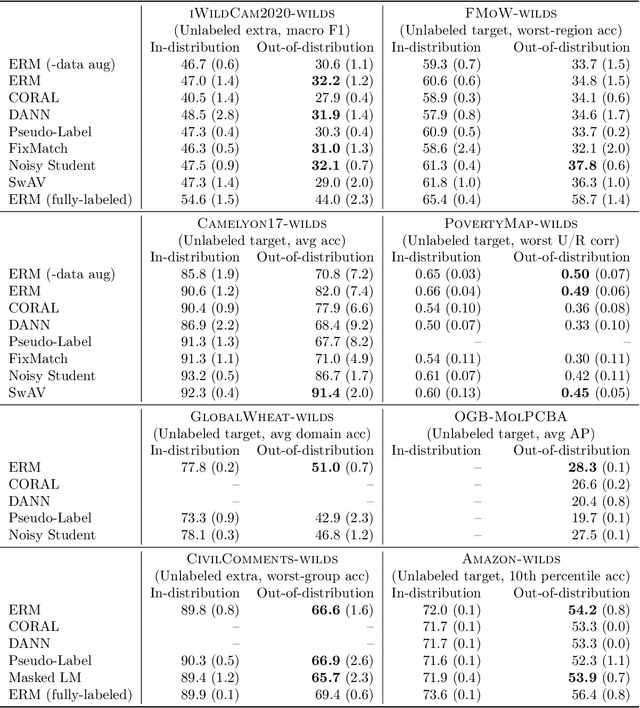
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization
Dec 09, 2021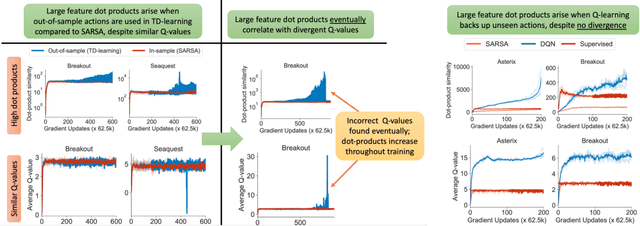
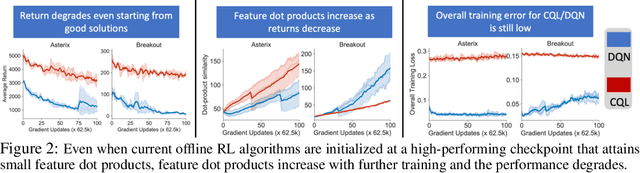

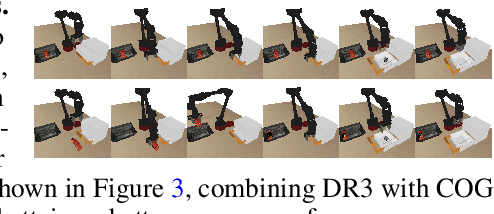
Despite overparameterization, deep networks trained via supervised learning are easy to optimize and exhibit excellent generalization. One hypothesis to explain this is that overparameterized deep networks enjoy the benefits of implicit regularization induced by stochastic gradient descent, which favors parsimonious solutions that generalize well on test inputs. It is reasonable to surmise that deep reinforcement learning (RL) methods could also benefit from this effect. In this paper, we discuss how the implicit regularization effect of SGD seen in supervised learning could in fact be harmful in the offline deep RL setting, leading to poor generalization and degenerate feature representations. Our theoretical analysis shows that when existing models of implicit regularization are applied to temporal difference learning, the resulting derived regularizer favors degenerate solutions with excessive "aliasing", in stark contrast to the supervised learning case. We back up these findings empirically, showing that feature representations learned by a deep network value function trained via bootstrapping can indeed become degenerate, aliasing the representations for state-action pairs that appear on either side of the Bellman backup. To address this issue, we derive the form of this implicit regularizer and, inspired by this derivation, propose a simple and effective explicit regularizer, called DR3, that counteracts the undesirable effects of this implicit regularizer. When combined with existing offline RL methods, DR3 substantially improves performance and stability, alleviating unlearning in Atari 2600 games, D4RL domains and robotic manipulation from images.
CoMPS: Continual Meta Policy Search
Dec 08, 2021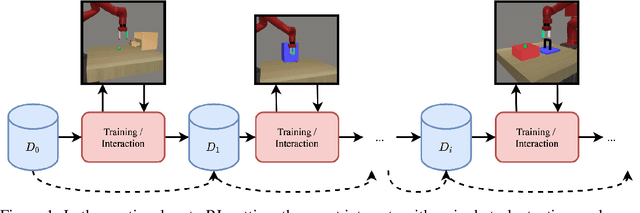

We develop a new continual meta-learning method to address challenges in sequential multi-task learning. In this setting, the agent's goal is to achieve high reward over any sequence of tasks quickly. Prior meta-reinforcement learning algorithms have demonstrated promising results in accelerating the acquisition of new tasks. However, they require access to all tasks during training. Beyond simply transferring past experience to new tasks, our goal is to devise continual reinforcement learning algorithms that learn to learn, using their experience on previous tasks to learn new tasks more quickly. We introduce a new method, continual meta-policy search (CoMPS), that removes this limitation by meta-training in an incremental fashion, over each task in a sequence, without revisiting prior tasks. CoMPS continuously repeats two subroutines: learning a new task using RL and using the experience from RL to perform completely offline meta-learning to prepare for subsequent task learning. We find that CoMPS outperforms prior continual learning and off-policy meta-reinforcement methods on several sequences of challenging continuous control tasks.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021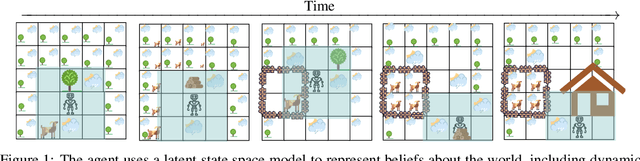



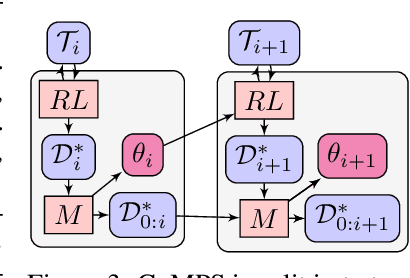
Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.
Hybrid Imitative Planning with Geometric and Predictive Costs in Off-road Environments
Nov 22, 2021
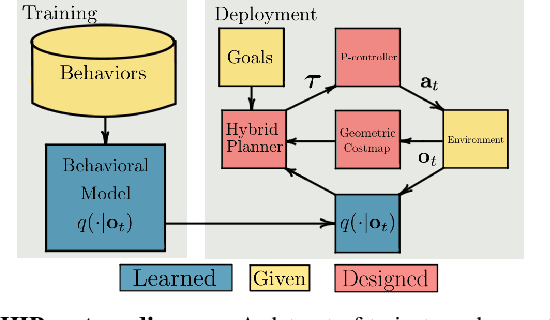
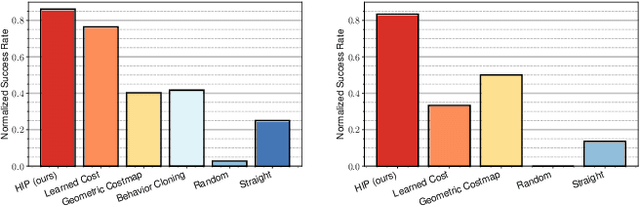

Geometric methods for solving open-world off-road navigation tasks, by learning occupancy and metric maps, provide good generalization but can be brittle in outdoor environments that violate their assumptions (e.g., tall grass). Learning-based methods can directly learn collision-free behavior from raw observations, but are difficult to integrate with standard geometry-based pipelines. This creates an unfortunate conflict -- either use learning and lose out on well-understood geometric navigational components, or do not use it, in favor of extensively hand-tuned geometry-based cost maps. In this work, we reject this dichotomy by designing the learning and non-learning-based components in a way such that they can be effectively combined in a self-supervised manner. Both components contribute to a planning criterion: the learned component contributes predicted traversability as rewards, while the geometric component contributes obstacle cost information. We instantiate and comparatively evaluate our system in both in-distribution and out-of-distribution environments, showing that this approach inherits complementary gains from the learned and geometric components and significantly outperforms either of them. Videos of our results are hosted at https://sites.google.com/view/hybrid-imitative-planning
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021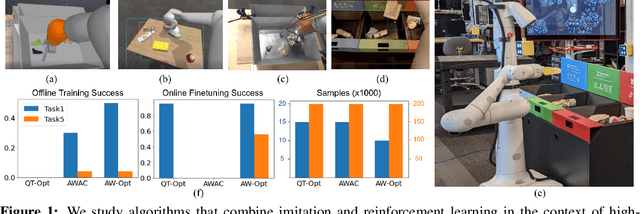
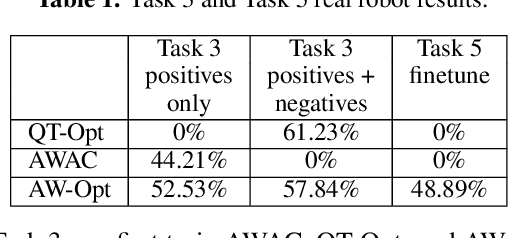
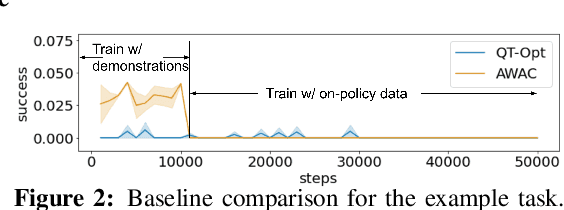
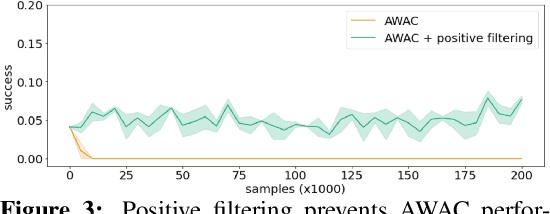
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning
Nov 04, 2021
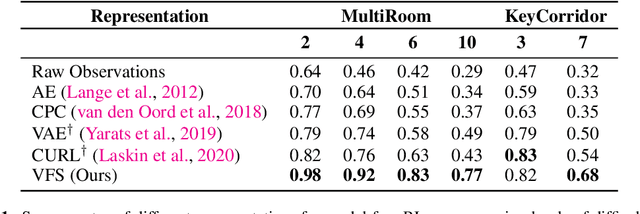
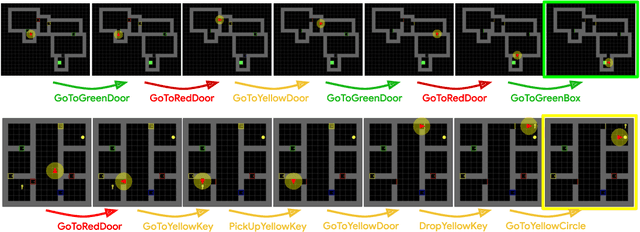
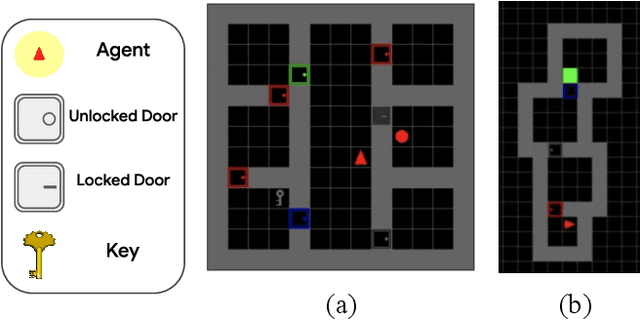
Reinforcement learning can train policies that effectively perform complex tasks. However for long-horizon tasks, the performance of these methods degrades with horizon, often necessitating reasoning over and composing lower-level skills. Hierarchical reinforcement learning aims to enable this by providing a bank of low-level skills as action abstractions. Hierarchies can further improve on this by abstracting the space states as well. We posit that a suitable state abstraction should depend on the capabilities of the available lower-level policies. We propose Value Function Spaces: a simple approach that produces such a representation by using the value functions corresponding to each lower-level skill. These value functions capture the affordances of the scene, thus forming a representation that compactly abstracts task relevant information and robustly ignores distractors. Empirical evaluations for maze-solving and robotic manipulation tasks demonstrate that our approach improves long-horizon performance and enables better zero-shot generalization than alternative model-free and model-based methods.
TRAIL: Near-Optimal Imitation Learning with Suboptimal Data
Oct 27, 2021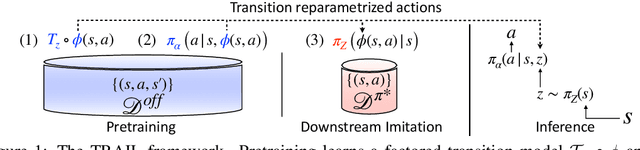
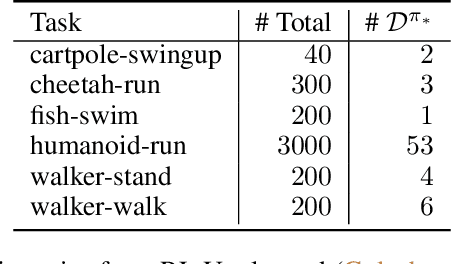


The aim in imitation learning is to learn effective policies by utilizing near-optimal expert demonstrations. However, high-quality demonstrations from human experts can be expensive to obtain in large numbers. On the other hand, it is often much easier to obtain large quantities of suboptimal or task-agnostic trajectories, which are not useful for direct imitation, but can nevertheless provide insight into the dynamical structure of the environment, showing what could be done in the environment even if not what should be done. We ask the question, is it possible to utilize such suboptimal offline datasets to facilitate provably improved downstream imitation learning? In this work, we answer this question affirmatively and present training objectives that use offline datasets to learn a factored transition model whose structure enables the extraction of a latent action space. Our theoretical analysis shows that the learned latent action space can boost the sample-efficiency of downstream imitation learning, effectively reducing the need for large near-optimal expert datasets through the use of auxiliary non-expert data. To learn the latent action space in practice, we propose TRAIL (Transition-Reparametrized Actions for Imitation Learning), an algorithm that learns an energy-based transition model contrastively, and uses the transition model to reparametrize the action space for sample-efficient imitation learning. We evaluate the practicality of our objective through experiments on a set of navigation and locomotion tasks. Our results verify the benefits suggested by our theory and show that TRAIL is able to improve baseline imitation learning by up to 4x in performance.