 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models
Jan 02, 2026The capability of Unified Multimodal Models (UMMs) to apply world knowledge across diverse tasks remains a critical, unresolved challenge. Existing benchmarks fall short, offering only siloed, single-task evaluations with limited diagnostic power. To bridge this gap, we propose AEGIS (\emph{i.e.}, \textbf{A}ssessing \textbf{E}diting, \textbf{G}eneration, \textbf{I}nterpretation-Understanding for \textbf{S}uper-intelligence), a comprehensive multi-task benchmark covering visual understanding, generation, editing, and interleaved generation. AEGIS comprises 1,050 challenging, manually-annotated questions spanning 21 topics (including STEM, humanities, daily life, etc.) and 6 reasoning types. To concretely evaluate the performance of UMMs in world knowledge scope without ambiguous metrics, we further propose Deterministic Checklist-based Evaluation (DCE), a protocol that replaces ambiguous prompt-based scoring with atomic ``Y/N'' judgments, to enhance evaluation reliability. Our extensive experiments reveal that most UMMs exhibit severe world knowledge deficits and that performance degrades significantly with complex reasoning. Additionally, simple plug-in reasoning modules can partially mitigate these vulnerabilities, highlighting a promising direction for future research. These results highlight the importance of world-knowledge-based reasoning as a critical frontier for UMMs.
Scaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025



Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025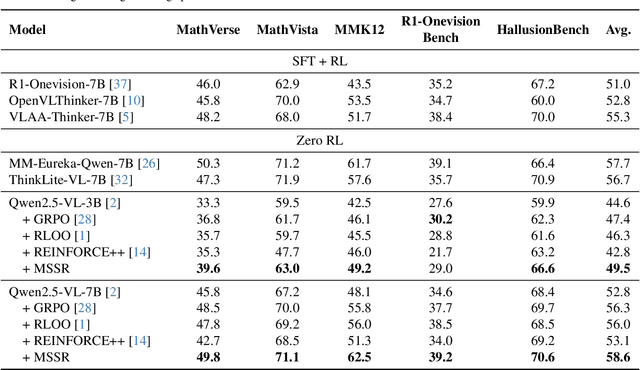
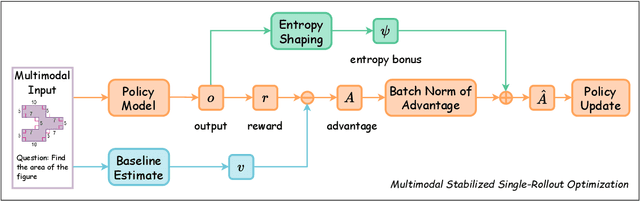

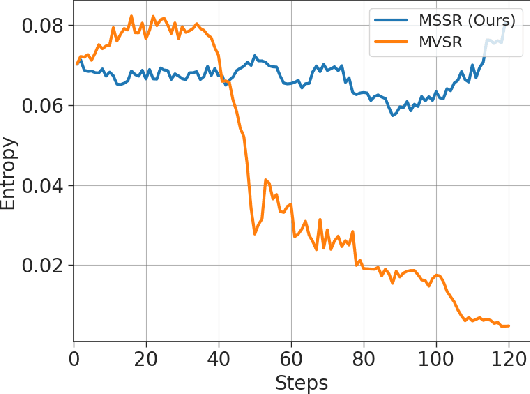
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement
Dec 17, 2025Pan-sharpening aims to generate high-resolution multispectral (HRMS) images by integrating a high-resolution panchromatic (PAN) image with its corresponding low-resolution multispectral (MS) image. To achieve effective fusion, it is crucial to fully exploit the complementary information between the two modalities. Traditional CNN-based methods typically rely on channel-wise concatenation with fixed convolutional operators, which limits their adaptability to diverse spatial and spectral variations. While cross-attention mechanisms enable global interactions, they are computationally inefficient and may dilute fine-grained correspondences, making it difficult to capture complex semantic relationships. Recent advances in the Multimodal Diffusion Transformer (MMDiT) architecture have demonstrated impressive success in image generation and editing tasks. Unlike cross-attention, MMDiT employs in-context conditioning to facilitate more direct and efficient cross-modal information exchange. In this paper, we propose MMMamba, a cross-modal in-context fusion framework for pan-sharpening, with the flexibility to support image super-resolution in a zero-shot manner. Built upon the Mamba architecture, our design ensures linear computational complexity while maintaining strong cross-modal interaction capacity. Furthermore, we introduce a novel multimodal interleaved (MI) scanning mechanism that facilitates effective information exchange between the PAN and MS modalities. Extensive experiments demonstrate the superior performance of our method compared to existing state-of-the-art (SOTA) techniques across multiple tasks and benchmarks.
Route-DETR: Pairwise Query Routing in Transformers for Object Detection
Dec 15, 2025Detection Transformer (DETR) offers an end-to-end solution for object detection by eliminating hand-crafted components like non-maximum suppression. However, DETR suffers from inefficient query competition where multiple queries converge to similar positions, leading to redundant computations. We present Route-DETR, which addresses these issues through adaptive pairwise routing in decoder self-attention layers. Our key insight is distinguishing between competing queries (targeting the same object) versus complementary queries (targeting different objects) using inter-query similarity, confidence scores, and geometry. We introduce dual routing mechanisms: suppressor routes that modulate attention between competing queries to reduce duplication, and delegator routes that encourage exploration of different regions. These are implemented via learnable low-rank attention biases enabling asymmetric query interactions. A dual-branch training strategy incorporates routing biases only during training while preserving standard attention for inference, ensuring no additional computational cost. Experiments on COCO and Cityscapes demonstrate consistent improvements across multiple DETR baselines, achieving +1.7% mAP gain over DINO on ResNet-50 and reaching 57.6% mAP on Swin-L, surpassing prior state-of-the-art models.
OCCDiff: Occupancy Diffusion Model for High-Fidelity 3D Building Reconstruction from Noisy Point Clouds
Dec 09, 2025A major challenge in reconstructing buildings from LiDAR point clouds lies in accurately capturing building surfaces under varying point densities and noise interference. To flexibly gather high-quality 3D profiles of the building in diverse resolution, we propose OCCDiff applying latent diffusion in the occupancy function space. Our OCCDiff combines a latent diffusion process with a function autoencoder architecture to generate continuous occupancy functions evaluable at arbitrary locations. Moreover, a point encoder is proposed to provide condition features to diffusion learning, constraint the final occupancy prediction for occupancy decoder, and insert multi-modal features for latent generation to latent encoder. To further enhance the model performance, a multi-task training strategy is employed, ensuring that the point encoder learns diverse and robust feature representations. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy data.
Interaction-Aware 4D Gaussian Splatting for Dynamic Hand-Object Interaction Reconstruction
Nov 18, 2025This paper focuses on a challenging setting of simultaneously modeling geometry and appearance of hand-object interaction scenes without any object priors. We follow the trend of dynamic 3D Gaussian Splatting based methods, and address several significant challenges. To model complex hand-object interaction with mutual occlusion and edge blur, we present interaction-aware hand-object Gaussians with newly introduced optimizable parameters aiming to adopt piecewise linear hypothesis for clearer structural representation. Moreover, considering the complementarity and tightness of hand shape and object shape during interaction dynamics, we incorporate hand information into object deformation field, constructing interaction-aware dynamic fields to model flexible motions. To further address difficulties in the optimization process, we propose a progressive strategy that handles dynamic regions and static background step by step. Correspondingly, explicit regularizations are designed to stabilize the hand-object representations for smooth motion transition, physical interaction reality, and coherent lighting. Experiments show that our approach surpasses existing dynamic 3D-GS-based methods and achieves state-of-the-art performance in reconstructing dynamic hand-object interaction.
Towards Authentic Movie Dubbing with Retrieve-Augmented Director-Actor Interaction Learning
Nov 18, 2025The automatic movie dubbing model generates vivid speech from given scripts, replicating a speaker's timbre from a brief timbre prompt while ensuring lip-sync with the silent video. Existing approaches simulate a simplified workflow where actors dub directly without preparation, overlooking the critical director-actor interaction. In contrast, authentic workflows involve a dynamic collaboration: directors actively engage with actors, guiding them to internalize the context cues, specifically emotion, before performance. To address this issue, we propose a new Retrieve-Augmented Director-Actor Interaction Learning scheme to achieve authentic movie dubbing, termed Authentic-Dubber, which contains three novel mechanisms: (1) We construct a multimodal Reference Footage library to simulate the learning footage provided by directors. Note that we integrate Large Language Models (LLMs) to achieve deep comprehension of emotional representations across multimodal signals. (2) To emulate how actors efficiently and comprehensively internalize director-provided footage during dubbing, we propose an Emotion-Similarity-based Retrieval-Augmentation strategy. This strategy retrieves the most relevant multimodal information that aligns with the target silent video. (3) We develop a Progressive Graph-based speech generation approach that incrementally incorporates the retrieved multimodal emotional knowledge, thereby simulating the actor's final dubbing process. The above mechanisms enable the Authentic-Dubber to faithfully replicate the authentic dubbing workflow, achieving comprehensive improvements in emotional expressiveness. Both subjective and objective evaluations on the V2C Animation benchmark dataset validate the effectiveness. The code and demos are available at https://github.com/AI-S2-Lab/Authentic-Dubber.
Codebook-Centric Deep Hashing: End-to-End Joint Learning of Semantic Hash Centers and Neural Hash Function
Nov 15, 2025



Hash center-based deep hashing methods improve upon pairwise or triplet-based approaches by assigning fixed hash centers to each class as learning targets, thereby avoiding the inefficiency of local similarity optimization. However, random center initialization often disregards inter-class semantic relationships. While existing two-stage methods mitigate this by first refining hash centers with semantics and then training the hash function, they introduce additional complexity, computational overhead, and suboptimal performance due to stage-wise discrepancies. To address these limitations, we propose $\textbf{Center-Reassigned Hashing (CRH)}$, an end-to-end framework that $\textbf{dynamically reassigns hash centers}$ from a preset codebook while jointly optimizing the hash function. Unlike previous methods, CRH adapts hash centers to the data distribution $\textbf{without explicit center optimization phases}$, enabling seamless integration of semantic relationships into the learning process. Furthermore, $\textbf{a multi-head mechanism}$ enhances the representational capacity of hash centers, capturing richer semantic structures. Extensive experiments on three benchmarks demonstrate that CRH learns semantically meaningful hash centers and outperforms state-of-the-art deep hashing methods in retrieval tasks.