 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM*: A Modular, Extensible, Serving System for Multimodal Models
Jun 10, 2026We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, diffusion and flow heads, audio codecs, action generators, and world-model predictors. Such architectures underpin a broad class of multimodal models, including unified multimodal models, omni models, speech-language models, vision-language-action policies, and world models. However, existing model serving frameworks were built on narrow assumptions about model structure, making them ill-suited to accommodate this new architectural diversity. Here we present M*, a universal serving system for efficient serving of composite AI models. M* represents models as dataflow graphs, processing requests spanning diverse modalities and tasks as traversals over these graphs. The core insight is a modular abstraction that supports arbitrary composition of model components, flexible placement onto a physical cluster, and model-agnostic optimizations within a distributed runtime. We call this abstraction the Walk Graph and show how it can concisely capture composite models from a broad range of families. We instantiate M* on representative models and find that it achieves, on average, 20% lower end-to-end latency than vLLM-Omni for text-to-image workloads on BAGEL, while delivering up to 2.9x lower real-time factor and 2.7x higher throughput for text-to-speech workloads on Qwen3-Omni. M* also outperforms the V-JEPA 2-AC rollout baseline for robotic planning by up to 12.5x. Thus, our work paves the road towards more efficient serving of complex models with minimal developer effort.
Piper: A Programmable Distributed Training System
Jun 09, 2026Large-scale model training increasingly relies on composing multiple parallelism strategies, such as data, pipeline, and expert parallelism, together with memory-saving optimizations like ZeRO. Deployed systems for foundation model pretraining often rely on human experts to manually design a high-level parallelism strategy then implement the corresponding low-level execution strategy, making it difficult to adapt the system to new strategies. Meanwhile, many general-purpose frameworks are more flexible but their implementations are still tied to a fixed set of common parallelism strategies, making it challenging to integrate state-of-the-art strategies. We present Piper, a user-controllable distributed training system that decouples the strategy from the runtime implementation. Piper allows users to declare a comprehensive distributed training strategy with a small set of model annotations and scheduling directives. Each directive applies a transformation on Piper's intermediate representation (IR), a unified global training DAG that represents all computation and communication. Using this IR, Piper compiles per-device execution plans and executes them with a distributed runtime agnostic to the strategy. We show that the combined system maintains performance parity on commonly available strategies such as ZeRO, while also enabling additional performance and memory efficiency gains through joint scheduling of compute and communication in composed parallelism strategies such as DeepSeek-V3's DualPipe.
VoxServe: Streaming-Centric Serving System for Speech Language Models
Jan 30, 2026Deploying modern Speech Language Models (SpeechLMs) in streaming settings requires systems that provide low latency, high throughput, and strong guarantees of streamability. Existing systems fall short of supporting diverse models flexibly and efficiently. We present VoxServe, a unified serving system for SpeechLMs that optimizes streaming performance. VoxServe introduces a model-execution abstraction that decouples model architecture from system-level optimizations, thereby enabling support for diverse SpeechLM architectures within a single framework. Building on this abstraction, VoxServe implements streaming-aware scheduling and an asynchronous inference pipeline to improve end-to-end efficiency. Evaluations across multiple modern SpeechLMs show that VoxServe achieves 10-20x higher throughput than existing implementations at comparable latency while maintaining high streaming viability. The code of VoxServe is available at https://github.com/vox-serve/vox-serve.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025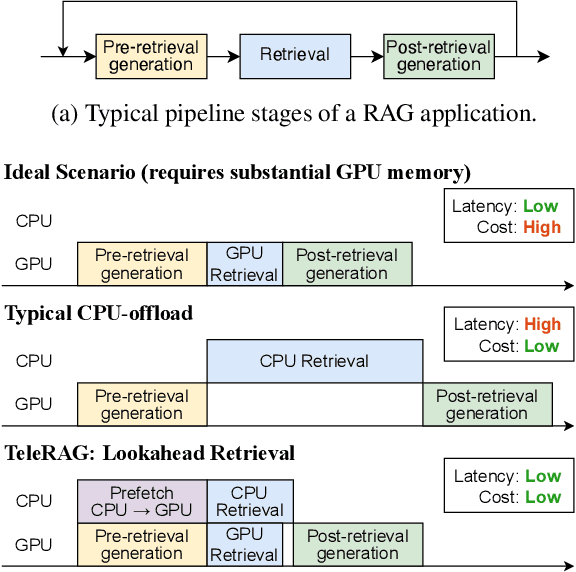
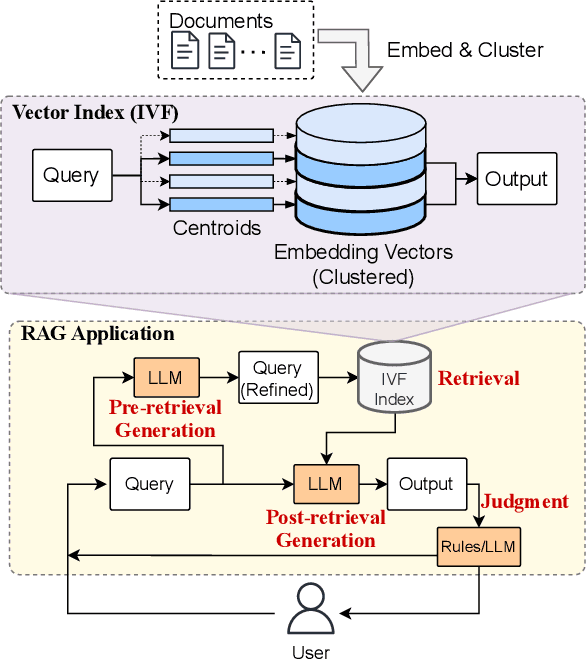
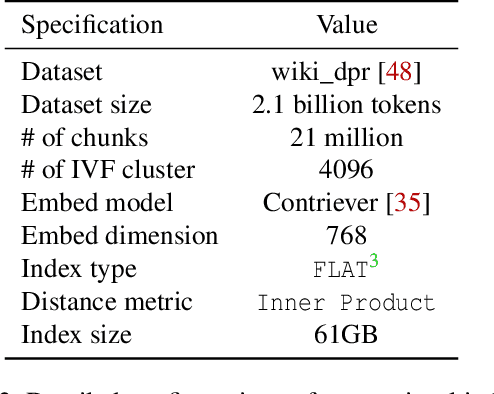
Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Composable Core-sets for Diversity Approximation on Multi-Dataset Streams
Aug 10, 2023Core-sets refer to subsets of data that maximize some function that is commonly a diversity or group requirement. These subsets are used in place of the original data to accomplish a given task with comparable or even enhanced performance if biases are removed. Composable core-sets are core-sets with the property that subsets of the core set can be unioned together to obtain an approximation for the original data; lending themselves to be used for streamed or distributed data. Recent work has focused on the use of core-sets for training machine learning models. Preceding solutions such as CRAIG have been proven to approximate gradient descent while providing a reduced training time. In this paper, we introduce a core-set construction algorithm for constructing composable core-sets to summarize streamed data for use in active learning environments. If combined with techniques such as CRAIG and heuristics to enhance construction speed, composable core-sets could be used for real time training of models when the amount of sensor data is large. We provide empirical analysis by considering extrapolated data for the runtime of such a brute force algorithm. This algorithm is then analyzed for efficiency through averaged empirical regression and key results and improvements are suggested for further research on the topic.
DeepCurrents: Learning Implicit Representations of Shapes with Boundaries
Nov 17, 2021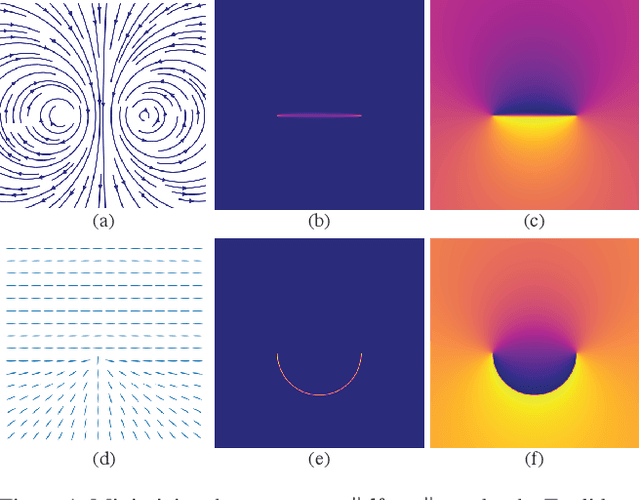
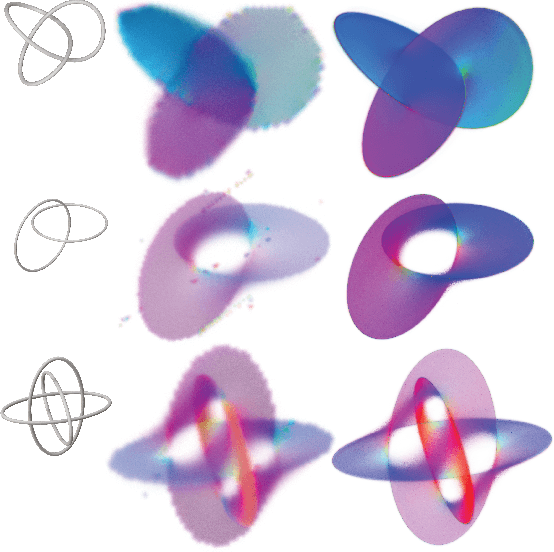
Recent techniques have been successful in reconstructing surfaces as level sets of learned functions (such as signed distance fields) parameterized by deep neural networks. Many of these methods, however, learn only closed surfaces and are unable to reconstruct shapes with boundary curves. We propose a hybrid shape representation that combines explicit boundary curves with implicit learned interiors. Using machinery from geometric measure theory, we parameterize currents using deep networks and use stochastic gradient descent to solve a minimal surface problem. By modifying the metric according to target geometry coming, e.g., from a mesh or point cloud, we can use this approach to represent arbitrary surfaces, learning implicitly defined shapes with explicitly defined boundary curves. We further demonstrate learning families of shapes jointly parameterized by boundary curves and latent codes.
Hoplite: Efficient Collective Communication for Task-Based Distributed Systems
Feb 13, 2020


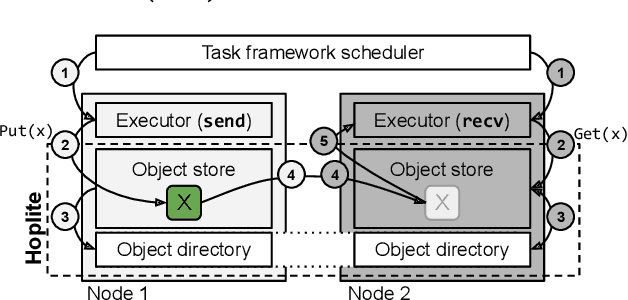
Collective communication systems such as MPI offer high performance group communication primitives at the cost of application flexibility. Today, an increasing number of distributed applications (e.g, reinforcement learning) require flexibility in expressing dynamic and asynchronous communication patterns. To accommodate these applications, task-based distributed computing frameworks (e.g., Ray, Dask, Hydro) have become popular as they allow applications to dynamically specify communication by invoking tasks, or functions, at runtime. This design makes efficient collective communication challenging because (1) the group of communicating processes is chosen at runtime, and (2) processes may not all be ready at the same time. We design and implement Hoplite, a communication layer for task-based distributed systems that achieves high performance collective communication without compromising application flexibility. The key idea of Hoplite is to use distributed protocols to compute a data transfer schedule on the fly. This enables the same optimizations used in traditional collective communication, but for applications that specify the communication incrementally. We show that Hoplite can achieve similar performance compared with a traditional collective communication library, MPICH. We port a popular distributed computing framework, Ray, on atop of Hoplite. We show that Hoplite can speed up asynchronous parameter server and distributed reinforcement learning workloads that are difficult to execute efficiently with traditional collective communication by up to 8.1x and 3.9x, respectively.
Ray: A Distributed Framework for Emerging AI Applications
Sep 30, 2018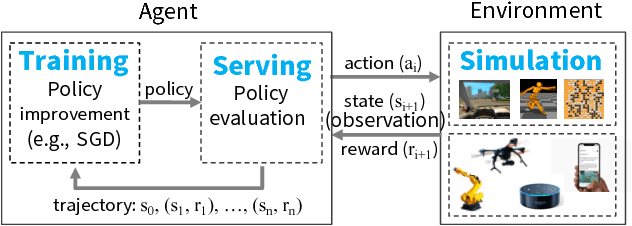


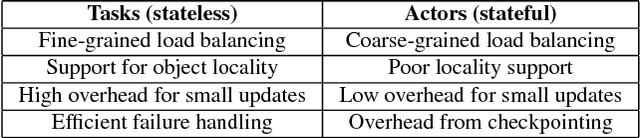
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.