 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Primitive-Sharing Ambiguity in Long-Tailed Industrial Point Cloud Segmentation via Spatial Context Constraints
Jan 27, 2026Industrial point cloud segmentation for Digital Twin construction faces a persistent challenge: safety-critical components such as reducers and valves are systematically misclassified. These failures stem from two compounding factors: such components are rare in training data, yet they share identical local geometry with dominant structures like pipes. This work identifies a dual crisis unique to industrial 3D data extreme class imbalance 215:1 ratio compounded by geometric ambiguity where most tail classes share cylindrical primitives with head classes. Existing frequency-based re-weighting methods address statistical imbalance but cannot resolve geometric ambiguity. We propose spatial context constraints that leverage neighborhood prediction consistency to disambiguate locally similar structures. Our approach extends the Class-Balanced (CB) Loss framework with two architecture-agnostic mechanisms: (1) Boundary-CB, an entropy-based constraint that emphasizes ambiguous boundaries, and (2) Density-CB, a density-based constraint that compensates for scan-dependent variations. Both integrate as plug-and-play modules without network modifications, requiring only loss function replacement. On the Industrial3D dataset (610M points from water treatment facilities), our method achieves 55.74% mIoU with 21.7% relative improvement on tail-class performance (29.59% vs. 24.32% baseline) while preserving head-class accuracy (88.14%). Components with primitive-sharing ambiguity show dramatic gains: reducer improves from 0% to 21.12% IoU; valve improves by 24.3% relative. This resolves geometric ambiguity without the typical head-tail trade-off, enabling reliable identification of safety-critical components for automated knowledge extraction in Digital Twin applications.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Two-Stage Gaussian Process Regression Via Automatic Kernel Search and Subsampling
May 22, 2024Gaussian Process Regression (GPR) is widely used in statistics and machine learning for prediction tasks requiring uncertainty measures. Its efficacy depends on the appropriate specification of the mean function, covariance kernel function, and associated hyperparameters. Severe misspecifications can lead to inaccurate results and problematic consequences, especially in safety-critical applications. However, a systematic approach to handle these misspecifications is lacking in the literature. In this work, we propose a general framework to address these issues. Firstly, we introduce a flexible two-stage GPR framework that separates mean prediction and uncertainty quantification (UQ) to prevent mean misspecification, which can introduce bias into the model. Secondly, kernel function misspecification is addressed through a novel automatic kernel search algorithm, supported by theoretical analysis, that selects the optimal kernel from a candidate set. Additionally, we propose a subsampling-based warm-start strategy for hyperparameter initialization to improve efficiency and avoid hyperparameter misspecification. With much lower computational cost, our subsampling-based strategy can yield competitive or better performance than training exclusively on the full dataset. Combining all these components, we recommend two GPR methods-exact and scalable-designed to match available computational resources and specific UQ requirements. Extensive evaluation on real-world datasets, including UCI benchmarks and a safety-critical medical case study, demonstrates the robustness and precision of our methods.
Feature CAM: Interpretable AI in Image Classification
Mar 08, 2024



Deep Neural Networks have often been called the black box because of the complex, deep architecture and non-transparency presented by the inner layers. There is a lack of trust to use Artificial Intelligence in critical and high-precision fields such as security, finance, health, and manufacturing industries. A lot of focused work has been done to provide interpretable models, intending to deliver meaningful insights into the thoughts and behavior of neural networks. In our research, we compare the state-of-the-art methods in the Activation-based methods (ABM) for interpreting predictions of CNN models, specifically in the application of Image Classification. We then extend the same for eight CNN-based architectures to compare the differences in visualization and thus interpretability. We introduced a novel technique Feature CAM, which falls in the perturbation-activation combination, to create fine-grained, class-discriminative visualizations. The resulting saliency maps from our experiments proved to be 3-4 times better human interpretable than the state-of-the-art in ABM. At the same time it reserves machine interpretability, which is the average confidence scores in classification.
3D Pose Estimation and Future Motion Prediction from 2D Images
Nov 26, 2021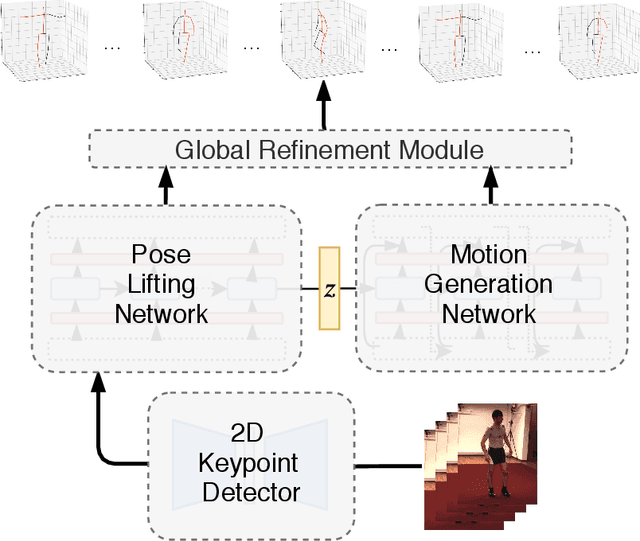
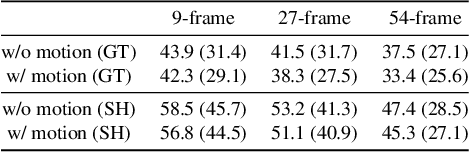

This paper considers to jointly tackle the highly correlated tasks of estimating 3D human body poses and predicting future 3D motions from RGB image sequences. Based on Lie algebra pose representation, a novel self-projection mechanism is proposed that naturally preserves human motion kinematics. This is further facilitated by a sequence-to-sequence multi-task architecture based on an encoder-decoder topology, which enables us to tap into the common ground shared by both tasks. Finally, a global refinement module is proposed to boost the performance of our framework. The effectiveness of our approach, called PoseMoNet, is demonstrated by ablation tests and empirical evaluations on Human3.6M and HumanEva-I benchmark, where competitive performance is obtained comparing to the state-of-the-arts.
Toward Annotator Group Bias in Crowdsourcing
Oct 08, 2021
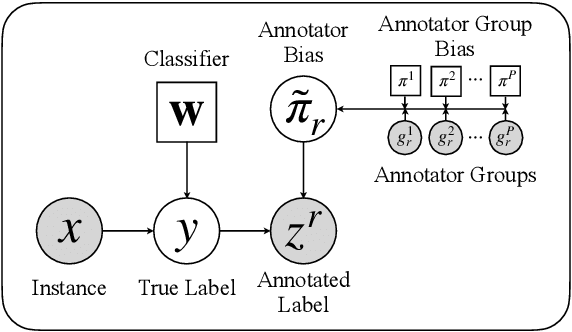

Crowdsourcing has emerged as a popular approach for collecting annotated data to train supervised machine learning models. However, annotator bias can lead to defective annotations. Though there are a few works investigating individual annotator bias, the group effects in annotators are largely overlooked. In this work, we reveal that annotators within the same demographic group tend to show consistent group bias in annotation tasks and thus we conduct an initial study on annotator group bias. We first empirically verify the existence of annotator group bias in various real-world crowdsourcing datasets. Then, we develop a novel probabilistic graphical framework GroupAnno to capture annotator group bias with a new extended Expectation Maximization (EM) training algorithm. We conduct experiments on both synthetic and real-world datasets. Experimental results demonstrate the effectiveness of our model in modeling annotator group bias in label aggregation and model learning over competitive baselines.
Dive into Layers: Neural Network Capacity Bounding using Algebraic Geometry
Sep 03, 2021
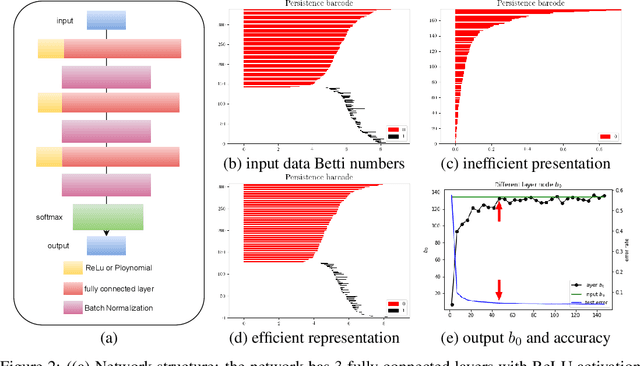
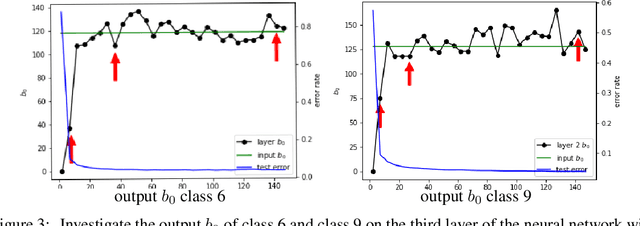
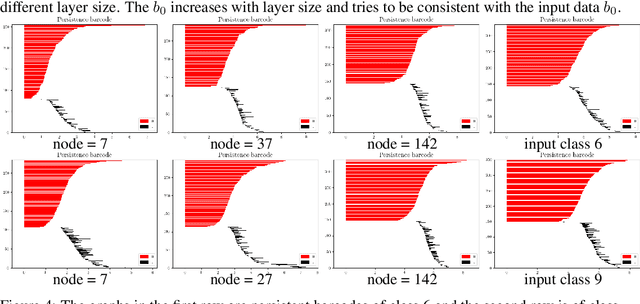
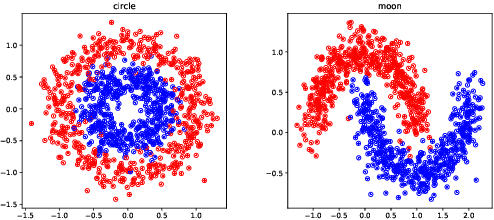
The empirical results suggest that the learnability of a neural network is directly related to its size. To mathematically prove this, we borrow a tool in topological algebra: Betti numbers to measure the topological geometric complexity of input data and the neural network. By characterizing the expressive capacity of a neural network with its topological complexity, we conduct a thorough analysis and show that the network's expressive capacity is limited by the scale of its layers. Further, we derive the upper bounds of the Betti numbers on each layer within the network. As a result, the problem of architecture selection of a neural network is transformed to determining the scale of the network that can represent the input data complexity. With the presented results, the architecture selection of a fully connected network boils down to choosing a suitable size of the network such that it equips the Betti numbers that are not smaller than the Betti numbers of the input data. We perform the experiments on a real-world dataset MNIST and the results verify our analysis and conclusion. The code will be publicly available.
Object Wake-up: 3-D Object Reconstruction, Animation, and in-situ Rendering from a Single Image
Aug 05, 2021

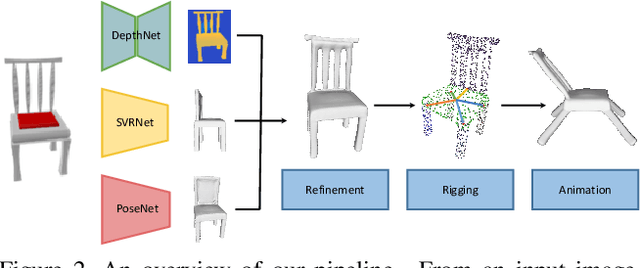
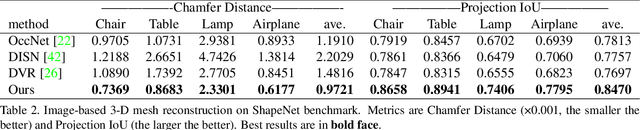
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.
Cuid: A new study of perceived image quality and its subjective assessment
Sep 28, 2020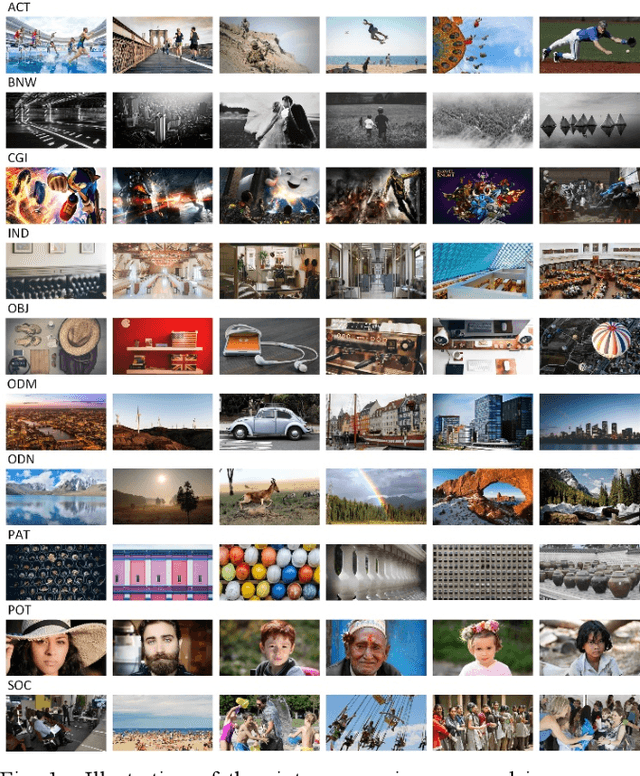


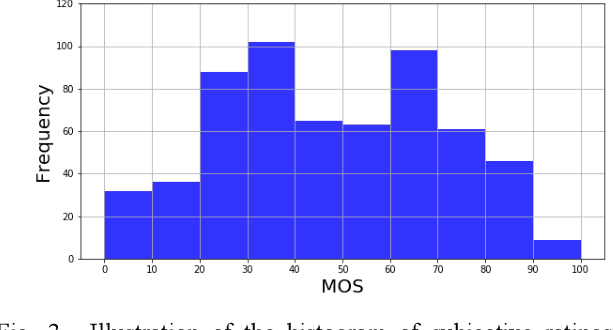
Research on image quality assessment (IQA) remains limited mainly due to our incomplete knowledge about human visual perception. Existing IQA algorithms have been designed or trained with insufficient subjective data with a small degree of stimulus variability. This has led to challenges for those algorithms to handle complexity and diversity of real-world digital content. Perceptual evidence from human subjects serves as a grounding for the development of advanced IQA algorithms. It is thus critical to acquire reliable subjective data with controlled perception experiments that faithfully reflect human behavioural responses to distortions in visual signals. In this paper, we present a new study of image quality perception where subjective ratings were collected in a controlled lab environment. We investigate how quality perception is affected by a combination of different categories of images and different types and levels of distortions. The database will be made publicly available to facilitate calibration and validation of IQA algorithms.
IVUS-Net: An Intravascular Ultrasound Segmentation Network
Jun 14, 2018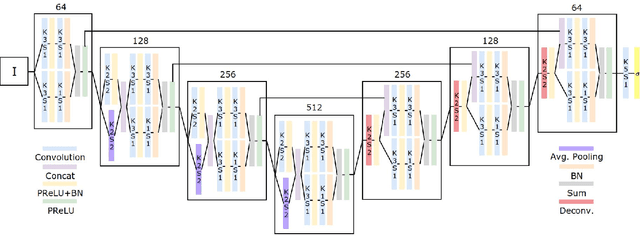
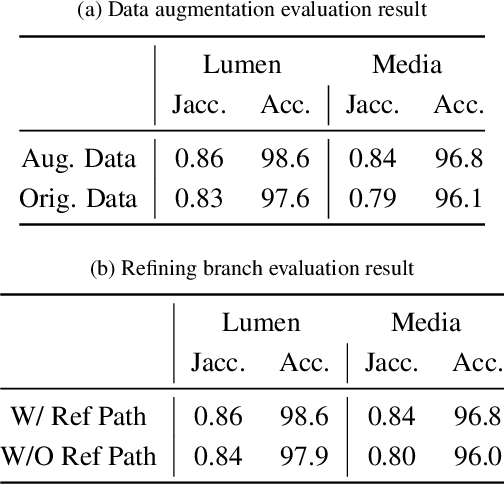
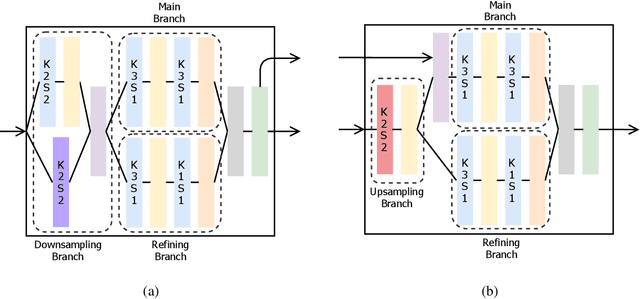
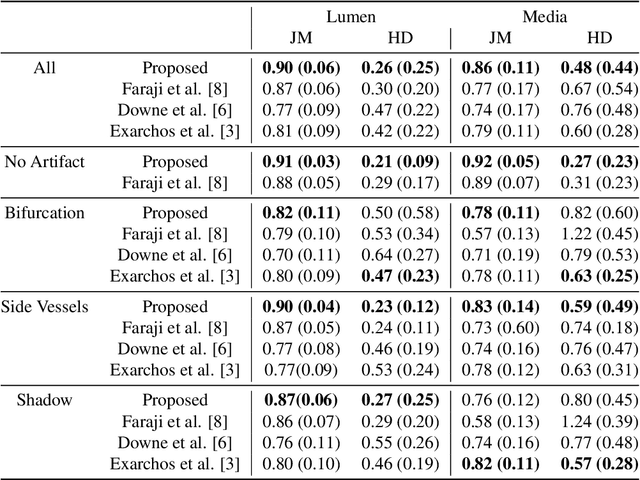
IntraVascular UltraSound (IVUS) is one of the most effective imaging modalities that provides assistance to experts in order to diagnose and treat cardiovascular diseases. We address a central problem in IVUS image analysis with Fully Convolutional Network (FCN): automatically delineate the lumen and media-adventitia borders in IVUS images, which is crucial to shorten the diagnosis process or benefits a faster and more accurate 3D reconstruction of the artery. Particularly, we propose an FCN architecture, called IVUS-Net, followed by a post-processing contour extraction step, in order to automatically segments the interior (lumen) and exterior (media-adventitia) regions of the human arteries. We evaluated our IVUS-Net on the test set of a standard publicly available dataset containing 326 IVUS B-mode images with two measurements, namely Jaccard Measure (JM) and Hausdorff Distances (HD). The evaluation result shows that IVUS-Net outperforms the state-of-the-art lumen and media segmentation methods by 4% to 20% in terms of HD distance. IVUS-Net performs well on images in the test set that contain a significant amount of major artifacts such as bifurcations, shadows, and side branches that are not common in the training set. Furthermore, using a modern GPU, IVUS-Net segments each IVUS frame only in 0.15 seconds. The proposed work, to the best of our knowledge, is the first deep learning based method for segmentation of both the lumen and the media vessel walls in 20 MHz IVUS B-mode images that achieves the best results without any manual intervention. Code is available at https://github.com/Kulbear/ivus-segmentation-icsm2018