 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-based Inversion of 2.5D Controlled Source Electromagnetic Data using Generative Priors
Jan 05, 2026In this study, we investigate feature-based 2.5D controlled source marine electromagnetic (mCSEM) data inversion using generative priors. Two-and-half dimensional modeling using finite difference method (FDM) is adopted to compute the response of horizontal electric dipole (HED) excitation. Rather than using a neural network to approximate the entire inverse mapping in a black-box manner, we adopt a plug-andplay strategy in which a variational autoencoder (VAE) is used solely to learn prior information on conductivity distributions. During the inversion process, the conductivity model is iteratively updated using the Gauss Newton method, while the model space is constrained by projections onto the learned VAE decoder. This framework preserves explicit control over data misfit and enables flexible adaptation to different survey configurations. Numerical and field experiments demonstrate that the proposed approach effectively incorporates prior information, improves reconstruction accuracy, and exhibits good generalization performance.
Bayesian Signal Separation via Plug-and-Play Diffusion-Within-Gibbs Sampling
Sep 16, 2025We propose a posterior sampling algorithm for the problem of estimating multiple independent source signals from their noisy superposition. The proposed algorithm is a combination of Gibbs sampling method and plug-and-play (PnP) diffusion priors. Unlike most existing diffusion-model-based approaches for signal separation, our method allows source priors to be learned separately and flexibly combined without retraining. Moreover, under the assumption of perfect diffusion model training, the proposed method provably produces samples from the posterior distribution. Experiments on the task of heartbeat extraction from mixtures with synthetic motion artifacts demonstrate the superior performance of our method over existing approaches.
Plug-and-Play Latent Diffusion for Electromagnetic Inverse Scattering with Application to Brain Imaging
Sep 05, 2025



Electromagnetic (EM) imaging is an important tool for non-invasive sensing with low-cost and portable devices. One emerging application is EM stroke imaging, which enables early diagnosis and continuous monitoring of brain strokes. Quantitative imaging is achieved by solving an inverse scattering problem (ISP) that reconstructs permittivity and conductivity maps from measurements. In general, the reconstruction accuracy is limited by its inherent nonlinearity and ill-posedness. Existing methods, including learning-free and learning-based approaches, fail to either incorporate complicated prior distributions or provide theoretical guarantees, posing difficulties in balancing interpretability, distortion error, and reliability. To overcome these limitations, we propose a posterior sampling method based on latent diffusion for quantitative EM brain imaging, adapted from a generative plug-and-play (PnP) posterior sampling framework. Our approach allows to flexibly integrate prior knowledge into physics-based inversion without requiring paired measurement-label datasets. We first learn the prior distribution of targets from an unlabeled dataset, and then incorporate the learned prior into posterior sampling. In particular, we train a latent diffusion model on permittivity and conductivity maps to capture their prior distribution. Then, given measurements and the forward model describing EM wave physics, we perform posterior sampling by alternating between two samplers that respectively enforce the likelihood and prior distributions. Finally, reliable reconstruction is obtained through minimum mean squared error (MMSE) estimation based on the samples. Experimental results on brain imaging demonstrate that our approach achieves state-of-the-art performance in reconstruction accuracy and structural similarity while maintaining high measurement fidelity.
UNO: Unified Self-Supervised Monocular Odometry for Platform-Agnostic Deployment
Jun 08, 2025This work presents UNO, a unified monocular visual odometry framework that enables robust and adaptable pose estimation across diverse environments, platforms, and motion patterns. Unlike traditional methods that rely on deployment-specific tuning or predefined motion priors, our approach generalizes effectively across a wide range of real-world scenarios, including autonomous vehicles, aerial drones, mobile robots, and handheld devices. To this end, we introduce a Mixture-of-Experts strategy for local state estimation, with several specialized decoders that each handle a distinct class of ego-motion patterns. Moreover, we introduce a fully differentiable Gumbel-Softmax module that constructs a robust inter-frame correlation graph, selects the optimal expert decoder, and prunes erroneous estimates. These cues are then fed into a unified back-end that combines pre-trained, scale-independent depth priors with a lightweight bundling adjustment to enforce geometric consistency. We extensively evaluate our method on three major benchmark datasets: KITTI (outdoor/autonomous driving), EuRoC-MAV (indoor/aerial drones), and TUM-RGBD (indoor/handheld), demonstrating state-of-the-art performance.
LiDAR-based Quadrotor for Slope Inspection in Dense Vegetation
Sep 21, 2024



This work presents a LiDAR-based quadrotor system for slope inspection in dense vegetation environments. Cities like Hong Kong are vulnerable to climate hazards, which often result in landslides. To mitigate the landslide risks, the Civil Engineering and Development Department (CEDD) has constructed steel flexible debris-resisting barriers on vulnerable natural catchments to protect residents. However, it is necessary to carry out regular inspections to identify any anomalies, which may affect the proper functioning of the barriers. Traditional manual inspection methods face challenges and high costs due to steep terrain and dense vegetation. Compared to manual inspection, unmanned aerial vehicles (UAVs) equipped with LiDAR sensors and cameras have advantages such as maneuverability in complex terrain, and access to narrow areas and high spots. However, conducting slope inspections using UAVs in dense vegetation poses significant challenges. First, in terms of hardware, the overall design of the UAV must carefully consider its maneuverability in narrow spaces, flight time, and the types of onboard sensors required for effective inspection. Second, regarding software, navigation algorithms need to be designed to enable obstacle avoidance flight in dense vegetation environments. To overcome these challenges, we develop a LiDAR-based quadrotor, accompanied by a comprehensive software system. The goal is to deploy our quadrotor in field environments to achieve efficient slope inspection. To assess the feasibility of our hardware and software system, we conduct functional tests in non-operational scenarios. Subsequently, invited by CEDD, we deploy our quadrotor in six field environments, including five flexible debris-resisting barriers located in dense vegetation and one slope that experienced a landslide. These experiments demonstrated the superiority of our quadrotor in slope inspection.
QUB-Cirdan at "Discharge Me!": Zero shot discharge letter generation by open-source LLM
May 27, 2024



The BioNLP ACL'24 Shared Task on Streamlining Discharge Documentation aims to reduce the administrative burden on clinicians by automating the creation of critical sections of patient discharge letters. This paper presents our approach using the Llama3 8B quantized model to generate the "Brief Hospital Course" and "Discharge Instructions" sections. We employ a zero-shot method combined with Retrieval-Augmented Generation (RAG) to produce concise, contextually accurate summaries. Our contributions include the development of a curated template-based approach to ensure reliability and consistency, as well as the integration of RAG for word count prediction. We also describe several unsuccessful experiments to provide insights into our pathway for the competition. Our results demonstrate the effectiveness and efficiency of our approach, achieving high scores across multiple evaluation metrics.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
Nov 07, 2023Large Language Models (LLMs) have seen great advance in both academia and industry, and their popularity results in numerous open-source frameworks and techniques in accelerating LLM pre-training, fine-tuning, and inference. Training and deploying LLMs are expensive as it requires considerable computing resources and memory, hence many efficient approaches have been developed for improving system pipelines as well as operators. However, the runtime performance can vary significantly across hardware and software stacks, which makes it difficult to choose the best configuration. In this work, we aim to benchmark the performance from both macro and micro perspectives. First, we benchmark the end-to-end performance of pre-training, fine-tuning, and serving LLMs in different sizes , i.e., 7, 13, and 70 billion parameters (7B, 13B, and 70B) on three 8-GPU platforms with and without individual optimization techniques, including ZeRO, quantization, recomputation, FlashAttention. Then, we dive deeper to provide a detailed runtime analysis of the sub-modules, including computing and communication operators in LLMs. For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs. For researchers, our in-depth module-wise analyses discover potential opportunities for future work to further optimize the runtime performance of LLMs.
A Monotonicity Constrained Attention Module for Emotion Classification with Limited EEG Data
Aug 17, 2022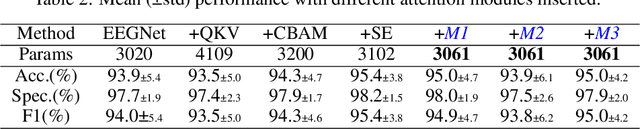
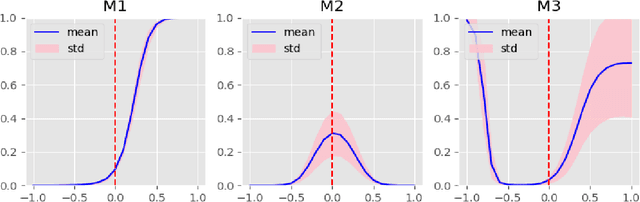
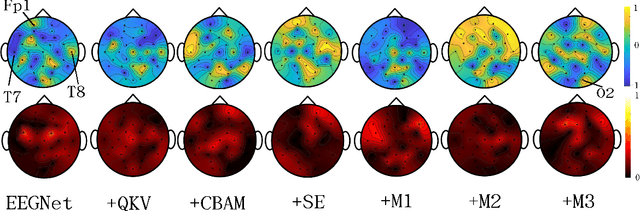
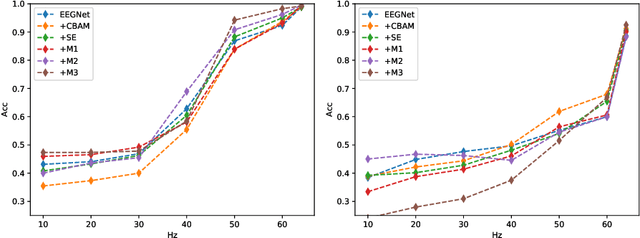
In this work, a parameter-efficient attention module is presented for emotion classification using a limited, or relatively small, number of electroencephalogram (EEG) signals. This module is called the Monotonicity Constrained Attention Module (MCAM) due to its capability of incorporating priors on the monotonicity when converting features' Gram matrices into attention matrices for better feature refinement. Our experiments have shown that MCAM's effectiveness is comparable to state-of-the-art attention modules in boosting the backbone network's performance in prediction while requiring less parameters. Several accompanying sensitivity analyses on trained models' prediction concerning different attacks are also performed. These attacks include various frequency domain filtering levels and gradually morphing between samples associated with multiple labels. Our results can help better understand different modules' behaviour in prediction and can provide guidance in applications where data is limited and are with noises.
Physics Embedded Machine Learning for Electromagnetic Data Imaging
Jul 26, 2022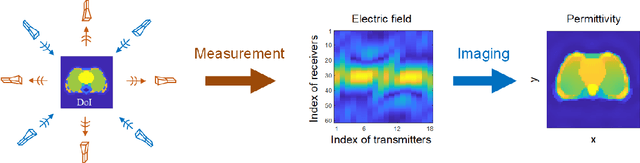
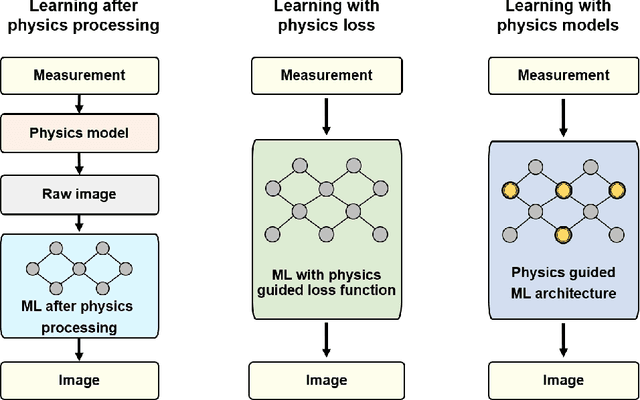
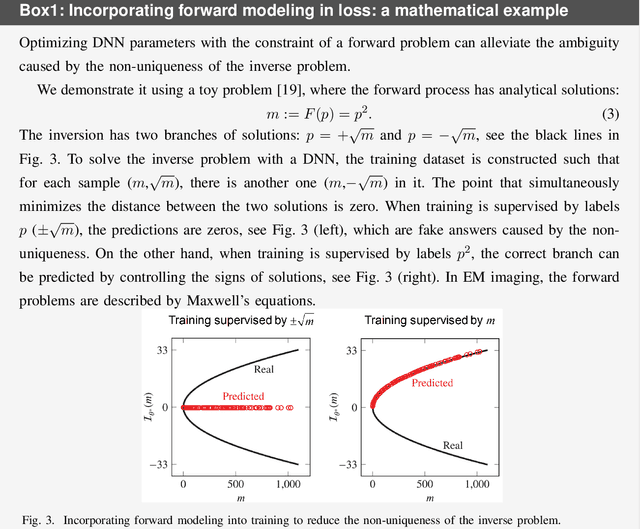
Electromagnetic (EM) imaging is widely applied in sensing for security, biomedicine, geophysics, and various industries. It is an ill-posed inverse problem whose solution is usually computationally expensive. Machine learning (ML) techniques and especially deep learning (DL) show potential in fast and accurate imaging. However, the high performance of purely data-driven approaches relies on constructing a training set that is statistically consistent with practical scenarios, which is often not possible in EM imaging tasks. Consequently, generalizability becomes a major concern. On the other hand, physical principles underlie EM phenomena and provide baselines for current imaging techniques. To benefit from prior knowledge in big data and the theoretical constraint of physical laws, physics embedded ML methods for EM imaging have become the focus of a large body of recent work. This article surveys various schemes to incorporate physics in learning-based EM imaging. We first introduce background on EM imaging and basic formulations of the inverse problem. We then focus on three types of strategies combining physics and ML for linear and nonlinear imaging and discuss their advantages and limitations. Finally, we conclude with open challenges and possible ways forward in this fast-developing field. Our aim is to facilitate the study of intelligent EM imaging methods that will be efficient, interpretable and controllable.