 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose and Shape Estimation from Single Polarization Images
Aug 15, 2021



This paper focuses on a new problem of estimating human pose and shape from single polarization images. Polarization camera is known to be able to capture the polarization of reflected lights that preserves rich geometric cues of an object surface. Inspired by the recent applications in surface normal reconstruction from polarization images, in this paper, we attempt to estimate human pose and shape from single polarization images by leveraging the polarization-induced geometric cues. A dedicated two-stage pipeline is proposed: given a single polarization image, stage one (Polar2Normal) focuses on the fine detailed human body surface normal estimation; stage two (Polar2Shape) then reconstructs clothed human shape from the polarization image and the estimated surface normal. To empirically validate our approach, a dedicated dataset (PHSPD) is constructed, consisting of over 500K frames with accurate pose and shape annotations. Empirical evaluations on this real-world dataset as well as a synthetic dataset, SURREAL, demonstrate the effectiveness of our approach. It suggests polarization camera as a promising alternative to the more conventional RGB camera for human pose and shape estimation.
EventHPE: Event-based 3D Human Pose and Shape Estimation
Aug 15, 2021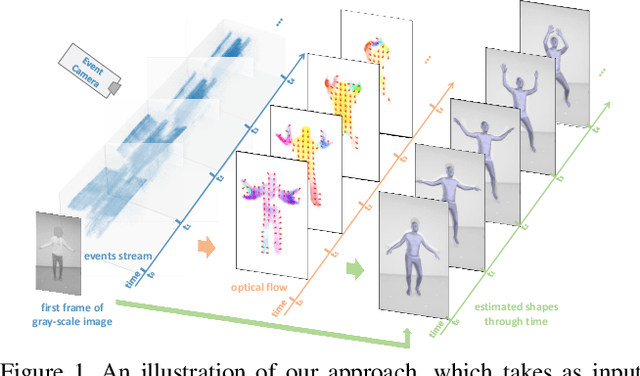

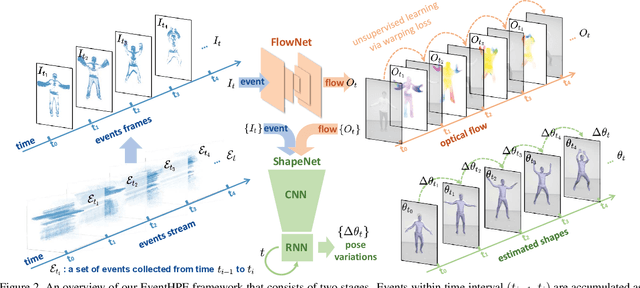
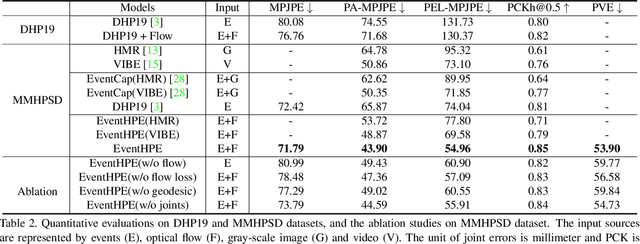
Event camera is an emerging imaging sensor for capturing dynamics of moving objects as events, which motivates our work in estimating 3D human pose and shape from the event signals. Events, on the other hand, have their unique challenges: rather than capturing static body postures, the event signals are best at capturing local motions. This leads us to propose a two-stage deep learning approach, called EventHPE. The first-stage, FlowNet, is trained by unsupervised learning to infer optical flow from events. Both events and optical flow are closely related to human body dynamics, which are fed as input to the ShapeNet in the second stage, to estimate 3D human shapes. To mitigate the discrepancy between image-based flow (optical flow) and shape-based flow (vertices movement of human body shape), a novel flow coherence loss is introduced by exploiting the fact that both flows are originated from the identical human motion. An in-house event-based 3D human dataset is curated that comes with 3D pose and shape annotations, which is by far the largest one to our knowledge. Empirical evaluations on DHP19 dataset and our in-house dataset demonstrate the effectiveness of our approach.
From market-ready ROVs to low-cost AUVs
Aug 12, 2021

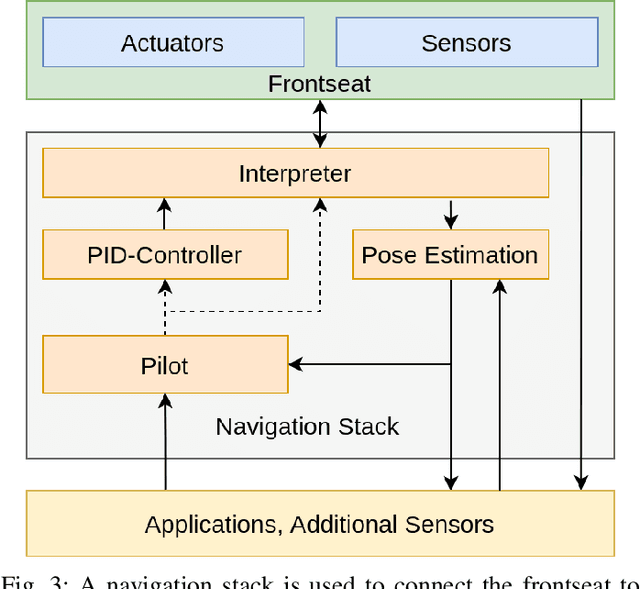

Autonomous Underwater Vehicles (AUVs) are becoming increasingly important for different types of industrial applications. The generally high cost of (AUVs) restricts the access to them and therefore advances in research and technological development. However, recent advances have led to lower cost commercially available Remotely Operated Vehicles (ROVs), which present a platform that can be enhanced to enable a high degree of autonomy, similar to that of a high-end (AUV). In this article, we present how a low-cost commercial-off-the-shelf (ROV) can be used as a foundation for developing versatile and affordable (AUVs). We introduce the required hardware modifications to obtain a system capable of autonomous operations as well as the necessary software modules. Additionally, we present a set of use cases exhibiting the versatility of the developed platform for intervention and mapping tasks.
Detailed Avatar Recovery from Single Image
Aug 06, 2021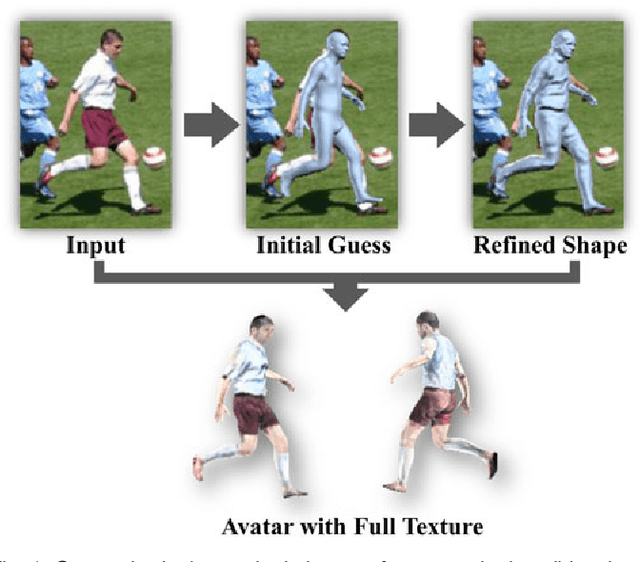
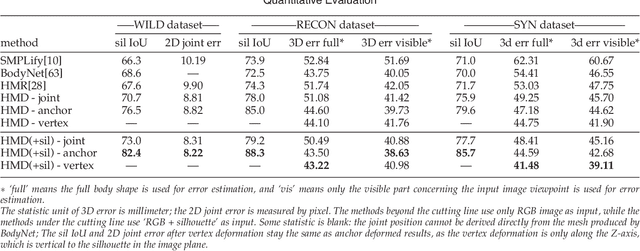
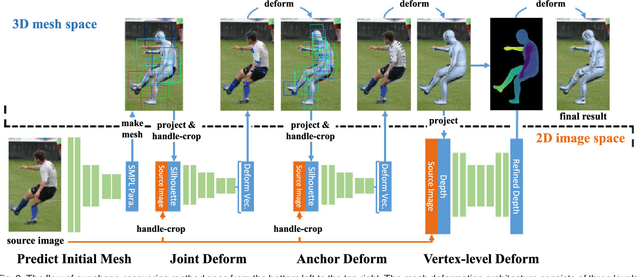
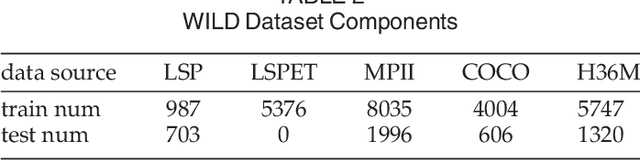
This paper presents a novel framework to recover \emph{detailed} avatar from a single image. It is a challenging task due to factors such as variations in human shapes, body poses, texture, and viewpoints. Prior methods typically attempt to recover the human body shape using a parametric-based template that lacks the surface details. As such resulting body shape appears to be without clothing. In this paper, we propose a novel learning-based framework that combines the robustness of the parametric model with the flexibility of free-form 3D deformation. We use the deep neural networks to refine the 3D shape in a Hierarchical Mesh Deformation (HMD) framework, utilizing the constraints from body joints, silhouettes, and per-pixel shading information. Our method can restore detailed human body shapes with complete textures beyond skinned models. Experiments demonstrate that our method has outperformed previous state-of-the-art approaches, achieving better accuracy in terms of both 2D IoU number and 3D metric distance.
Object Wake-up: 3-D Object Reconstruction, Animation, and in-situ Rendering from a Single Image
Aug 05, 2021

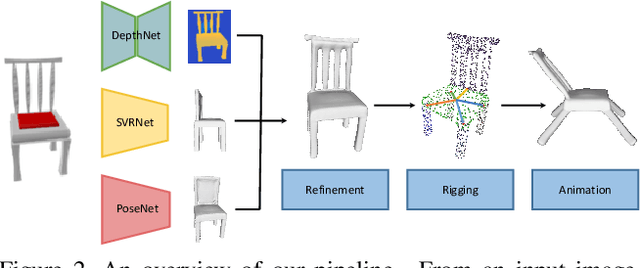
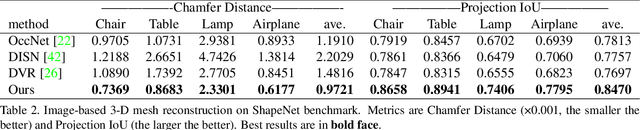
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.
Underwater inspection and intervention dataset
Jul 28, 2021
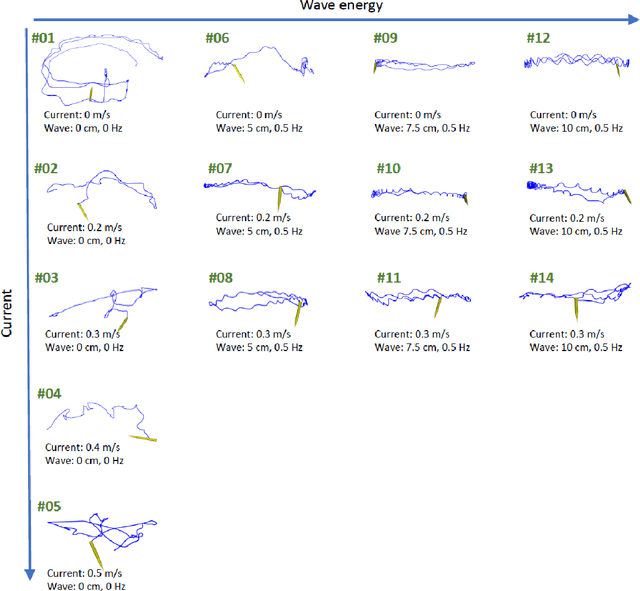
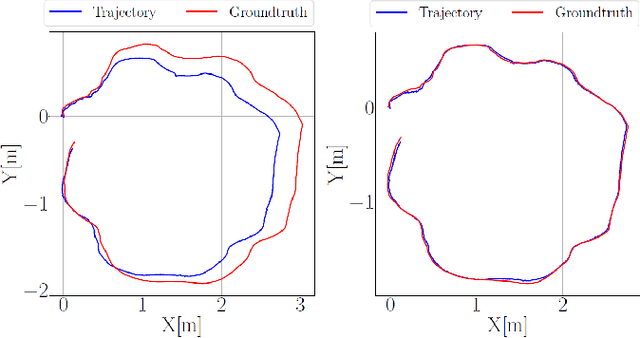

This paper presents a novel dataset for the development of visual navigation and simultaneous localisation and mapping (SLAM) algorithms as well as for underwater intervention tasks. It differs from existing datasets as it contains ground truth for the vehicle's position captured by an underwater motion tracking system. The dataset contains distortion-free and rectified stereo images along with the calibration parameters of the stereo camera setup. Furthermore, the experiments were performed and recorded in a controlled environment, where current and waves could be generated allowing the dataset to cover a wide range of conditions - from calm water to waves and currents of significant strength.
MIMO: Mutual Integration of Patient Journey and Medical Ontology for Healthcare Representation Learning
Jul 23, 2021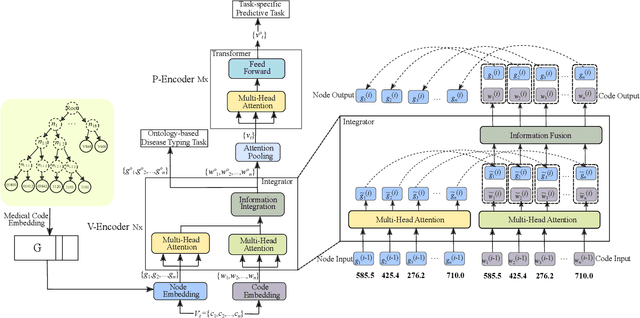
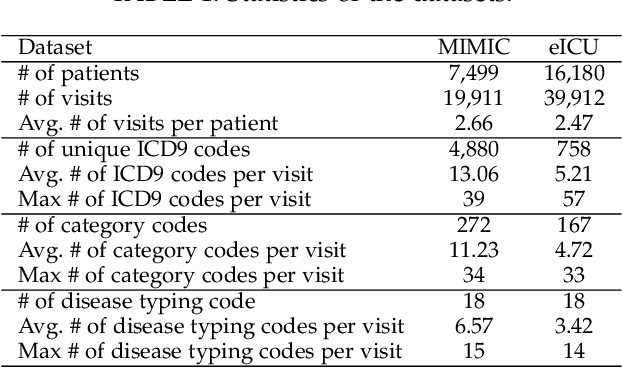
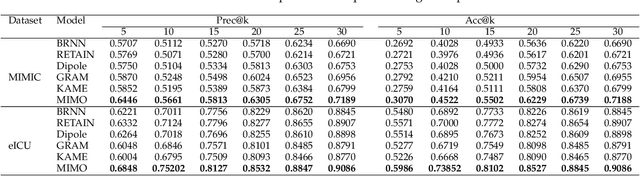
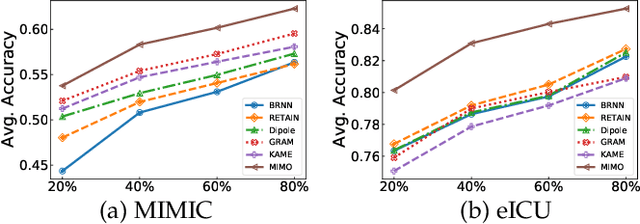
Healthcare representation learning on the Electronic Health Record (EHR) is seen as crucial for predictive analytics in the medical field. Many natural language processing techniques, such as word2vec, RNN and self-attention, have been adapted for use in hierarchical and time stamped EHR data, but fail when they lack either general or task-specific data. Hence, some recent works train healthcare representations by incorporating medical ontology (a.k.a. knowledge graph), by self-supervised tasks like diagnosis prediction, but (1) the small-scale, monotonous ontology is insufficient for robust learning, and (2) critical contexts or dependencies underlying patient journeys are never exploited to enhance ontology learning. To address this, we propose an end-to-end robust Transformer-based solution, Mutual Integration of patient journey and Medical Ontology (MIMO) for healthcare representation learning and predictive analytics. Specifically, it consists of task-specific representation learning and graph-embedding modules to learn both patient journey and medical ontology interactively. Consequently, this creates a mutual integration to benefit both healthcare representation learning and medical ontology embedding. Moreover, such integration is achieved by a joint training of both task-specific predictive and ontology-based disease typing tasks based on fused embeddings of the two modules. Experiments conducted on two real-world diagnosis prediction datasets show that, our healthcare representation model MIMO not only achieves better predictive results than previous state-of-the-art approaches regardless of sufficient or insufficient training data, but also derives more interpretable embeddings of diagnoses.
Unsupervised 3D Human Mesh Recovery from Noisy Point Clouds
Jul 15, 2021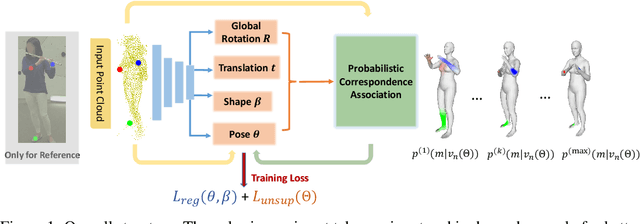
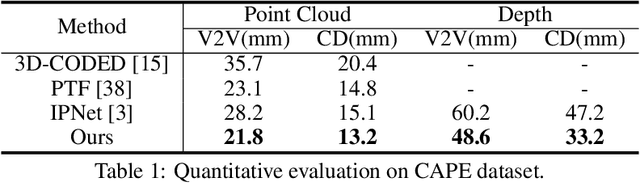
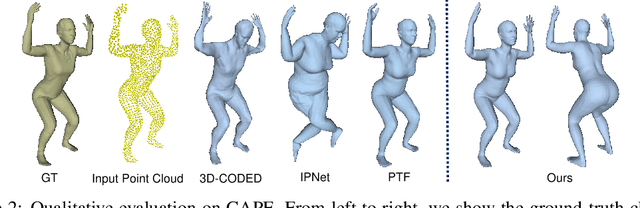
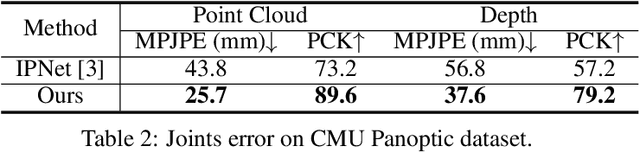
This paper presents a novel unsupervised approach to reconstruct human shape and pose from noisy point cloud. Traditional approaches search for correspondences and conduct model fitting iteratively where a good initialization is critical. Relying on large amount of dataset with ground-truth annotations, recent learning-based approaches predict correspondences for every vertice on the point cloud; Chamfer distance is usually used to minimize the distance between a deformed template model and the input point cloud. However, Chamfer distance is quite sensitive to noise and outliers, thus could be unreliable to assign correspondences. To address these issues, we model the probability distribution of the input point cloud as generated from a parametric human model under a Gaussian Mixture Model. Instead of explicitly aligning correspondences, we treat the process of correspondence search as an implicit probabilistic association by updating the posterior probability of the template model given the input. A novel unsupervised loss is further derived that penalizes the discrepancy between the deformed template and the input point cloud conditioned on the posterior probability. Our approach is very flexible, which works with both complete point cloud and incomplete ones including even a single depth image as input. Our network is trained from scratch with no need to warm-up the network with supervised data. Compared to previous unsupervised methods, our method shows the capability to deal with substantial noise and outliers. Extensive experiments conducted on various public synthetic datasets as well as a very noisy real dataset (i.e. CMU Panoptic) demonstrate the superior performance of our approach over the state-of-the-art methods. Code can be found \url{https://github.com/wangsen1312/unsupervised3dhuman.git}
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 13, 2021
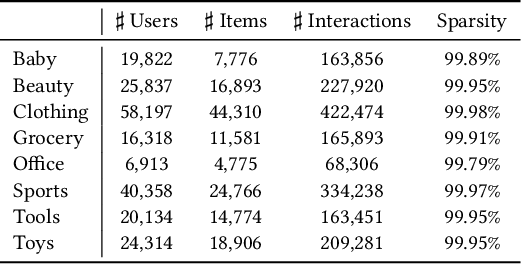
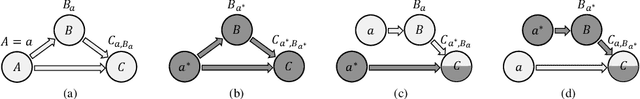
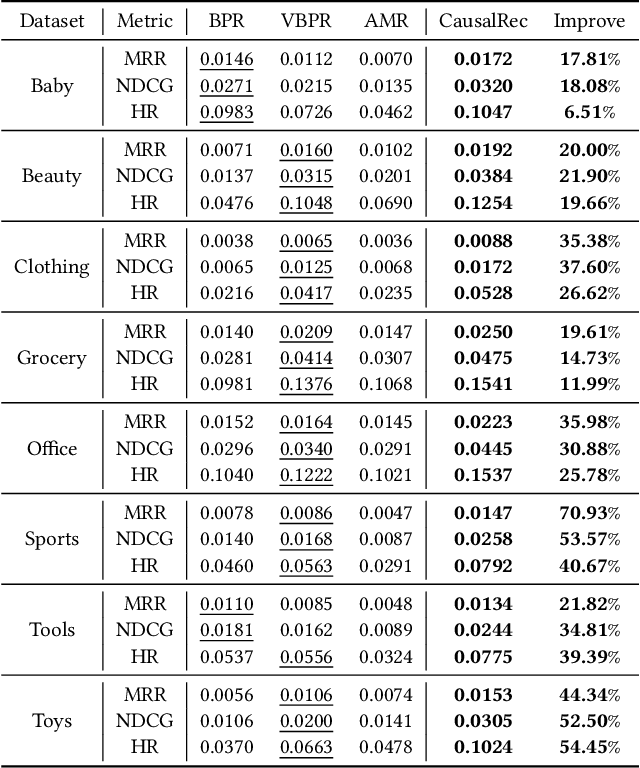
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.
Mitigating Generation Shifts for Generalized Zero-Shot Learning
Jul 07, 2021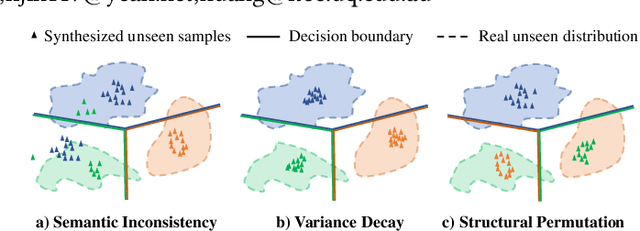
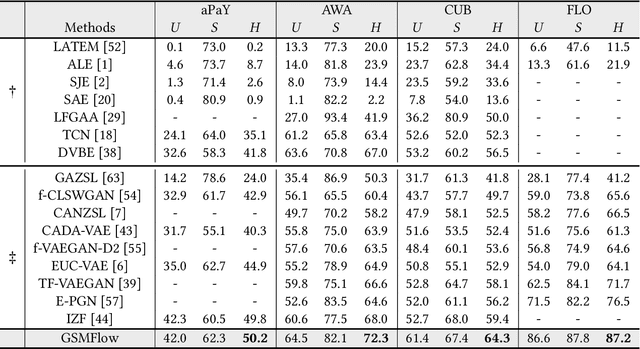
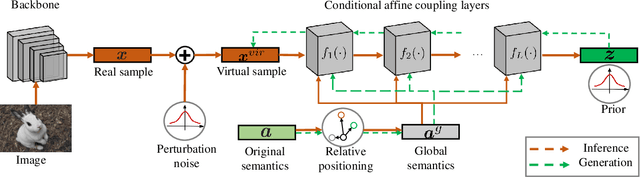
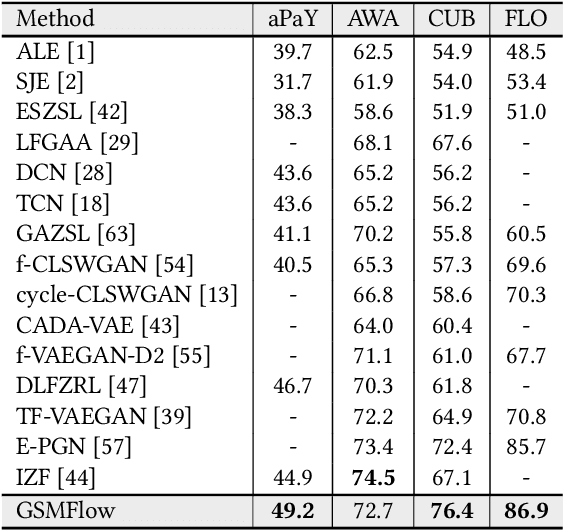
Generalized Zero-Shot Learning (GZSL) is the task of leveraging semantic information (e.g., attributes) to recognize the seen and unseen samples, where unseen classes are not observable during training. It is natural to derive generative models and hallucinate training samples for unseen classes based on the knowledge learned from the seen samples. However, most of these models suffer from the `generation shifts', where the synthesized samples may drift from the real distribution of unseen data. In this paper, we conduct an in-depth analysis on this issue and propose a novel Generation Shifts Mitigating Flow (GSMFlow) framework, which is comprised of multiple conditional affine coupling layers for learning unseen data synthesis efficiently and effectively. In particular, we identify three potential problems that trigger the generation shifts, i.e., semantic inconsistency, variance decay, and structural permutation and address them respectively. First, to reinforce the correlations between the generated samples and the respective attributes, we explicitly embed the semantic information into the transformations in each of the coupling layers. Second, to recover the intrinsic variance of the synthesized unseen features, we introduce a visual perturbation strategy to diversify the intra-class variance of generated data and hereby help adjust the decision boundary of the classifier. Third, to avoid structural permutation in the semantic space, we propose a relative positioning strategy to manipulate the attribute embeddings, guiding which to fully preserve the inter-class geometric structure. Experimental results demonstrate that GSMFlow achieves state-of-the-art recognition performance in both conventional and generalized zero-shot settings. Our code is available at: https://github.com/uqzhichen/GSMFlow