 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUWarp: A Whole Slide Image Registration Pipeline to Characterize Scanner-Induced Local Domain Shift
Mar 26, 2025Histopathology slide digitization introduces scanner-induced domain shift that can significantly impact computational pathology models based on deep learning methods. In the state-of-the-art, this shift is often characterized at a broad scale (slide-level or dataset-level) but not patch-level, which limits our comprehension of the impact of localized tissue characteristics on the accuracy of the deep learning models. To address this challenge, we present a domain shift analysis framework based on UWarp, a novel registration tool designed to accurately align histological slides scanned under varying conditions. UWarp employs a hierarchical registration approach, combining global affine transformations with fine-grained local corrections to achieve robust tissue patch alignment. We evaluate UWarp using two private datasets, CypathLung and BosomShieldBreast, containing whole slide images scanned by multiple devices. Our experiments demonstrate that UWarp outperforms existing open-source registration methods, achieving a median target registration error (TRE) of less than 4 pixels (<1 micrometer at 40x magnification) while significantly reducing computational time. Additionally, we apply UWarp to characterize scanner-induced local domain shift in the predictions of Breast-NEOprAIdict, a deep learning model for breast cancer pathological response prediction. We find that prediction variability is strongly correlated with tissue density on a given patch. Our findings highlight the importance of localized domain shift analysis and suggest that UWarp can serve as a valuable tool for improving model robustness and domain adaptation strategies in computational pathology.
Computer-aided shape features extraction and regression models for predicting the ascending aortic aneurysm growth rate
Mar 04, 2025



Objective: ascending aortic aneurysm growth prediction is still challenging in clinics. In this study, we evaluate and compare the ability of local and global shape features to predict ascending aortic aneurysm growth. Material and methods: 70 patients with aneurysm, for which two 3D acquisitions were available, are included. Following segmentation, three local shape features are computed: (1) the ratio between maximum diameter and length of the ascending aorta centerline, (2) the ratio between the length of external and internal lines on the ascending aorta and (3) the tortuosity of the ascending tract. By exploiting longitudinal data, the aneurysm growth rate is derived. Using radial basis function mesh morphing, iso-topological surface meshes are created. Statistical shape analysis is performed through unsupervised principal component analysis (PCA) and supervised partial least squares (PLS). Two types of global shape features are identified: three PCA-derived and three PLS-based shape modes. Three regression models are set for growth prediction: two based on gaussian support vector machine using local and PCA-derived global shape features; the third is a PLS linear regression model based on the related global shape features. The prediction results are assessed and the aortic shapes most prone to growth are identified. Results: the prediction root mean square error from leave-one-out cross-validation is: 0.112 mm/month, 0.083 mm/month and 0.066 mm/month for local, PCA-based and PLS-derived shape features, respectively. Aneurysms close to the root with a large initial diameter report faster growth. Conclusion: global shape features might provide an important contribution for predicting the aneurysm growth.
Automatic quantification of breast cancer biomarkers from multiple 18F-FDG PET image segmentation
Feb 06, 2025



Neoadjuvant chemotherapy (NAC) has become a standard clinical practice for tumor downsizing in breast cancer with 18F-FDG Positron Emission Tomography (PET). Our work aims to leverage PET imaging for the segmentation of breast lesions. The focus is on developing an automated system that accurately segments primary tumor regions and extracts key biomarkers from these areas to provide insights into the evolution of breast cancer following the first course of NAC. 243 baseline 18F-FDG PET scans (PET_Bl) and 180 follow-up 18F-FDG PET scans (PET_Fu) were acquired before and after the first course of NAC, respectively. Firstly, a deep learning-based breast tumor segmentation method was developed. The optimal baseline model (model trained on baseline exams) was fine-tuned on 15 follow-up exams and adapted using active learning to segment tumor areas in PET_Fu. The pipeline computes biomarkers such as maximum standardized uptake value (SUVmax), metabolic tumor volume (MTV), and total lesion glycolysis (TLG) to evaluate tumor evolution between PET_Fu and PET_Bl. Quality control measures were employed to exclude aberrant outliers. The nnUNet deep learning model outperformed in tumor segmentation on PET_Bl, achieved a Dice similarity coefficient (DSC) of 0.89 and a Hausdorff distance (HD) of 3.52 mm. After fine-tuning, the model demonstrated a DSC of 0.78 and a HD of 4.95 mm on PET_Fu exams. Biomarkers analysis revealed very strong correlations whatever the biomarker between manually segmented and automatically predicted regions. The significant average decrease of SUVmax, MTV and TLG were 5.22, 11.79 cm3 and 19.23 cm3, respectively. The presented approach demonstrates an automated system for breast tumor segmentation from 18F-FDG PET. Thanks to the extracted biomarkers, our method enables the automatic assessment of cancer progression.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Deep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021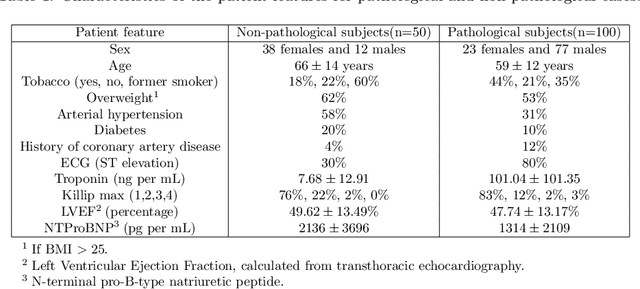

A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
Deep Learning Based Cardiac MRI Segmentation: Do We Need Experts?
Jul 23, 2021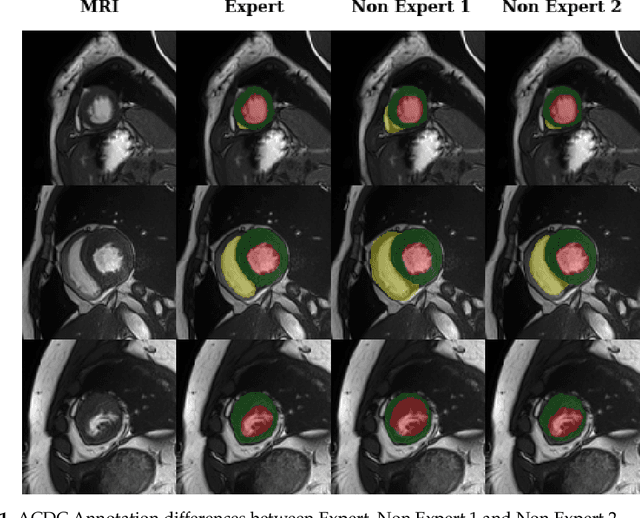
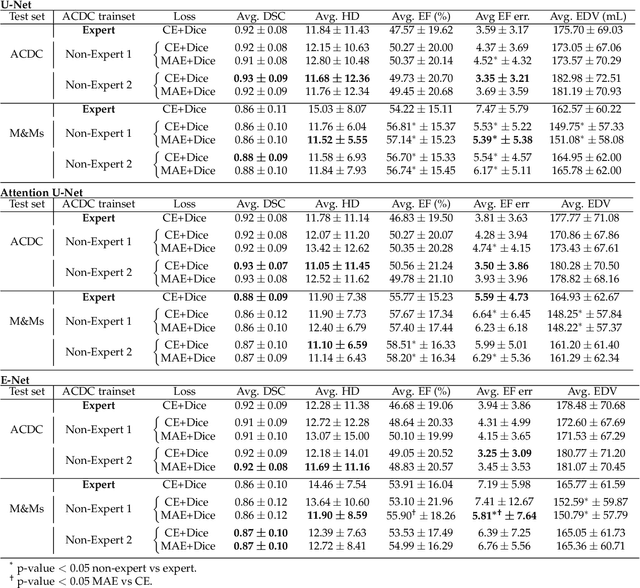
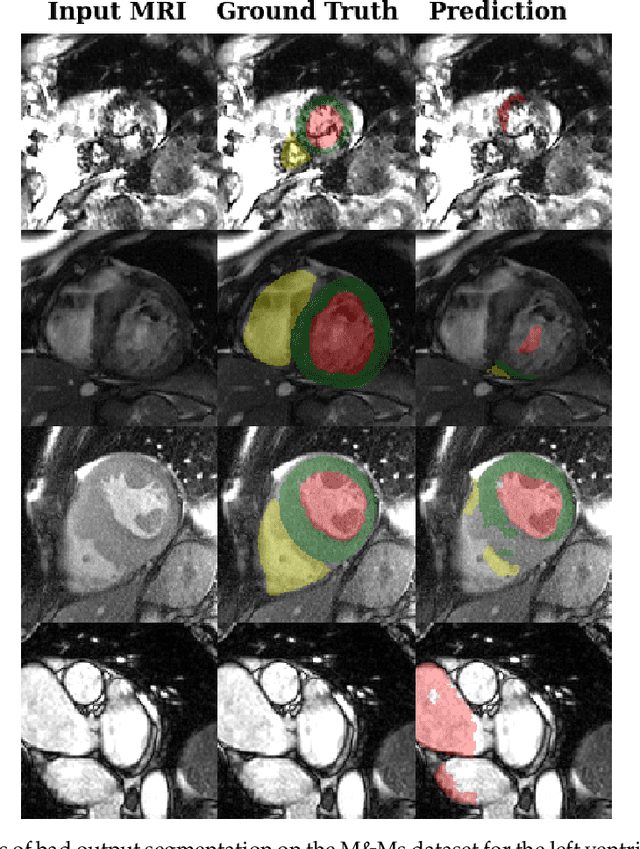
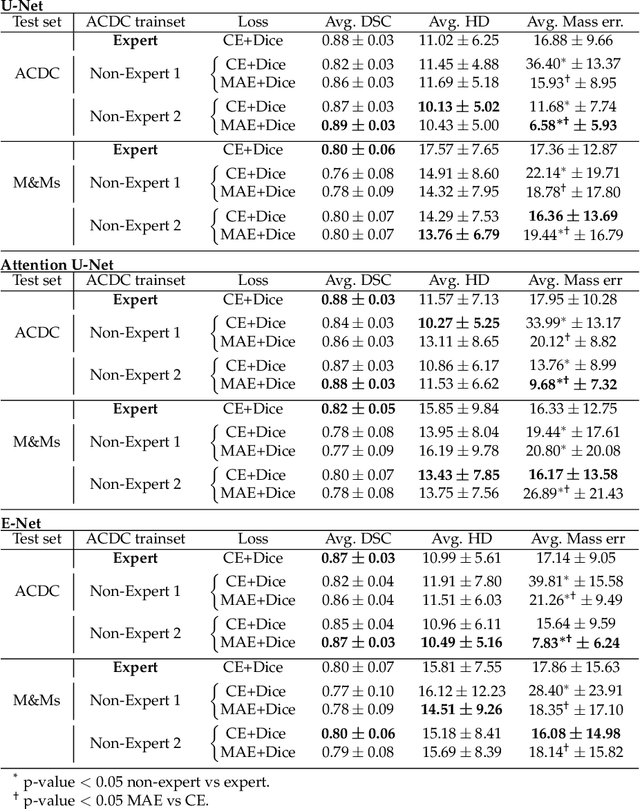
Deep learning methods are the de-facto solutions to a multitude of medical image analysis tasks. Cardiac MRI segmentation is one such application which, like many others, requires a large number of annotated data so a trained network can generalize well. Unfortunately, the process of having a large number of manually curated images by medical experts is both slow and utterly expensive. In this paper, we set out to explore whether expert knowledge is a strict requirement for the creation of annotated datasets that machine learning can successfully train on. To do so, we gauged the performance of three segmentation models, namely U-Net, Attention U-Net, and ENet, trained with different loss functions on expert and non-expert groundtruth for cardiac cine-MRI segmentation. Evaluation was done with classic segmentation metrics (Dice index and Hausdorff distance) as well as clinical measurements, such as the ventricular ejection fractions and the myocardial mass. Results reveal that generalization performances of a segmentation neural network trained on non-expert groundtruth data is, to all practical purposes, as good as on expert groundtruth data, in particular when the non-expert gets a decent level of training, highlighting an opportunity for the efficient and cheap creation of annotations for cardiac datasets.
GANs for Medical Image Synthesis: An Empirical Study
May 11, 2021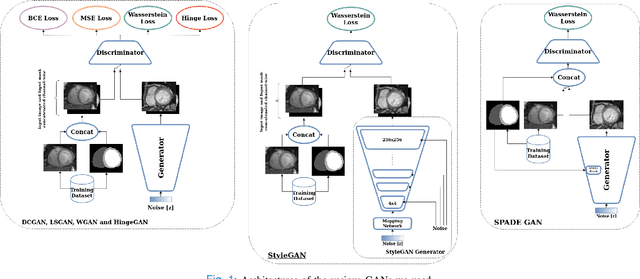
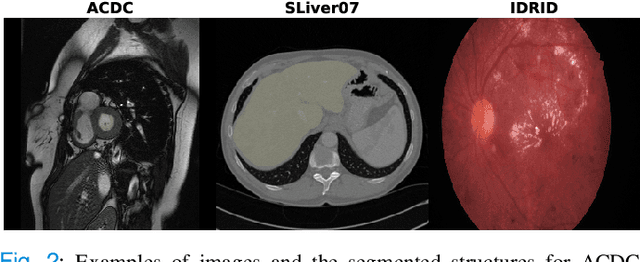
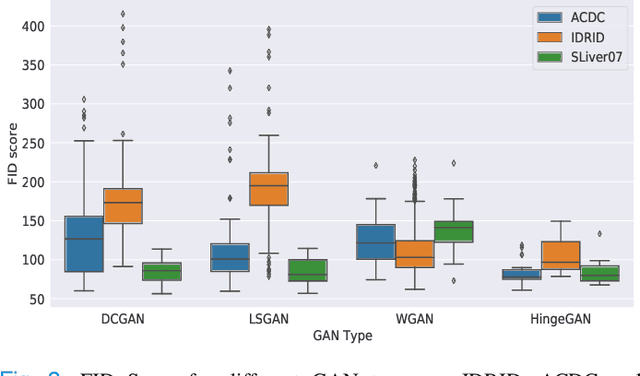
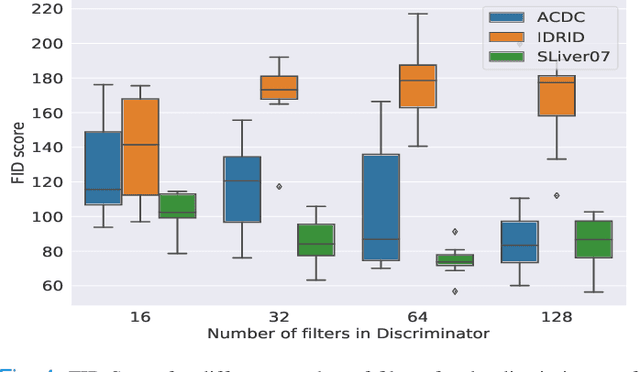
Generative Adversarial Networks (GANs) have become increasingly powerful, generating mind-blowing photorealistic images that mimic the content of datasets they were trained to replicate. One recurrent theme in medical imaging is whether GANs can also be effective at generating workable medical data as they are for generating realistic RGB images. In this paper, we perform a multi-GAN and multi-application study to gauge the benefits of GANs in medical imaging. We tested various GAN architectures from basic DCGAN to more sophisticated style-based GANs on three medical imaging modalities and organs namely : cardiac cine-MRI, liver CT and RGB retina images. GANs were trained on well-known and widely utilized datasets from which their FID score were computed to measure the visual acuity of their generated images. We further tested their usefulness by measuring the segmentation accuracy of a U-Net trained on these generated images. Results reveal that GANs are far from being equal as some are ill-suited for medical imaging applications while others are much better off. The top-performing GANs are capable of generating realistic-looking medical images by FID standards that can fool trained experts in a visual Turing test and comply to some metrics. However, segmentation results suggests that no GAN is capable of reproducing the full richness of a medical datasets.
Learning With Context Feedback Loop for Robust Medical Image Segmentation
Mar 04, 2021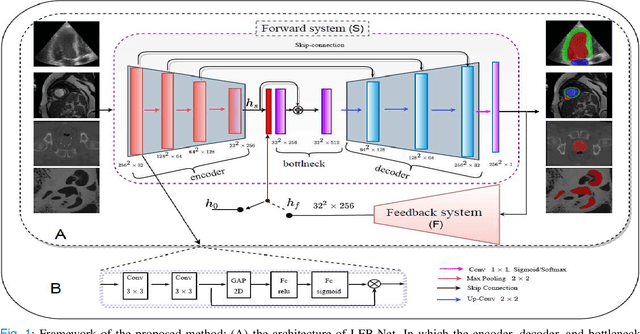
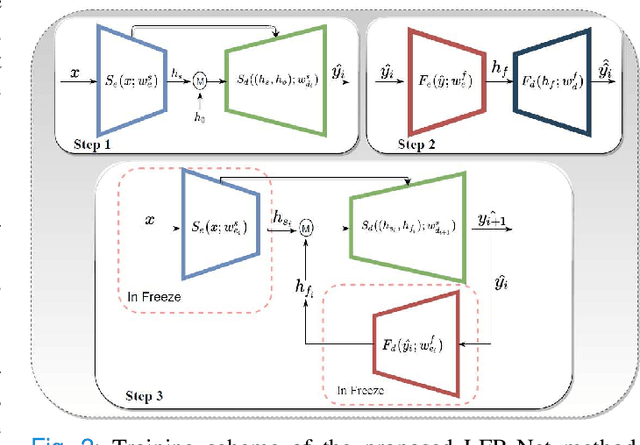
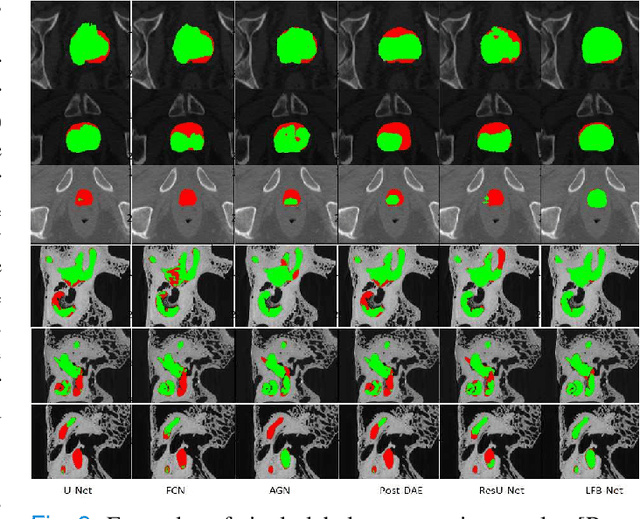
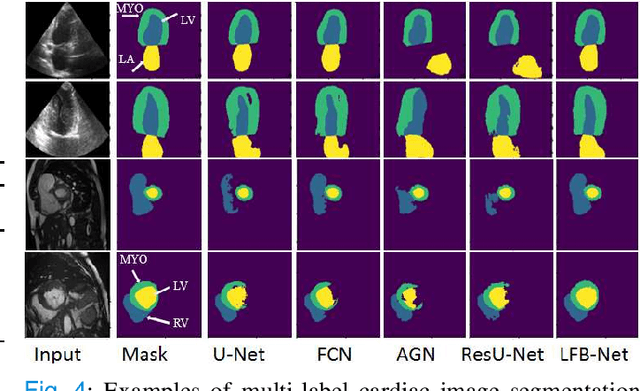
Deep learning has successfully been leveraged for medical image segmentation. It employs convolutional neural networks (CNN) to learn distinctive image features from a defined pixel-wise objective function. However, this approach can lead to less output pixel interdependence producing incomplete and unrealistic segmentation results. In this paper, we present a fully automatic deep learning method for robust medical image segmentation by formulating the segmentation problem as a recurrent framework using two systems. The first one is a forward system of an encoder-decoder CNN that predicts the segmentation result from the input image. The predicted probabilistic output of the forward system is then encoded by a fully convolutional network (FCN)-based context feedback system. The encoded feature space of the FCN is then integrated back into the forward system's feed-forward learning process. Using the FCN-based context feedback loop allows the forward system to learn and extract more high-level image features and fix previous mistakes, thereby improving prediction accuracy over time. Experimental results, performed on four different clinical datasets, demonstrate our method's potential application for single and multi-structure medical image segmentation by outperforming the state of the art methods. With the feedback loop, deep learning methods can now produce results that are both anatomically plausible and robust to low contrast images. Therefore, formulating image segmentation as a recurrent framework of two interconnected networks via context feedback loop can be a potential method for robust and efficient medical image analysis.
Automatic Myocardial Infarction Evaluation from Delayed-Enhancement Cardiac MRI using Deep Convolutional Networks
Oct 30, 2020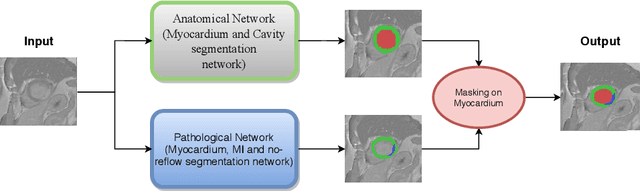

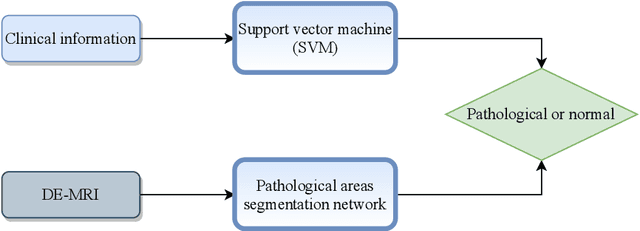
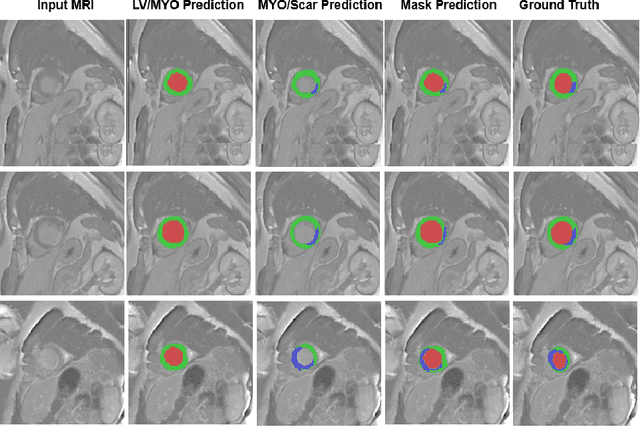
In this paper, we propose a new deep learning framework for an automatic myocardial infarction evaluation from clinical information and delayed enhancement-MRI (DE-MRI). The proposed framework addresses two tasks. The first task is automatic detection of myocardial contours, the infarcted area, the no-reflow area, and the left ventricular cavity from a short-axis DE-MRI series. It employs two segmentation neural networks. The first network is used to segment the anatomical structures such as the myocardium and left ventricular cavity. The second network is used to segment the pathological areas such as myocardial infarction, myocardial no-reflow, and normal myocardial region. The segmented myocardium region from the first network is further used to refine the second network's pathological segmentation results. The second task is to automatically classify a given case into normal or pathological from clinical information with or without DE-MRI. A cascaded support vector machine (SVM) is employed to classify a given case from its associated clinical information. The segmented pathological areas from DE-MRI are also used for the classification task. We evaluated our method on the 2020 EMIDEC MICCAI challenge dataset. It yielded an average Dice index of 0.93 and 0.84, respectively, for the left ventricular cavity and the myocardium. The classification from using only clinical information yielded 80% accuracy over five-fold cross-validation. Using the DE-MRI, our method can classify the cases with 93.3% accuracy. These experimental results reveal that the proposed method can automatically evaluate the myocardial infarction.
Segmentation-free Estimation of Aortic Diameters from MRI Using Deep Learning
Sep 09, 2020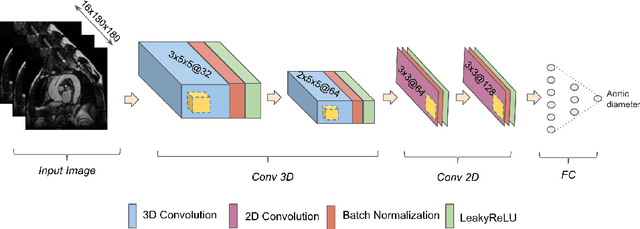
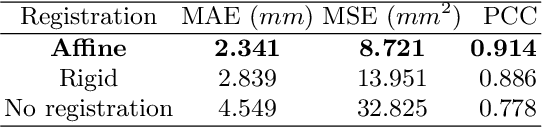
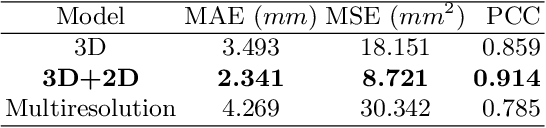
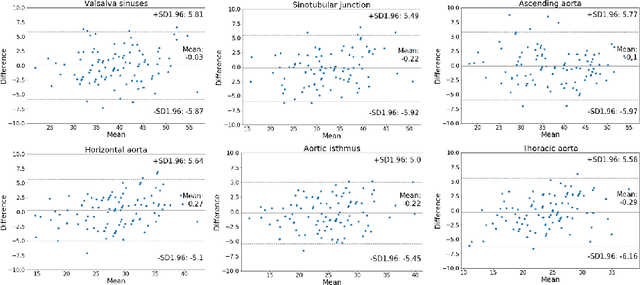
Accurate and reproducible measurements of the aortic diameters are crucial for the diagnosis of cardiovascular diseases and for therapeutic decision making. Currently, these measurements are manually performed by healthcare professionals, being time consuming, highly variable, and suffering from lack of reproducibility. In this work we propose a supervised deep learning method for the direct estimation of aortic diameters. The approach is devised and tested over 100 magnetic resonance angiography scans without contrast agent. All data was expert-annotated at six aortic locations typically used in clinical practice. Our approach makes use of a 3D+2D convolutional neural network (CNN) that takes as input a 3D scan and outputs the aortic diameter at a given location. In a 5-fold cross-validation comparison against a fully 3D CNN and against a 3D multiresolution CNN, our approach was consistently superior in predicting the aortic diameters. Overall, the 3D+2D CNN achieved a mean absolute error between 2.2-2.4 mm depending on the considered aortic location. These errors are less than 1 mm higher than the inter-observer variability. Thus, suggesting that our method makes predictions almost reaching the expert's performance. We conclude that the work allows to further explore automatic algorithms for direct estimation of anatomical structures without the necessity of a segmentation step. It also opens possibilities for the automation of cardiovascular measurements in clinical settings.