 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Judge: Rapid Evaluation of Legal Document Recommendation for Retrieval-Augmented Generation
Sep 15, 2025The evaluation bottleneck in recommendation systems has become particularly acute with the rise of Generative AI, where traditional metrics fall short of capturing nuanced quality dimensions that matter in specialized domains like legal research. Can we trust Large Language Models to serve as reliable judges of their own kind? This paper investigates LLM-as-a-Judge as a principled approach to evaluating Retrieval-Augmented Generation systems in legal contexts, where the stakes of recommendation quality are exceptionally high. We tackle two fundamental questions that determine practical viability: which inter-rater reliability metrics best capture the alignment between LLM and human assessments, and how do we conduct statistically sound comparisons between competing systems? Through systematic experimentation, we discover that traditional agreement metrics like Krippendorff's alpha can be misleading in the skewed distributions typical of AI system evaluations. Instead, Gwet's AC2 and rank correlation coefficients emerge as more robust indicators for judge selection, while the Wilcoxon Signed-Rank Test with Benjamini-Hochberg corrections provides the statistical rigor needed for reliable system comparisons. Our findings suggest a path toward scalable, cost-effective evaluation that maintains the precision demanded by legal applications, transforming what was once a human-intensive bottleneck into an automated, yet statistically principled, evaluation framework.
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Jul 20, 2024



Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
Mobile Manipulation Leveraging Multiple Views
Oct 02, 2021
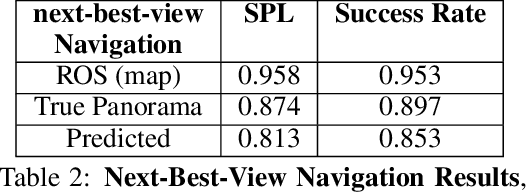

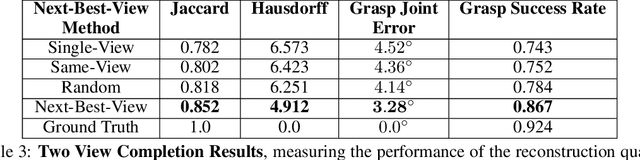
While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.
Image to Language Understanding: Captioning approach
Feb 21, 2020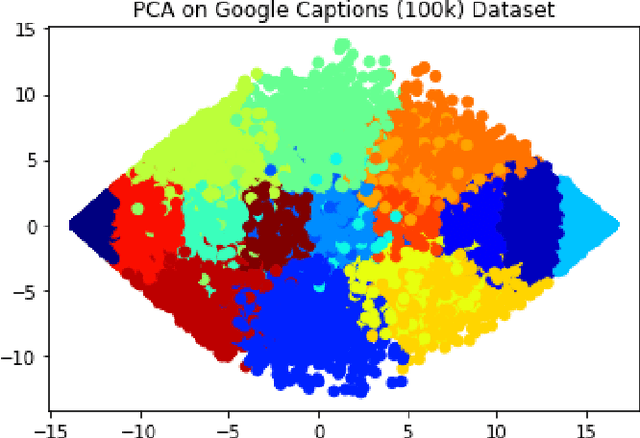
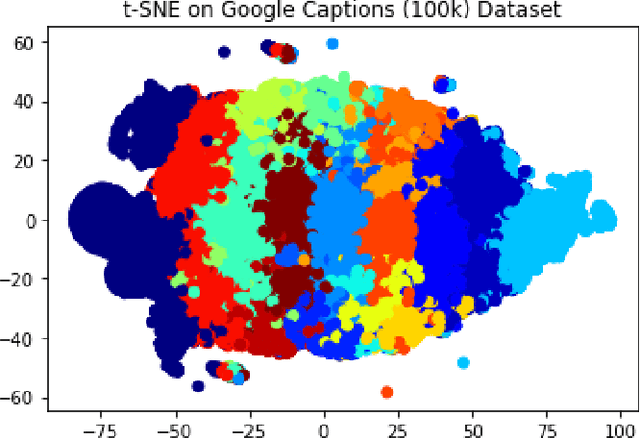
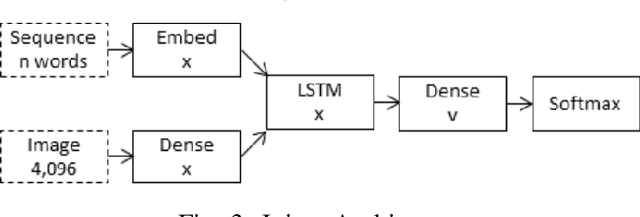
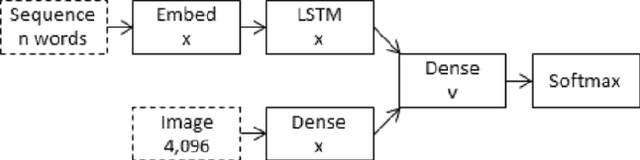
Extracting context from visual representations is of utmost importance in the advancement of Computer Science. Representation of such a format in Natural Language has a huge variety of applications such as helping the visually impaired etc. Such an approach is a combination of Computer Vision and Natural Language techniques which is a hard problem to solve. This project aims to compare different approaches for solving the image captioning problem. In specific, the focus was on comparing two different types of models: Encoder-Decoder approach and a Multi-model approach. In the encoder-decoder approach, inject and merge architectures were compared against a multi-modal image captioning approach based primarily on object detection. These approaches have been compared on the basis on state of the art sentence comparison metrics such as BLEU, GLEU, Meteor, and Rouge on a subset of the Google Conceptual captions dataset which contains 100k images. On the basis of this comparison, we observed that the best model was the Inception injected encoder model. This best approach has been deployed as a web-based system. On uploading an image, such a system will output the best caption associated with the image.