 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Visual Transformer Compression
Mar 15, 2022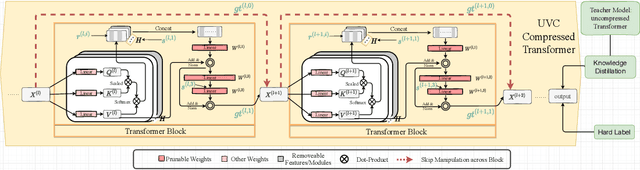
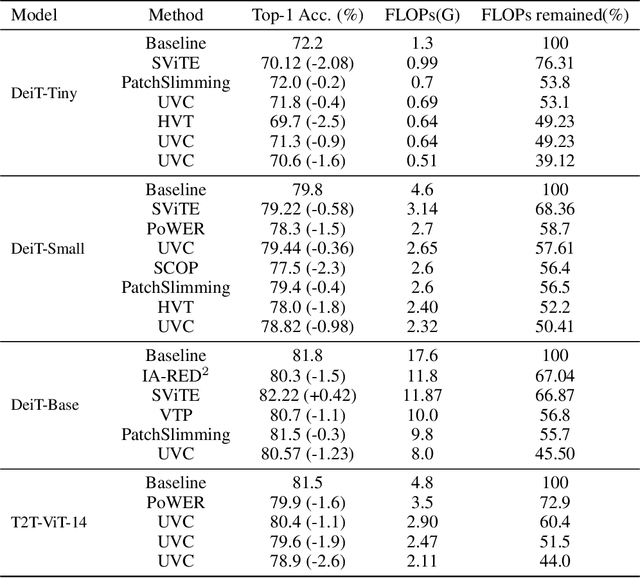
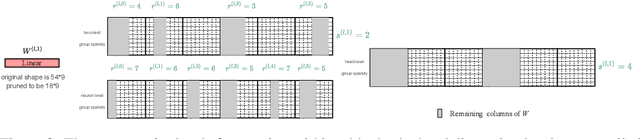
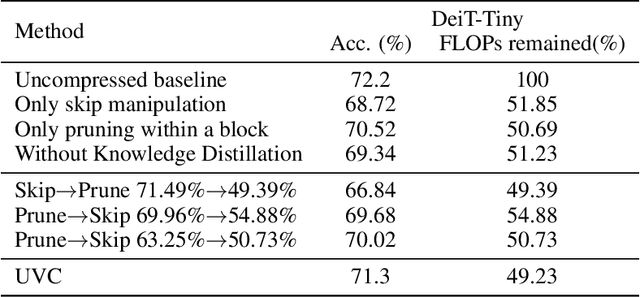
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
Generating Privacy-Preserving Process Data with Deep Generative Models
Mar 15, 2022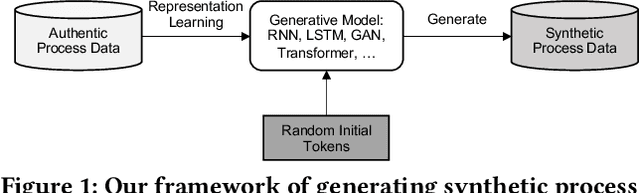
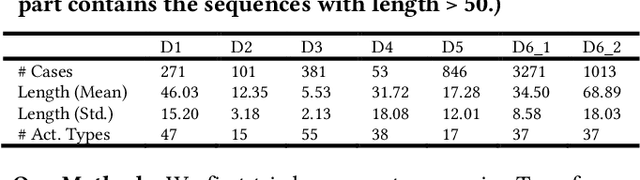
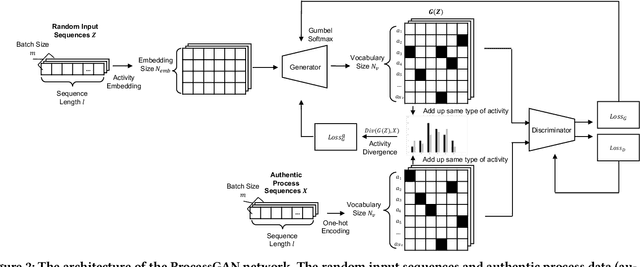
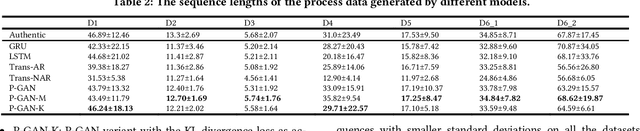
Process data with confidential information cannot be shared directly in public, which hinders the research in process data mining and analytics. Data encryption methods have been studied to protect the data, but they still may be decrypted, which leads to individual identification. We experimented with different models of representation learning and used the learned model to generate synthetic process data. We introduced an adversarial generative network for process data generation (ProcessGAN) with two Transformer networks for the generator and the discriminator. We evaluated ProcessGAN and traditional models on six real-world datasets, of which two are public and four are collected in medical domains. We used statistical metrics and supervised learning scores to evaluate the synthetic data. We also used process mining to discover workflows for the authentic and synthetic datasets and had medical experts evaluate the clinical applicability of the synthetic workflows. We found that ProcessGAN outperformed traditional sequential models when trained on small authentic datasets of complex processes. ProcessGAN better represented the long-range dependencies between the activities, which is important for complicated processes such as the medical processes. Traditional sequential models performed better when trained on large data of simple processes. We conclude that ProcessGAN can generate a large amount of sharable synthetic process data indistinguishable from authentic data.
A Deep Learning Framework for Nuclear Segmentation and Classification in Histopathological Images
Mar 04, 2022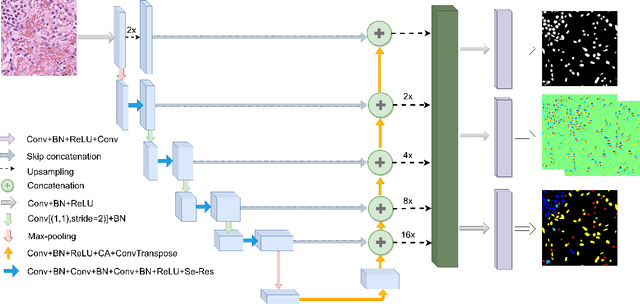
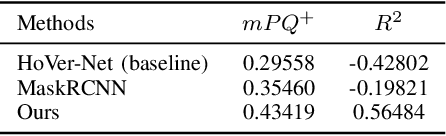
Nucleus segmentation and classification are the prerequisites in the workflow of digital pathology processing. However, it is very challenging due to its high-level heterogeneity and wide variations. This work proposes a deep neural network to simultaneously achieve nuclear classification and segmentation, which is designed using a unified framework with three different branches, including segmentation, HoVer mapping, and classification. The segmentation branch aims to generate the boundaries of each nucleus. The HoVer branch calculates the horizontal and vertical distances of nuclear pixels to their centres of mass. The nuclear classification branch is used to distinguish the class of pixels inside the nucleus obtained from segmentation.
Do Prompts Solve NLP Tasks Using Natural Language?
Mar 02, 2022
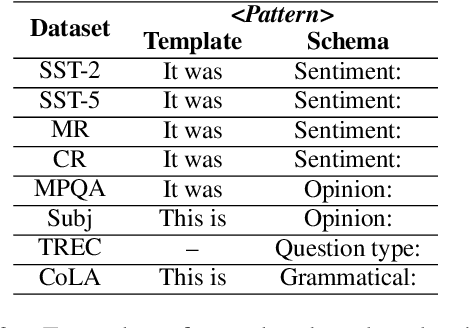

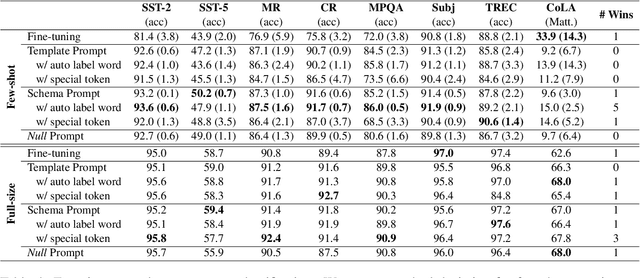
Thanks to the advanced improvement of large pre-trained language models, prompt-based fine-tuning is shown to be effective on a variety of downstream tasks. Though many prompting methods have been investigated, it remains unknown which type of prompts are the most effective among three types of prompts (i.e., human-designed prompts, schema prompts and null prompts). In this work, we empirically compare the three types of prompts under both few-shot and fully-supervised settings. Our experimental results show that schema prompts are the most effective in general. Besides, the performance gaps tend to diminish when the scale of training data grows large.
Adversarial Contrastive Self-Supervised Learning
Feb 26, 2022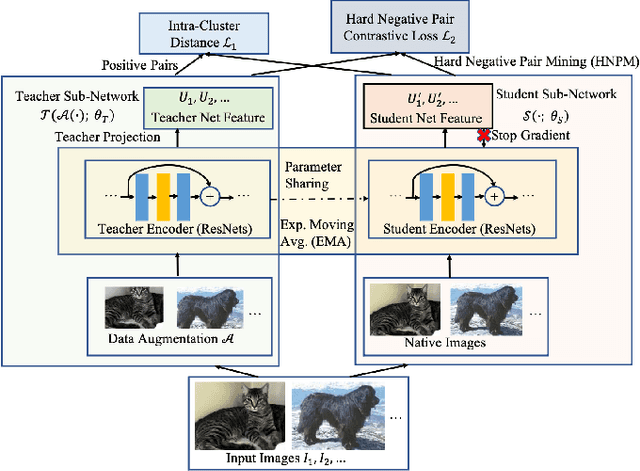
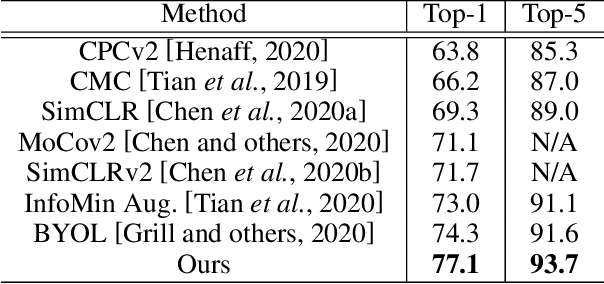
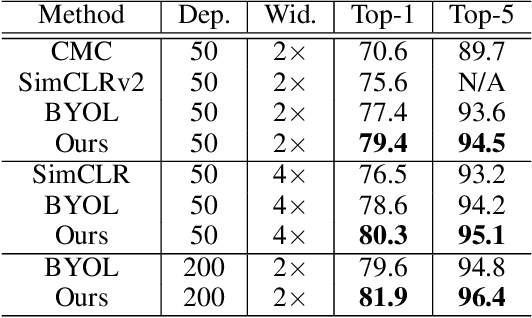
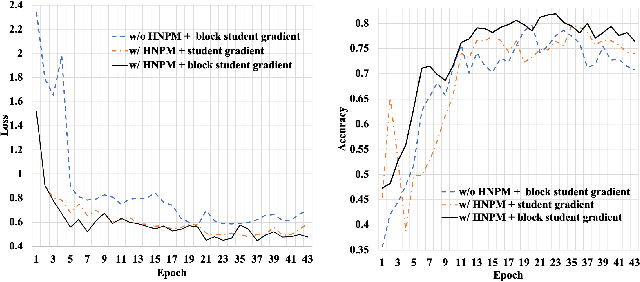
Recently, learning from vast unlabeled data, especially self-supervised learning, has been emerging and attracted widespread attention. Self-supervised learning followed by the supervised fine-tuning on a few labeled examples can significantly improve label efficiency and outperform standard supervised training using fully annotated data. In this work, we present a novel self-supervised deep learning paradigm based on online hard negative pair mining. Specifically, we design a student-teacher network to generate multi-view of the data for self-supervised learning and integrate hard negative pair mining into the training. Then we derive a new triplet-like loss considering both positive sample pairs and mined hard negative sample pairs. Extensive experiments demonstrate the effectiveness of the proposed method and its components on ILSVRC-2012.
Coverage-Guided Tensor Compiler Fuzzing with Joint IR-Pass Mutation
Feb 21, 2022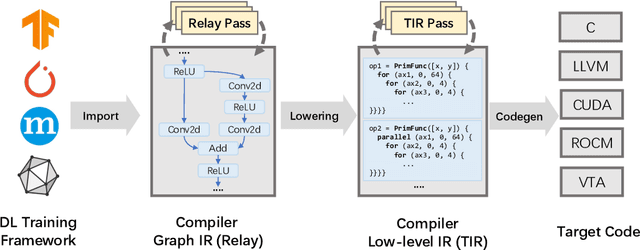
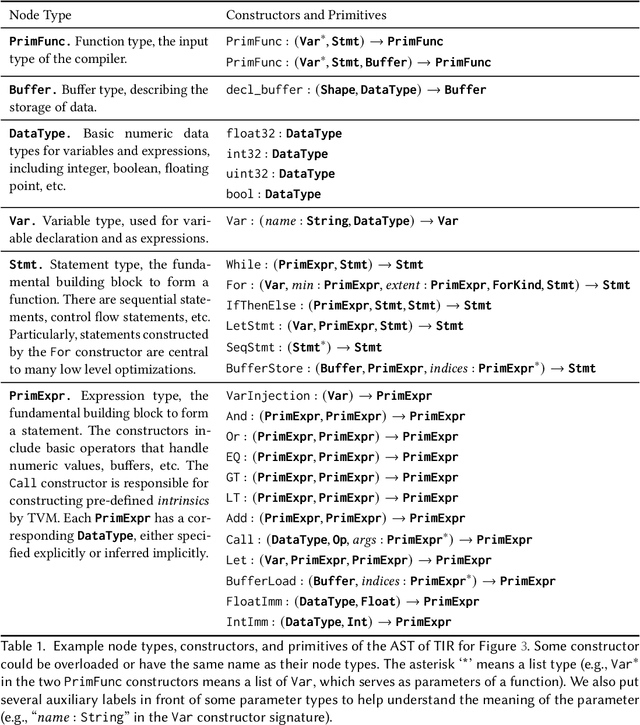
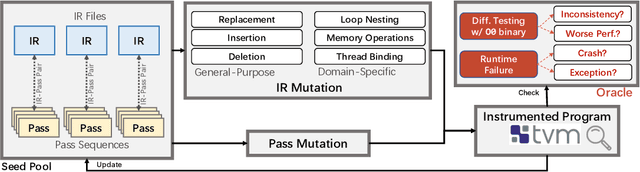
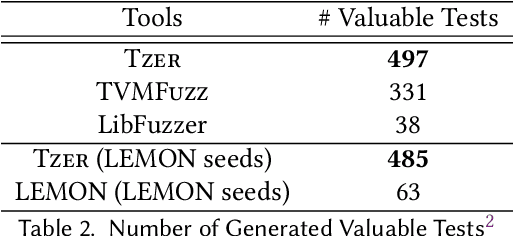
In the past decade, Deep Learning (DL) systems have been widely deployed in various domains to facilitate our daily life. Meanwhile, it is extremely challenging to ensure the correctness of DL systems (e.g., due to their intrinsic nondeterminism), and bugs in DL systems can cause serious consequences and may even threaten human lives. In the literature, researchers have explored various techniques to test, analyze, and verify DL models, since their quality directly affects the corresponding system behaviors. Recently, researchers have also proposed novel techniques for testing the underlying operator-level DL libraries (such as TensorFlow and PyTorch), which provide general binary implementations for each high-level DL operator for running various DL models on many platforms. However, there is still limited work targeting the reliability of the emerging tensor compilers, which aim to directly compile high-level tensor computation graphs into high-performance binaries for better efficiency, portability, and scalability. In this paper, we target the important problem of tensor compiler testing, and have proposed Tzer, a practical fuzzing technique for the widely used TVM tensor compiler. Tzer focuses on mutating the low-level Intermediate Representation (IR) for TVM due to the limited mutation space for the high-level IR. More specifically, Tzer leverages both general-purpose and tensor-compiler-specific mutators guided by coverage feedback for evolutionary IR mutation; furthermore, Tzer also performs pass mutation in tandem with IR mutation for more effective fuzzing. Our results show that Tzer substantially outperforms existing fuzzing techniques on tensor compiler testing, with 75% higher coverage and 50% more valuable tests than the 2nd-best technique. To date, Tzer has detected 49 previously unknown bugs for TVM, with 37 bugs confirmed and 25 bugs fixed (PR merged).
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

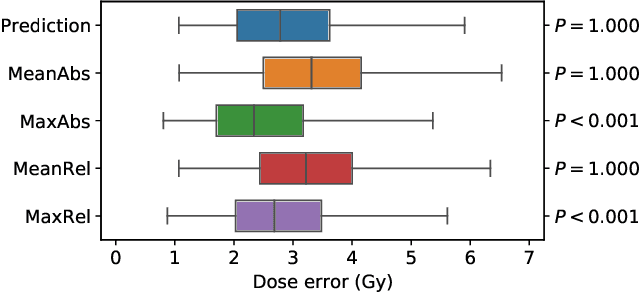
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
Attend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Nov 25, 2021

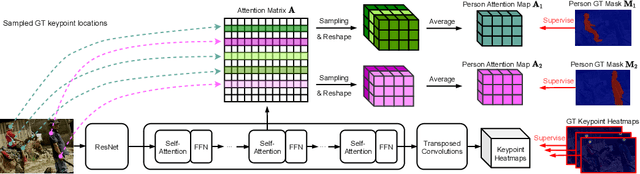
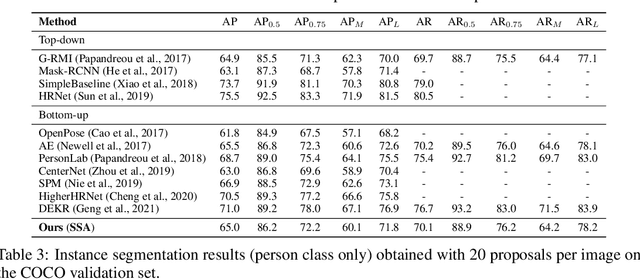
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021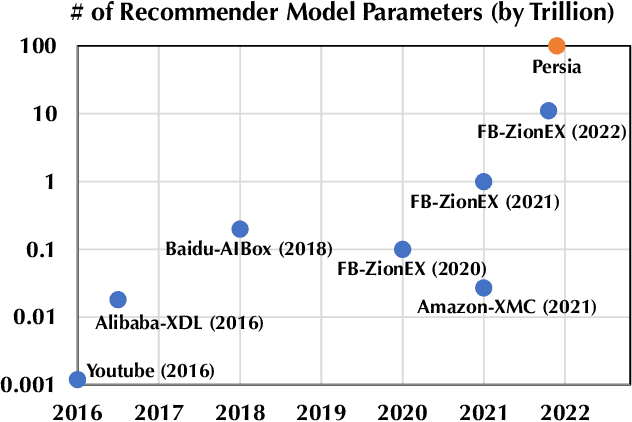
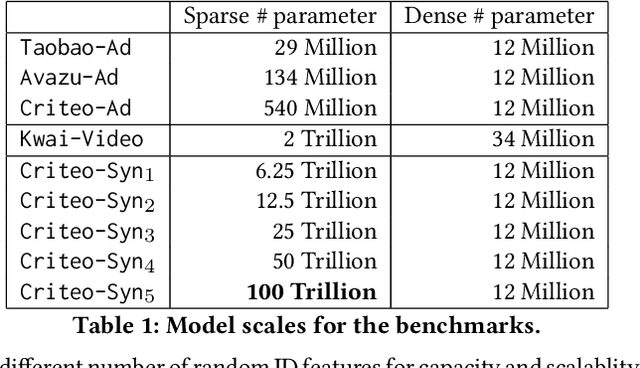
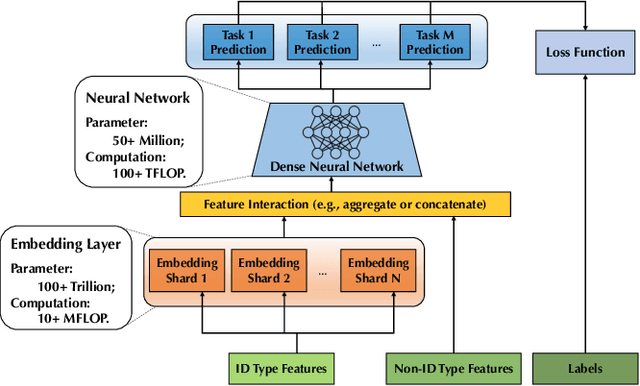
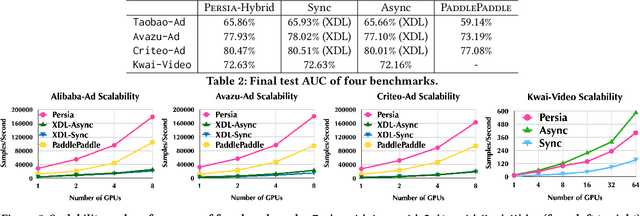
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021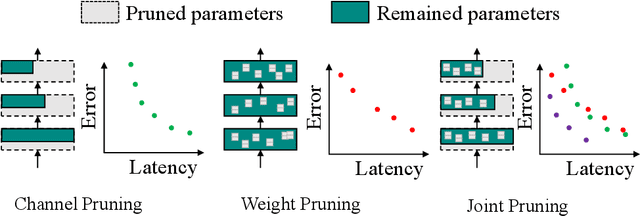
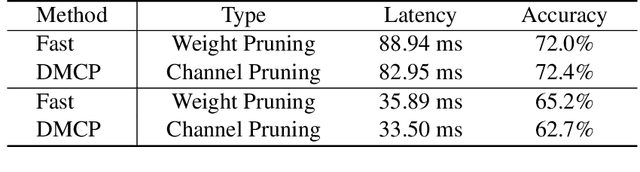
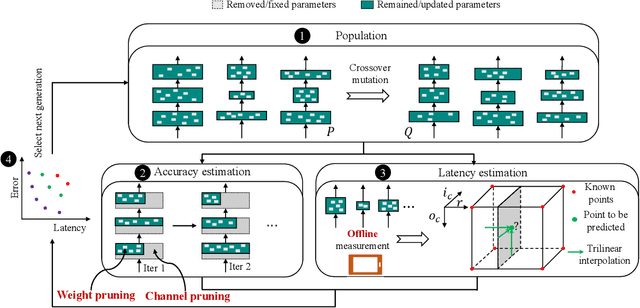
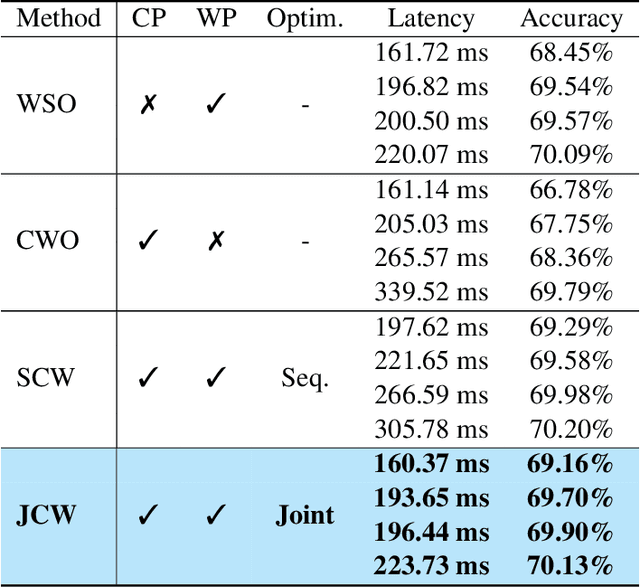
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.