 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Nemotron-4 15B Technical Report
Feb 27, 2024



We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones. Specifically, Nemotron-4 15B exhibits the best multilingual capabilities of all similarly-sized models, even outperforming models over four times larger and those explicitly specialized for multilingual tasks.
Mixtral of Experts
Jan 08, 2024



We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
Retrieval meets Long Context Large Language Models
Oct 04, 2023



Extending the context window of large language models (LLMs) is getting popular recently, while the solution of augmenting LLMs with retrieval has existed for years. The natural questions are: i) Retrieval-augmentation versus long context window, which one is better for downstream tasks? ii) Can both methods be combined to get the best of both worlds? In this work, we answer these questions by studying both solutions using two state-of-the-art pretrained LLMs, i.e., a proprietary 43B GPT and LLaMA2-70B. Perhaps surprisingly, we find that LLM with 4K context window using simple retrieval-augmentation at generation can achieve comparable performance to finetuned LLM with 16K context window via positional interpolation on long context tasks, while taking much less computation. More importantly, we demonstrate that retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes. Our best model, retrieval-augmented LLaMA2-70B with 32K context window, outperforms GPT-3.5-turbo-16k and Davinci003 in terms of average score on seven long context tasks including question answering and query-based summarization. It also outperforms its non-retrieval LLaMA2-70B-32k baseline by a margin, while being much faster at generation. Our study provides general insights on the choice of retrieval-augmentation versus long context extension of LLM for practitioners.
Finding the Right Recipe for Low Resource Domain Adaptation in Neural Machine Translation
Jun 02, 2022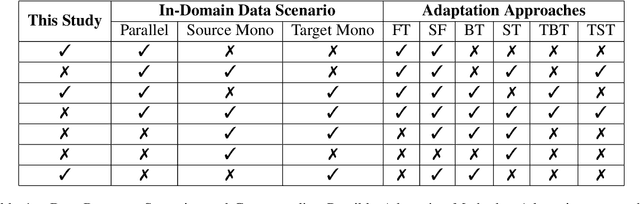
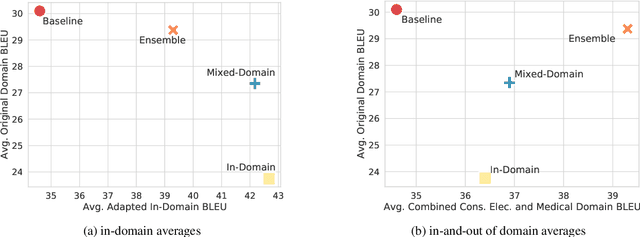
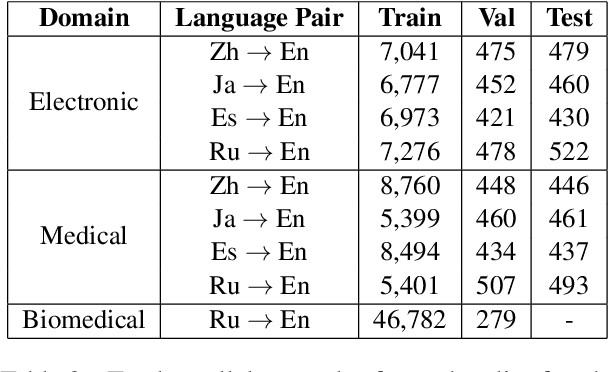
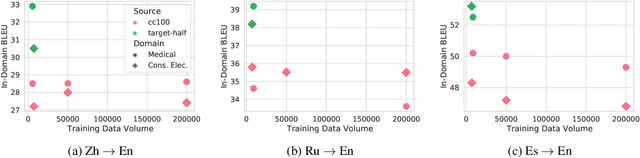
General translation models often still struggle to generate accurate translations in specialized domains. To guide machine translation practitioners and characterize the effectiveness of domain adaptation methods under different data availability scenarios, we conduct an in-depth empirical exploration of monolingual and parallel data approaches to domain adaptation of pre-trained, third-party, NMT models in settings where architecture change is impractical. We compare data centric adaptation methods in isolation and combination. We study method effectiveness in very low resource (8k parallel examples) and moderately low resource (46k parallel examples) conditions and propose an ensemble approach to alleviate reductions in original domain translation quality. Our work includes three domains: consumer electronic, clinical, and biomedical and spans four language pairs - Zh-En, Ja-En, Es-En, and Ru-En. We also make concrete recommendations for achieving high in-domain performance and release our consumer electronic and medical domain datasets for all languages and make our code publicly available.
NVIDIA NeMo Neural Machine Translation Systems for English-German and English-Russian News and Biomedical Tasks at WMT21
Nov 16, 2021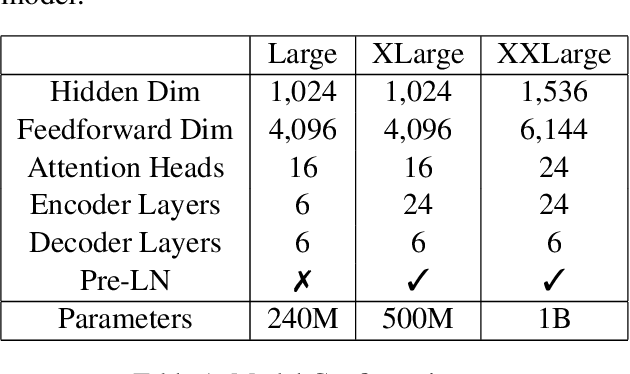
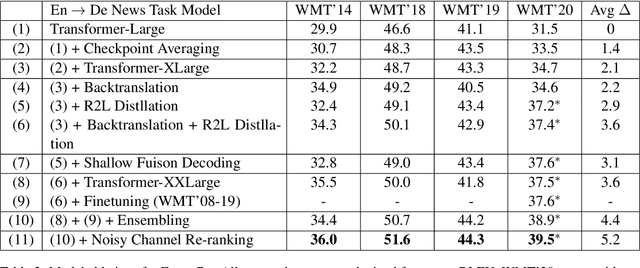
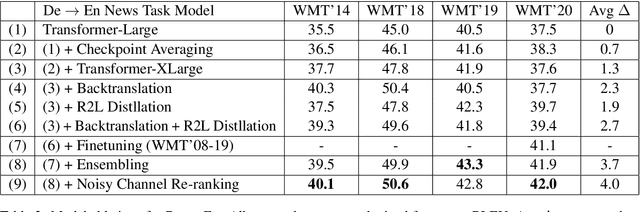
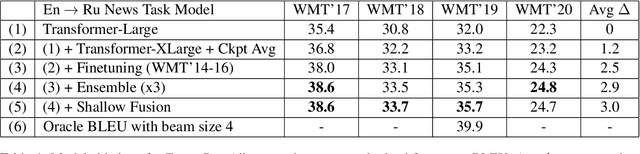
This paper provides an overview of NVIDIA NeMo's neural machine translation systems for the constrained data track of the WMT21 News and Biomedical Shared Translation Tasks. Our news task submissions for English-German (En-De) and English-Russian (En-Ru) are built on top of a baseline transformer-based sequence-to-sequence model. Specifically, we use a combination of 1) checkpoint averaging 2) model scaling 3) data augmentation with backtranslation and knowledge distillation from right-to-left factorized models 4) finetuning on test sets from previous years 5) model ensembling 6) shallow fusion decoding with transformer language models and 7) noisy channel re-ranking. Additionally, our biomedical task submission for English-Russian uses a biomedically biased vocabulary and is trained from scratch on news task data, medically relevant text curated from the news task dataset, and biomedical data provided by the shared task. Our news system achieves a sacreBLEU score of 39.5 on the WMT'20 En-De test set outperforming the best submission from last year's task of 38.8. Our biomedical task Ru-En and En-Ru systems reach BLEU scores of 43.8 and 40.3 respectively on the WMT'20 Biomedical Task Test set, outperforming the previous year's best submissions.