 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM*: A Modular, Extensible, Serving System for Multimodal Models
Jun 10, 2026We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, diffusion and flow heads, audio codecs, action generators, and world-model predictors. Such architectures underpin a broad class of multimodal models, including unified multimodal models, omni models, speech-language models, vision-language-action policies, and world models. However, existing model serving frameworks were built on narrow assumptions about model structure, making them ill-suited to accommodate this new architectural diversity. Here we present M*, a universal serving system for efficient serving of composite AI models. M* represents models as dataflow graphs, processing requests spanning diverse modalities and tasks as traversals over these graphs. The core insight is a modular abstraction that supports arbitrary composition of model components, flexible placement onto a physical cluster, and model-agnostic optimizations within a distributed runtime. We call this abstraction the Walk Graph and show how it can concisely capture composite models from a broad range of families. We instantiate M* on representative models and find that it achieves, on average, 20% lower end-to-end latency than vLLM-Omni for text-to-image workloads on BAGEL, while delivering up to 2.9x lower real-time factor and 2.7x higher throughput for text-to-speech workloads on Qwen3-Omni. M* also outperforms the V-JEPA 2-AC rollout baseline for robotic planning by up to 12.5x. Thus, our work paves the road towards more efficient serving of complex models with minimal developer effort.
MURMUR: An Efficient Inference System for Long-Form ASR
May 31, 2026Long-form automatic speech recognition (ASR) requires both high accuracy and low latency, but existing systems force a trade-off between the two. Chunk-based pipelines process audio in parallel windows for low latency, but lose cross-chunk context and need brittle heuristics to align speakers and timestamps at boundaries. Long-context ASR models resolve everything in a single pass for better accuracy, but are an order of magnitude slower. We propose Murmur, an inference system that overcomes this trade-off by operating at two levels. At the inter-chunk level, we revisit the chunk-based pipeline for modern long-context ASR, treating chunk size as a tunable hyperparameter, and show that intermediate chunk sizes strike a good balance of accuracy and latency. At the intra-chunk level, we exploit attention sparsity through a sliding window KV cache eviction policy applied to both output and speech tokens. On AMI-IHM, Murmur matches single-pass accuracy while reducing latency by 4.2x, with further gains from token eviction at less than 1% relative tcpWER degradation. The code of Murmur is available at https://github.com/uw-syfi/Murmur.
VibeServe: Can AI Agents Build Bespoke LLM Serving Systems?
May 07, 2026For years, we have built LLM serving systems like any other critical infrastructure: a single general-purpose stack, hand-tuned over many engineer-years, meant to support every model and workload. In this paper, we take the opposite bet: a multi-agent loop that automatically synthesizes bespoke serving systems for different usage scenarios. We propose VibeServe, the first agentic loop that generates entire LLM serving stacks end-to-end. VibeServe uses an outer loop to plan and track the search over system designs, and an inner loop to implement candidates, check correctness, and measure performance on the target benchmark. In the standard deployment setting, where existing stacks are highly optimized, VibeServe remains competitive with vLLM, showing that generation-time specialization need not come at the cost of performance. More interestingly, in non-standard scenarios, VibeServe outperforms existing systems by exploiting opportunities that generic systems miss in six scenarios involving non-standard model architectures, workload knowledge, and hardware-specific optimizations. Together, these results suggest a different point in the design space for infrastructure software: generation-time specialization rather than runtime generality. Code is available at https://github.com/uw-syfi/vibe-serve.
VoxServe: Streaming-Centric Serving System for Speech Language Models
Jan 30, 2026Deploying modern Speech Language Models (SpeechLMs) in streaming settings requires systems that provide low latency, high throughput, and strong guarantees of streamability. Existing systems fall short of supporting diverse models flexibly and efficiently. We present VoxServe, a unified serving system for SpeechLMs that optimizes streaming performance. VoxServe introduces a model-execution abstraction that decouples model architecture from system-level optimizations, thereby enabling support for diverse SpeechLM architectures within a single framework. Building on this abstraction, VoxServe implements streaming-aware scheduling and an asynchronous inference pipeline to improve end-to-end efficiency. Evaluations across multiple modern SpeechLMs show that VoxServe achieves 10-20x higher throughput than existing implementations at comparable latency while maintaining high streaming viability. The code of VoxServe is available at https://github.com/vox-serve/vox-serve.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025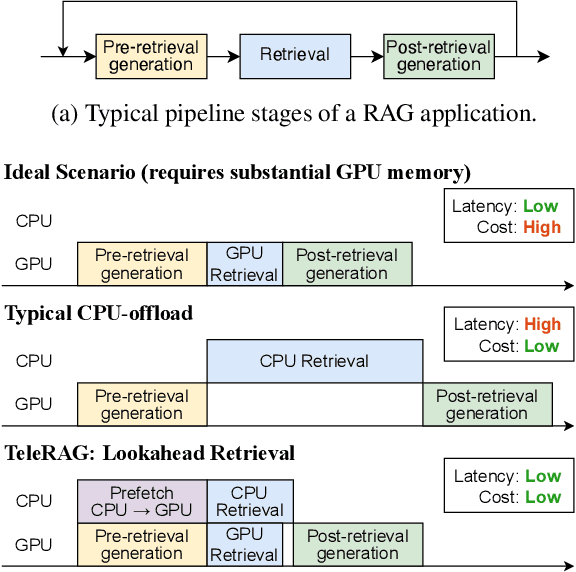
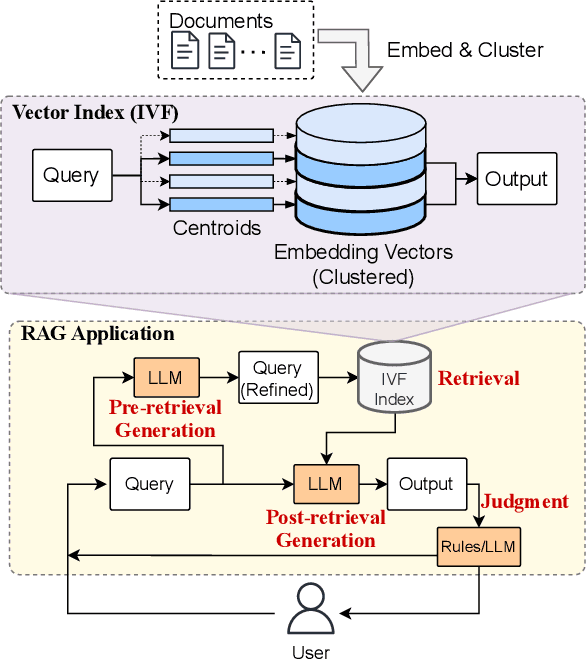
Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Feb 27, 2025



Modern automatic speech recognition (ASR) models, such as OpenAI's Whisper, rely on deep encoder-decoder architectures, and their encoders are a critical bottleneck for efficient deployment due to high computational intensity. We introduce LiteASR, a low-rank compression scheme for ASR encoders that significantly reduces inference costs while maintaining transcription accuracy. Our approach leverages the strong low-rank properties observed in intermediate activations: by applying principal component analysis (PCA) with a small calibration dataset, we approximate linear transformations with a chain of low-rank matrix multiplications, and further optimize self-attention to work in the reduced dimension. Evaluation results show that our method can compress Whisper large-v3's encoder size by over 50%, matching Whisper medium's size with better transcription accuracy, thereby establishing a new Pareto-optimal frontier of efficiency and performance. The code of LiteASR is available at https://github.com/efeslab/LiteASR.
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
Feb 10, 2024



Large Language Models (LLMs) based on Mixture-of-Experts (MoE) architecture are showing promising performance on various tasks. However, running them on resource-constrained settings, where GPU memory resources are not abundant, is challenging due to huge model sizes. Existing systems that offload model weights to CPU memory suffer from the significant overhead of frequently moving data between CPU and GPU. In this paper, we propose Fiddler, a resource-efficient inference engine with CPU-GPU orchestration for MoE models. The key idea of Fiddler is to use the computation ability of the CPU to minimize the data movement between the CPU and GPU. Our evaluation shows that Fiddler can run the uncompressed Mixtral-8x7B model, which exceeds 90GB in parameters, to generate over $3$ tokens per second on a single GPU with 24GB memory, showing an order of magnitude improvement over existing methods. The code of Fiddler is publicly available at \url{https://github.com/efeslab/fiddler}