 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025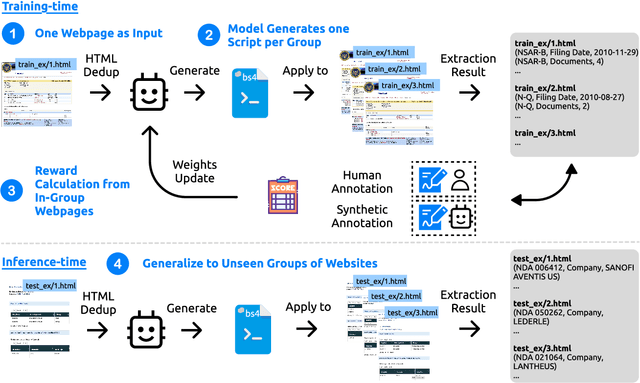
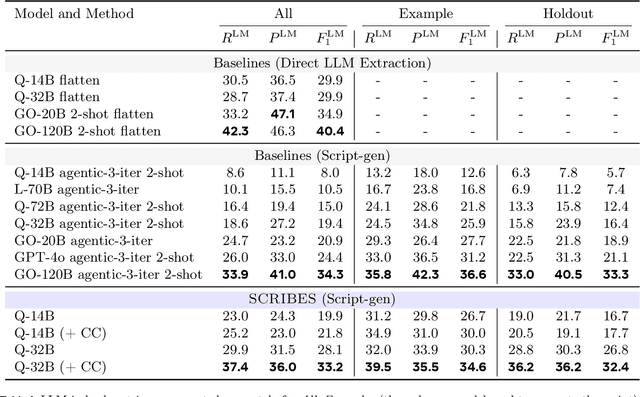

Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
Learning to Reason for Factuality
Aug 07, 2025Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.
Frustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks
Jul 02, 2025Retrieval-augmented Generation (RAG) has primarily been studied in limited settings, such as factoid question answering; more challenging, reasoning-intensive benchmarks have seen limited success from minimal RAG. In this work, we challenge this prevailing view on established, reasoning-intensive benchmarks: MMLU, MMLU Pro, AGI Eval, GPQA, and MATH. We identify a key missing component in prior work: a usable, web-scale datastore aligned with the breadth of pretraining data. To this end, we introduce CompactDS: a diverse, high-quality, web-scale datastore that achieves high retrieval accuracy and subsecond latency on a single-node. The key insights are (1) most web content can be filtered out without sacrificing coverage, and a compact, high-quality subset is sufficient; and (2) combining in-memory approximate nearest neighbor (ANN) retrieval and on-disk exact search balances speed and recall. Using CompactDS, we show that a minimal RAG pipeline achieves consistent accuracy improvements across all benchmarks and model sizes (8B--70B), with relative gains of 10% on MMLU, 33% on MMLU Pro, 14% on GPQA, and 19% on MATH. No single data source suffices alone, highlighting the importance of diversity of sources (web crawls, curated math, academic papers, textbooks). Finally, we show that our carefully designed in-house datastore matches or outperforms web search engines such as Google Search, as well as recently proposed, complex agent-based RAG systems--all while maintaining simplicity, reproducibility, and self-containment. We release CompactDS and our retrieval pipeline, supporting future research exploring retrieval-based AI systems.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025



We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025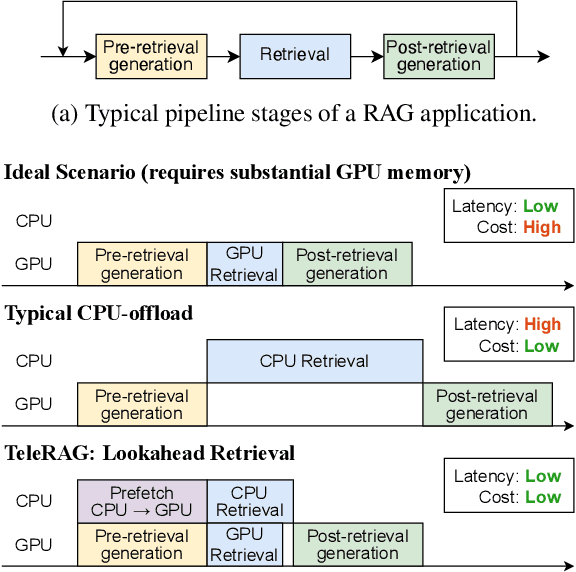
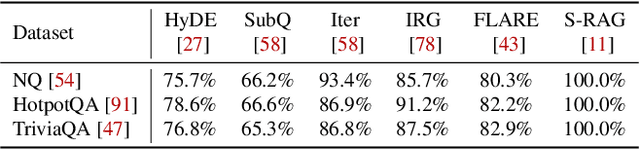
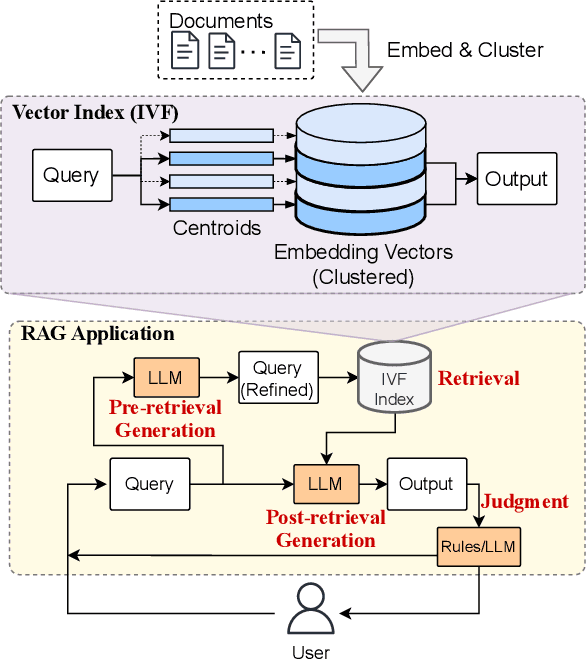
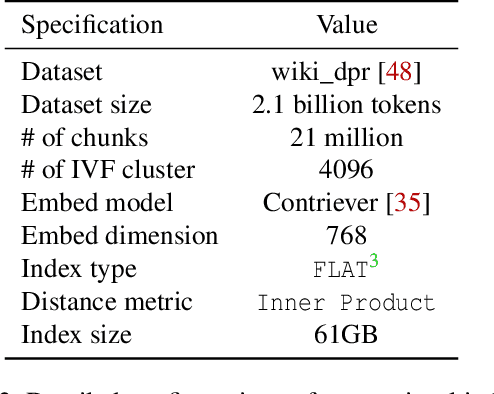
Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
ICONS: Influence Consensus for Vision-Language Data Selection
Jan 06, 2025



Visual Instruction Tuning typically requires a large amount of vision-language training data. This data often containing redundant information that increases computational costs without proportional performance gains. In this work, we introduce ICONS, a gradient-driven Influence CONsensus approach for vision-language data Selection that selects a compact training dataset for efficient multi-task training. The key element of our approach is cross-task influence consensus, which uses majority voting across task-specific influence matrices to identify samples that are consistently valuable across multiple tasks, allowing us to effectively prioritize data that optimizes for overall performance. Experiments show that models trained on our selected data (20% of LLaVA-665K) achieve 98.6% of the relative performance obtained using the full dataset. Additionally, we release this subset, LLaVA-ICONS-133K, a compact yet highly informative subset of LLaVA-665K visual instruction tuning data, preserving high impact training data for efficient vision-language model development.
Improving Factuality with Explicit Working Memory
Dec 24, 2024



Large language models can generate factually inaccurate content, a problem known as hallucination. Recent works have built upon retrieved-augmented generation to improve factuality through iterative prompting but these methods are limited by the traditional RAG design. To address these challenges, we introduce EWE (Explicit Working Memory), a novel approach that enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources. The memory is refreshed based on online fact-checking and retrieval feedback, allowing EWE to rectify false claims during the generation process and ensure more accurate and reliable outputs. Our experiments demonstrate that Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 10 points absolute without sacrificing the helpfulness of the responses. Further analysis reveals that the design of rules for memory updates, configurations of memory units, and the quality of the retrieval datastore are crucial factors for influencing model performance.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.