 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable modulated differentiable STFT and physics-informed balanced spectrum metric for freight train wheelset bearing cross-machine transfer fault diagnosis under speed fluctuations
Jun 17, 2024



The service conditions of wheelset bearings has a direct impact on the safe operation of railway heavy haul freight trains as the key components. However, speed fluctuation of the trains and few fault samples are the two main problems that restrict the accuracy of bearing fault diagnosis. Therefore, a cross-machine transfer diagnosis (pyDSN) network coupled with interpretable modulated differentiable short-time Fourier transform (STFT) and physics-informed balanced spectrum quality metric is proposed to learn domain-invariant and discriminative features under time-varying speeds. Firstly, due to insufficiency in extracting extract frequency components of time-varying speed signals using fixed windows, a modulated differentiable STFT (MDSTFT) that is interpretable with STFT-informed theoretical support, is proposed to extract the robust time-frequency spectrum (TFS). During training process, multiple windows with different lengths dynamically change. Also, in addition to the classification metric and domain discrepancy metric, we creatively introduce a third kind of metric, referred to as the physics-informed metric, to enhance transferable TFS. A physics-informed balanced spectrum quality (BSQ) regularization loss is devised to guide an optimization direction for MDSTFT and model. With it, not only can model acquire high-quality TFS, but also a physics-restricted domain adaptation network can be also acquired, making it learn real-world physics knowledge, ultimately diminish the domain discrepancy across different datasets. The experiment is conducted in the scenario of migrating from the laboratory datasets to the freight train dataset, indicating that the hybrid-driven pyDSN outperforms existing methods and has practical value.
An optimization method for out-of-distribution anomaly detection models
Feb 02, 2023



Frequent false alarms impede the promotion of unsupervised anomaly detection algorithms in industrial applications. Potential characteristics of false alarms depending on the trained detector are revealed by investigating density probability distributions of prediction scores in the out-of-distribution anomaly detection tasks. An SVM-based classifier is exploited as a post-processing module to identify false alarms from the anomaly map at the object level. Besides, a sample synthesis strategy is devised to incorporate fuzzy prior knowledge on the specific application in the anomaly-free training dataset. Experimental results illustrate that the proposed method comprehensively improves the performances of two segmentation models at both image and pixel levels on two industrial applications.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 12, 2021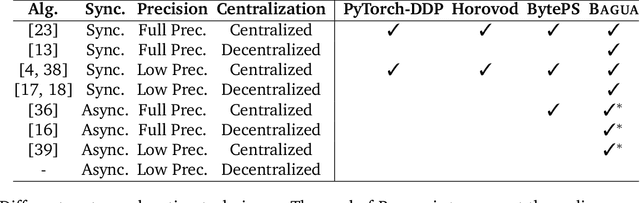
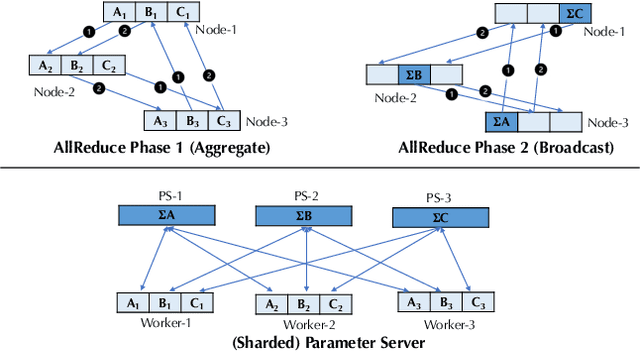
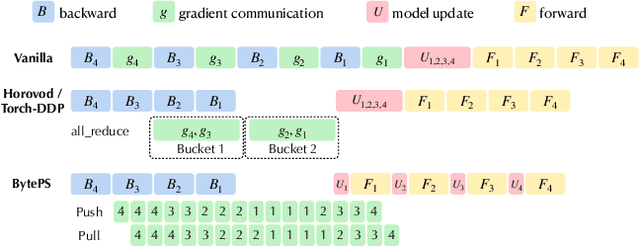

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.