 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Flamingo: Scaling Music Understanding in Audio Language Models
Nov 13, 2025We introduce Music Flamingo, a novel large audio-language model designed to advance music (including song) understanding in foundational audio models. While audio-language research has progressed rapidly, music remains challenging due to its dynamic, layered, and information-dense nature. Progress has been further limited by the difficulty of scaling open audio understanding models, primarily because of the scarcity of high-quality music data and annotations. As a result, prior models are restricted to producing short, high-level captions, answering only surface-level questions, and showing limited generalization across diverse musical cultures. To address these challenges, we curate MF-Skills, a large-scale dataset labeled through a multi-stage pipeline that yields rich captions and question-answer pairs covering harmony, structure, timbre, lyrics, and cultural context. We fine-tune an enhanced Audio Flamingo 3 backbone on MF-Skills and further strengthen multiple skills relevant to music understanding. To improve the model's reasoning abilities, we introduce a post-training recipe: we first cold-start with MF-Think, a novel chain-of-thought dataset grounded in music theory, followed by GRPO-based reinforcement learning with custom rewards. Music Flamingo achieves state-of-the-art results across 10+ benchmarks for music understanding and reasoning, establishing itself as a generalist and musically intelligent audio-language model. Beyond strong empirical results, Music Flamingo sets a new standard for advanced music understanding by demonstrating how models can move from surface-level recognition toward layered, human-like perception of songs. We believe this work provides both a benchmark and a foundation for the community to build the next generation of models that engage with music as meaningfully as humans do.
A2SB: Audio-to-Audio Schrodinger Bridges
Jan 20, 2025Audio in the real world may be perturbed due to numerous factors, causing the audio quality to be degraded. The following work presents an audio restoration model tailored for high-res music at 44.1kHz. Our model, Audio-to-Audio Schrodinger Bridges (A2SB), is capable of both bandwidth extension (predicting high-frequency components) and inpainting (re-generating missing segments). Critically, A2SB is end-to-end without need of a vocoder to predict waveform outputs, able to restore hour-long audio inputs, and trained on permissively licensed music data. A2SB is capable of achieving state-of-the-art bandwidth extension and inpainting quality on several out-of-distribution music test sets. Our demo website is https: //research.nvidia.com/labs/adlr/A2SB/.
ETTA: Elucidating the Design Space of Text-to-Audio Models
Dec 26, 2024Recent years have seen significant progress in Text-To-Audio (TTA) synthesis, enabling users to enrich their creative workflows with synthetic audio generated from natural language prompts. Despite this progress, the effects of data, model architecture, training objective functions, and sampling strategies on target benchmarks are not well understood. With the purpose of providing a holistic understanding of the design space of TTA models, we set up a large-scale empirical experiment focused on diffusion and flow matching models. Our contributions include: 1) AF-Synthetic, a large dataset of high quality synthetic captions obtained from an audio understanding model; 2) a systematic comparison of different architectural, training, and inference design choices for TTA models; 3) an analysis of sampling methods and their Pareto curves with respect to generation quality and inference speed. We leverage the knowledge obtained from this extensive analysis to propose our best model dubbed Elucidated Text-To-Audio (ETTA). When evaluated on AudioCaps and MusicCaps, ETTA provides improvements over the baselines trained on publicly available data, while being competitive with models trained on proprietary data. Finally, we show ETTA's improved ability to generate creative audio following complex and imaginative captions -- a task that is more challenging than current benchmarks.
Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Sep 18, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Aug 27, 2024



We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25\% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.
Improving Text-To-Audio Models with Synthetic Captions
Jun 18, 2024



It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged \textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an \textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named \texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new \textit{state-of-the-art}.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Apr 01, 2023



Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Jun 09, 2022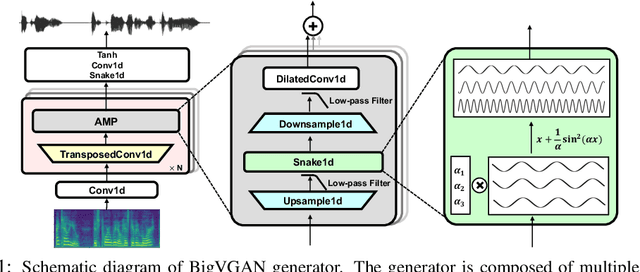

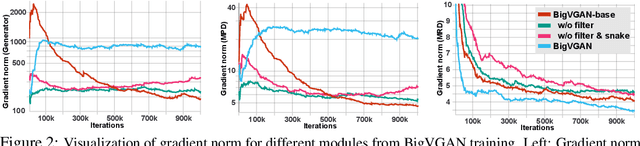

Despite recent progress in generative adversarial network(GAN)-based vocoders, where the model generates raw waveform conditioned on mel spectrogram, it is still challenging to synthesize high-fidelity audio for numerous speakers across varied recording environments. In this work, we present BigVGAN, a universal vocoder that generalizes well under various unseen conditions in zero-shot setting. We introduce periodic nonlinearities and anti-aliased representation into the generator, which brings the desired inductive bias for waveform synthesis and significantly improves audio quality. Based on our improved generator and the state-of-the-art discriminators, we train our GAN vocoder at the largest scale up to 112M parameters, which is unprecedented in the literature. In particular, we identify and address the training instabilities specific to such scale, while maintaining high-fidelity output without over-regularization. Our BigVGAN achieves the state-of-the-art zero-shot performance for various out-of-distribution scenarios, including new speakers, novel languages, singing voices, music and instrumental audio in unseen (even noisy) recording environments. We will release our code and model at: https://github.com/NVIDIA/BigVGAN
Robust End-to-End Focal Liver Lesion Detection using Unregistered Multiphase Computed Tomography Images
Dec 17, 2021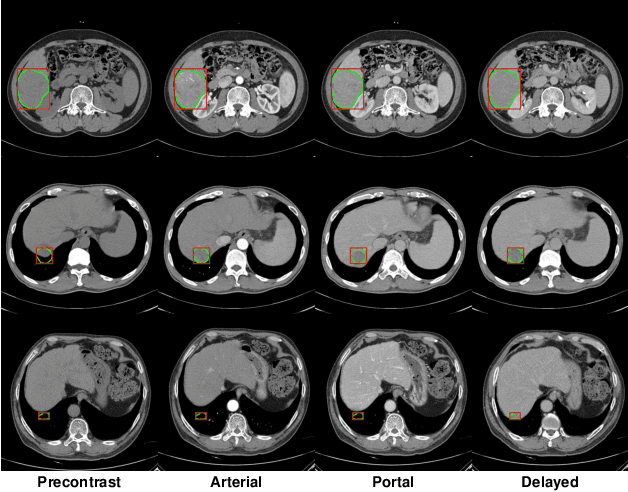
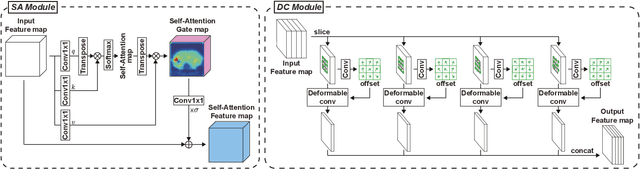
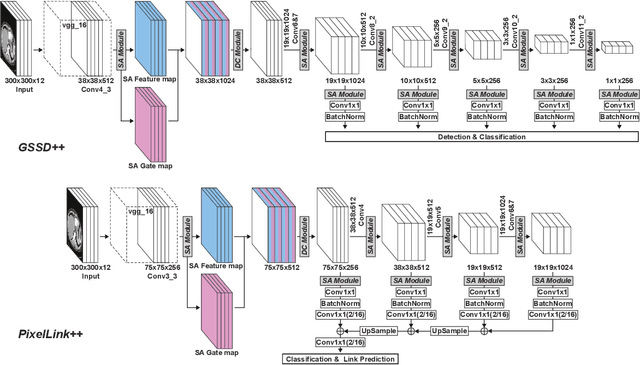
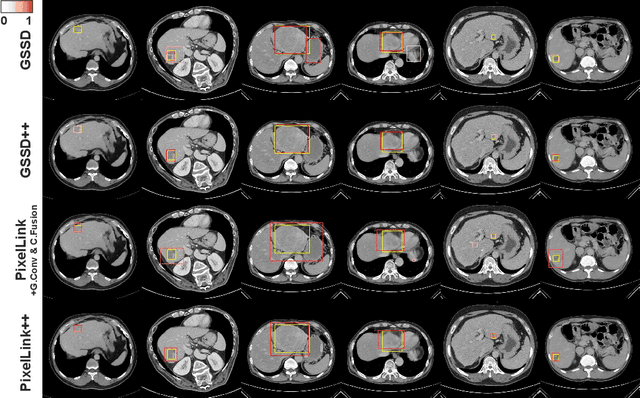
The computer-aided diagnosis of focal liver lesions (FLLs) can help improve workflow and enable correct diagnoses; FLL detection is the first step in such a computer-aided diagnosis. Despite the recent success of deep-learning-based approaches in detecting FLLs, current methods are not sufficiently robust for assessing misaligned multiphase data. By introducing an attention-guided multiphase alignment in feature space, this study presents a fully automated, end-to-end learning framework for detecting FLLs from multiphase computed tomography (CT) images. Our method is robust to misaligned multiphase images owing to its complete learning-based approach, which reduces the sensitivity of the model's performance to the quality of registration and enables a standalone deployment of the model in clinical practice. Evaluation on a large-scale dataset with 280 patients confirmed that our method outperformed previous state-of-the-art methods and significantly reduced the performance degradation for detecting FLLs using misaligned multiphase CT images. The robustness of the proposed method can enhance the clinical adoption of the deep-learning-based computer-aided detection system.
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Driven Adaptive Prior
Jun 11, 2021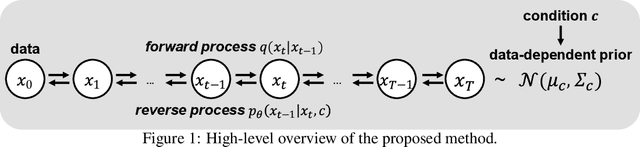
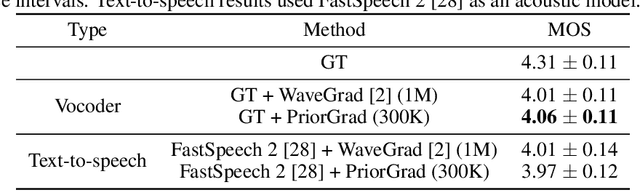


Denoising diffusion probabilistic models have been recently proposed to generate high-quality samples by estimating the gradient of the data density. The framework assumes the prior noise as a standard Gaussian distribution, whereas the corresponding data distribution may be more complicated than the standard Gaussian distribution, which potentially introduces inefficiency in denoising the prior noise into the data sample because of the discrepancy between the data and the prior. In this paper, we propose PriorGrad to improve the efficiency of the conditional diffusion model (for example, a vocoder using a mel-spectrogram as the condition) by applying an adaptive prior derived from the data statistics based on the conditional information. We formulate the training and sampling procedures of PriorGrad and demonstrate the advantages of an adaptive prior through a theoretical analysis. Focusing on the audio domain, we consider the recently proposed diffusion-based audio generative models based on both the spectral and time domains and show that PriorGrad achieves a faster convergence leading to data and parameter efficiency and improved quality, and thereby demonstrating the efficiency of a data-driven adaptive prior.