 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions
Oct 16, 2020
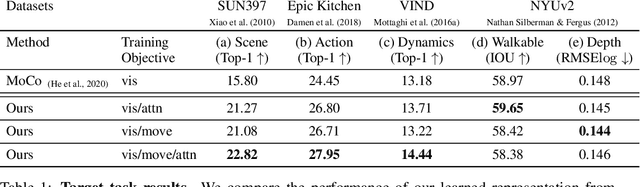

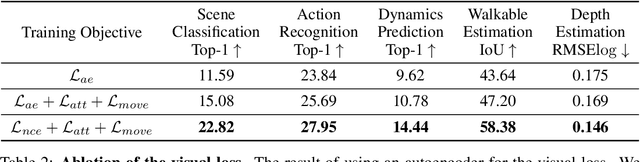
Learning effective representations of visual data that generalize to a variety of downstream tasks has been a long quest for computer vision. Most representation learning approaches rely solely on visual data such as images or videos. In this paper, we explore a novel approach, where we use human interaction and attention cues to investigate whether we can learn better representations compared to visual-only representations. For this study, we collect a dataset of human interactions capturing body part movements and gaze in their daily lives. Our experiments show that our self-supervised representation that encodes interaction and attention cues outperforms a visual-only state-of-the-art method MoCo (He et al., 2020), on a variety of target tasks: scene classification (semantic), action recognition (temporal), depth estimation (geometric), dynamics prediction (physics) and walkable surface estimation (affordance).
AllenAct: A Framework for Embodied AI Research
Aug 28, 2020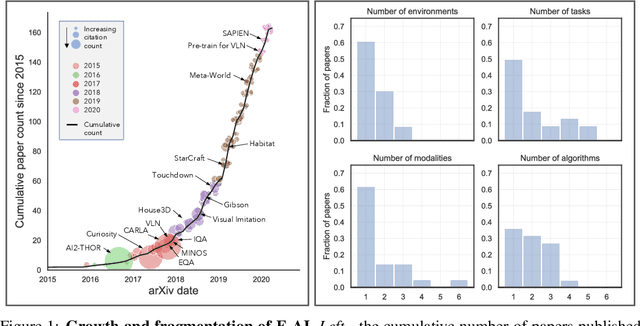

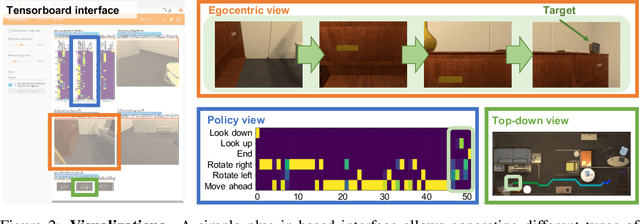
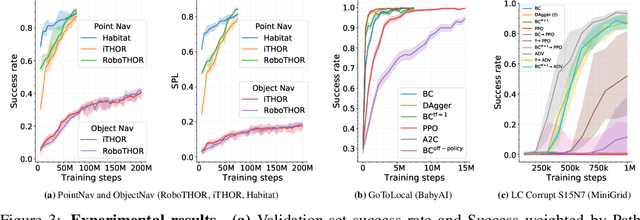
The domain of Embodied AI, in which agents learn to complete tasks through interaction with their environment from egocentric observations, has experienced substantial growth with the advent of deep reinforcement learning and increased interest from the computer vision, NLP, and robotics communities. This growth has been facilitated by the creation of a large number of simulated environments (such as AI2-THOR, Habitat and CARLA), tasks (like point navigation, instruction following, and embodied question answering), and associated leaderboards. While this diversity has been beneficial and organic, it has also fragmented the community: a huge amount of effort is required to do something as simple as taking a model trained in one environment and testing it in another. This discourages good science. We introduce AllenAct, a modular and flexible learning framework designed with a focus on the unique requirements of Embodied AI research. AllenAct provides first-class support for a growing collection of embodied environments, tasks and algorithms, provides reproductions of state-of-the-art models and includes extensive documentation, tutorials, start-up code, and pre-trained models. We hope that our framework makes Embodied AI more accessible and encourages new researchers to join this exciting area. The framework can be accessed at: https://allenact.org/
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Jun 23, 2020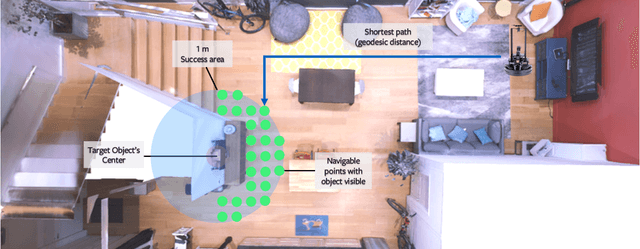

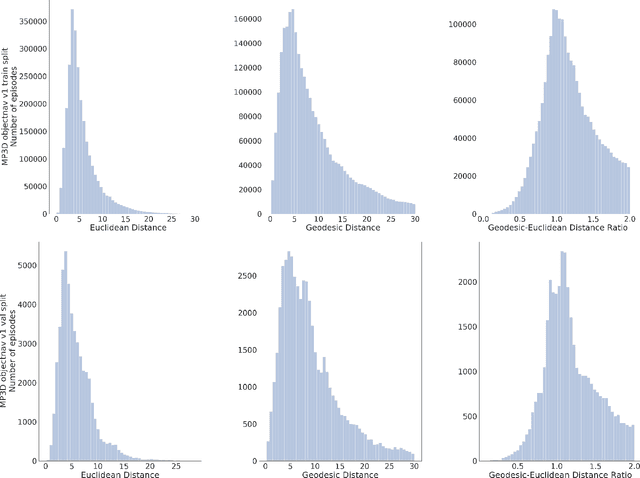
We revisit the problem of Object-Goal Navigation (ObjectNav). In its simplest form, ObjectNav is defined as the task of navigating to an object, specified by its label, in an unexplored environment. In particular, the agent is initialized at a random location and pose in an environment and asked to find an instance of an object category, e.g., find a chair, by navigating to it. As the community begins to show increased interest in semantic goal specification for navigation tasks, a number of different often-inconsistent interpretations of this task are emerging. This document summarizes the consensus recommendations of this working group on ObjectNav. In particular, we make recommendations on subtle but important details of evaluation criteria (for measuring success when navigating towards a target object), the agent's embodiment parameters, and the characteristics of the environments within which the task is carried out. Finally, we provide a detailed description of the instantiation of these recommendations in challenges organized at the Embodied AI workshop at CVPR 2020 \url{http://embodied-ai.org} .
Learning About Objects by Learning to Interact with Them
Jun 16, 2020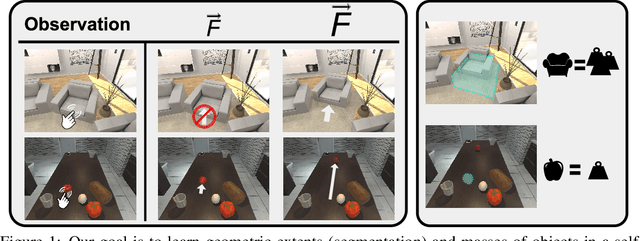
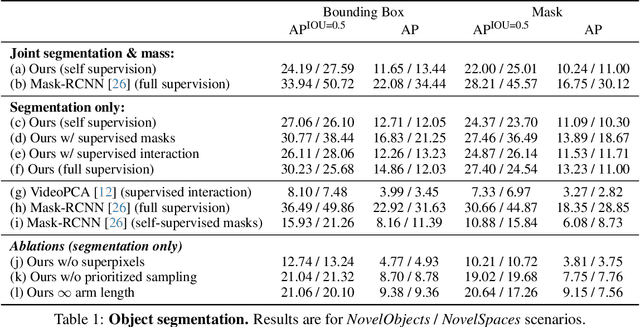
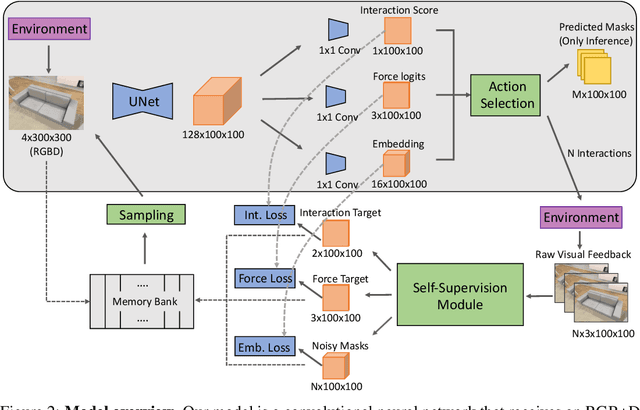

Much of the remarkable progress in computer vision has been focused around fully supervised learning mechanisms relying on highly curated datasets for a variety of tasks. In contrast, humans often learn about their world with little to no external supervision. Taking inspiration from infants learning from their environment through play and interaction, we present a computational framework to discover objects and learn their physical properties along this paradigm of Learning from Interaction. Our agent, when placed within the near photo-realistic and physics-enabled AI2-THOR environment, interacts with its world and learns about objects, their geometric extents and relative masses, without any external guidance. Our experiments reveal that this agent learns efficiently and effectively; not just for objects it has interacted with before, but also for novel instances from seen categories as well as novel object categories.
Visual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image
Apr 22, 2020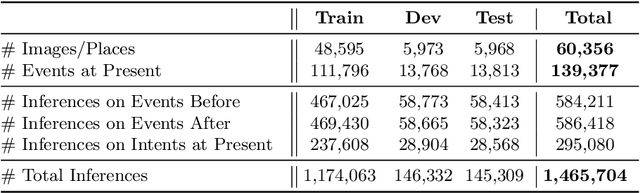
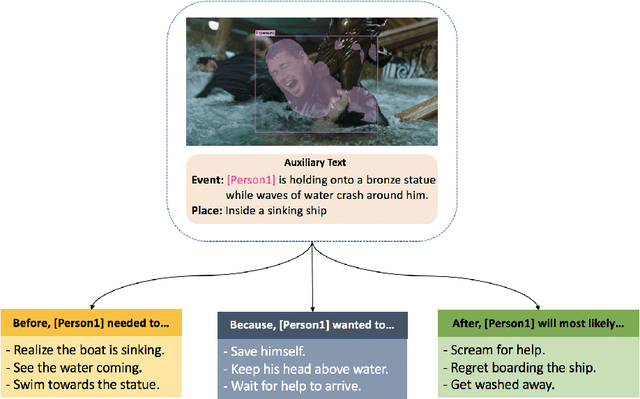
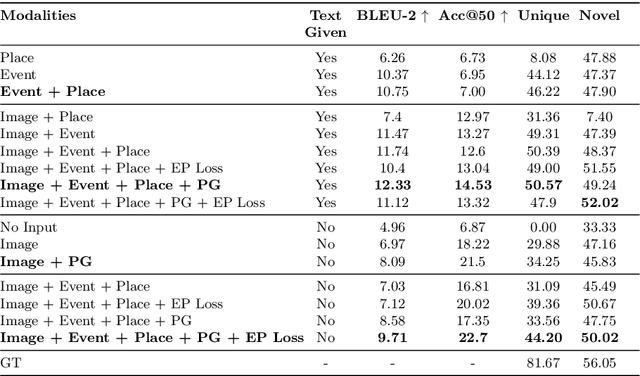

Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. For example, given an image of a man struggling to stay afloat in water, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. We propose VisualComet, the novel framework of visual commonsense reasoning tasks to predict events that might have happened before, events that might happen next, and the intents of the people at present. To support research toward visual commonsense reasoning, we introduce the first large-scale repository of Visual Commonsense Graphs that consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 60,000 images, each paired with short video summaries of before and after. In addition, we provide person-grounding (i.e., co-reference links) between people appearing in the image and people mentioned in the textual commonsense descriptions, allowing for tighter integration between images and text. We establish strong baseline performances on this task and demonstrate that integration between visual and textual commonsense reasoning is the key and wins over non-integrative alternatives.
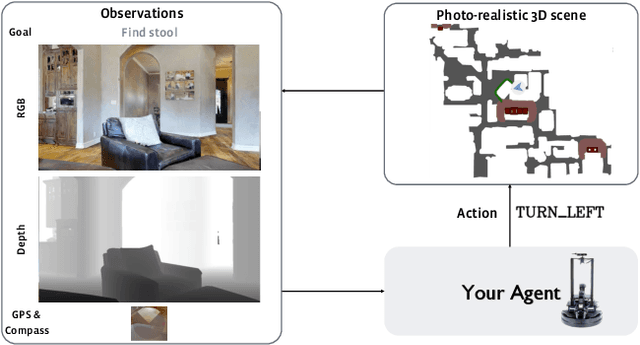
RoboTHOR: An Open Simulation-to-Real Embodied AI Platform
Apr 14, 2020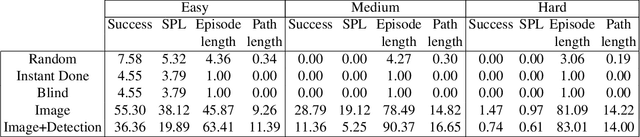
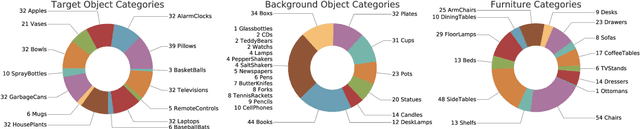

Visual recognition ecosystems (e.g. ImageNet, Pascal, COCO) have undeniably played a prevailing role in the evolution of modern computer vision. We argue that interactive and embodied visual AI has reached a stage of development similar to visual recognition prior to the advent of these ecosystems. Recently, various synthetic environments have been introduced to facilitate research in embodied AI. Notwithstanding this progress, the crucial question of how well models trained in simulation generalize to reality has remained largely unanswered. The creation of a comparable ecosystem for simulation-to-real embodied AI presents many challenges: (1) the inherently interactive nature of the problem, (2) the need for tight alignments between real and simulated worlds, (3) the difficulty of replicating physical conditions for repeatable experiments, (4) and the associated cost. In this paper, we introduce RoboTHOR to democratize research in interactive and embodied visual AI. RoboTHOR offers a framework of simulated environments paired with physical counterparts to systematically explore and overcome the challenges of simulation-to-real transfer, and a platform where researchers across the globe can remotely test their embodied models in the physical world. As a first benchmark, our experiments show there exists a significant gap between the performance of models trained in simulation when they are tested in both simulations and their carefully constructed physical analogs. We hope that RoboTHOR will spur the next stage of evolution in embodied computer vision. RoboTHOR can be accessed at the following link: https://ai2thor.allenai.org/robothor
Artificial Agents Learn Flexible Visual Representations by Playing a Hiding Game
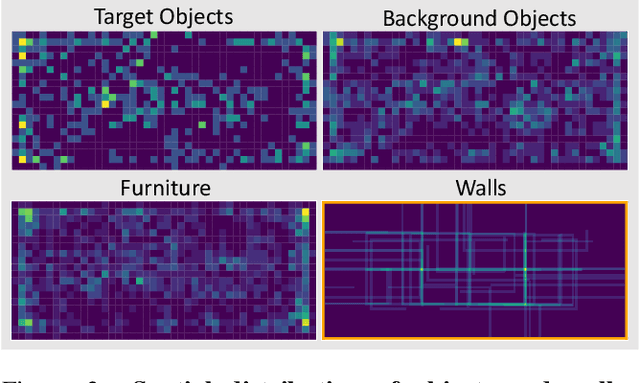
Dec 18, 2019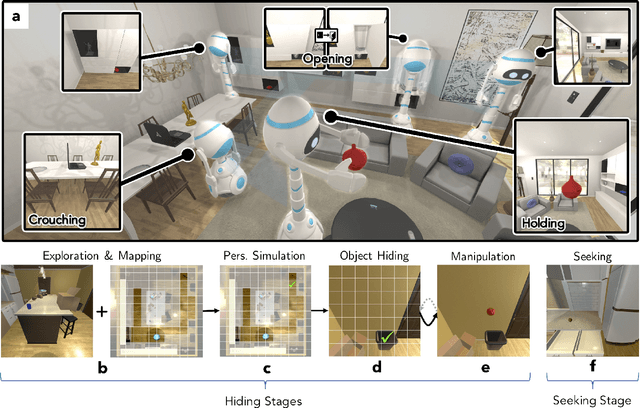
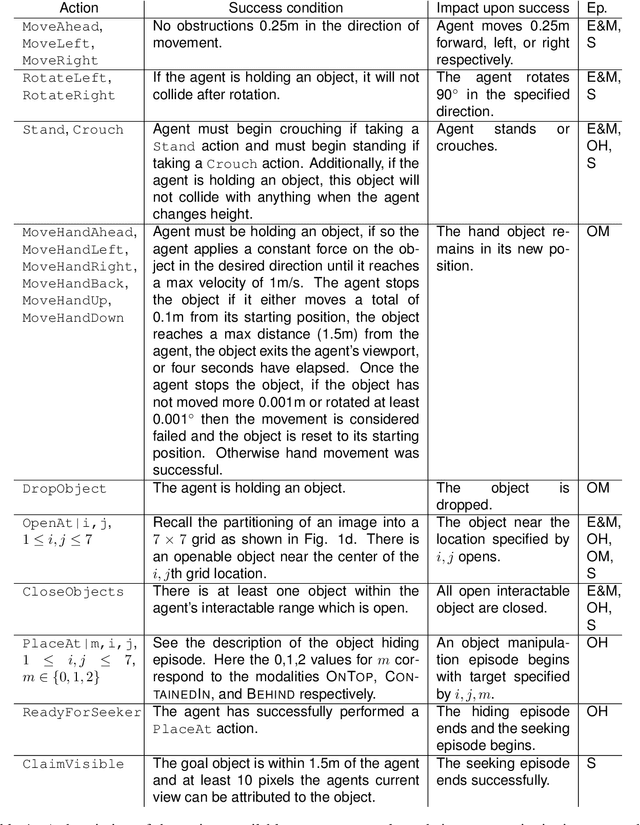

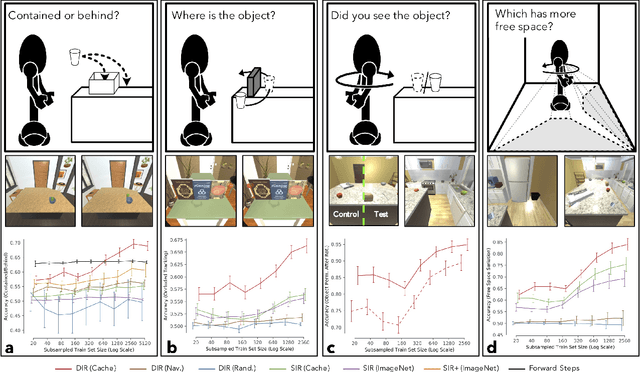
The ubiquity of embodied gameplay, observed in a wide variety of animal species including turtles and ravens, has led researchers to question what advantages play provides to the animals engaged in it. Mounting evidence suggests that play is critical in developing the neural flexibility for creative problem solving, socialization, and can improve the plasticity of the medial prefrontal cortex. Comparatively little is known regarding the impact of gameplay upon embodied artificial agents. While recent work has produced artificial agents proficient in abstract games, the environments these agents act within are far removed the real world and thus these agents provide little insight into the advantages of embodied play. Hiding games have arisen in multiple cultures and species, and provide a rich ground for studying the impact of embodied gameplay on representation learning in the context of perspective taking, secret keeping, and false belief understanding. Here we are the first to show that embodied adversarial reinforcement learning agents playing cache, a variant of hide-and-seek, in a high fidelity, interactive, environment, learn representations of their observations encoding information such as occlusion, object permanence, free space, and containment; on par with representations learnt by the most popular modern paradigm for visual representation learning which requires large datasets independently labeled for each new task. Our representations are enhanced by intent and memory, through interaction and play, moving closer to biologically motivated learning strategies. These results serve as a model for studying how facets of vision and perspective taking develop through play, provide an experimental framework for assessing what is learned by artificial agents, and suggest that representation learning should move from static datasets and towards experiential, interactive, learning.
Visual Reaction: Learning to Play Catch with Your Drone
Dec 04, 2019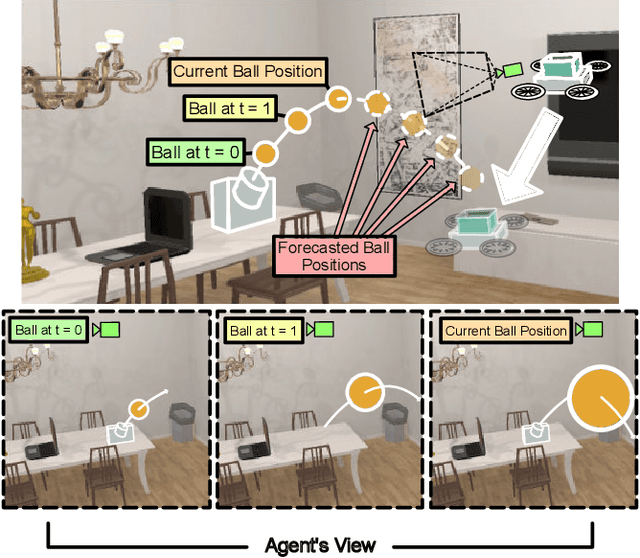
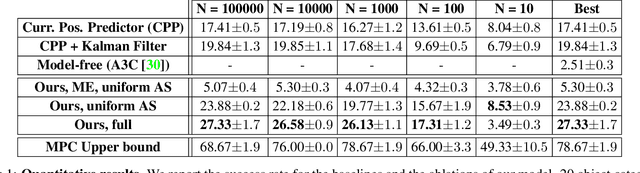
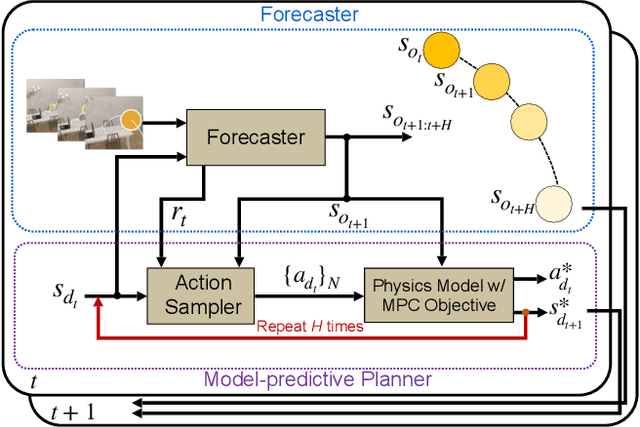

In this paper we address the problem of visual reaction: the task of interacting with dynamic environments where the changes in the environment are not necessarily caused by the agents itself. Visual reaction entails predicting the future changes in a visual environment and planning accordingly. We study the problem of visual reaction in the context of playing catch with a drone in visually rich synthetic environments. This is a challenging problem since the agent is required to learn (1) how objects with different physical properties and shapes move, (2) what sequence of actions should be taken according to the prediction, (3) how to adjust the actions based on the visual feedback from the dynamic environment (e.g., when objects bouncing off a wall), and (4) how to reason and act with an unexpected state change in a timely manner. We propose a new dataset for this task, which includes 30K throws of 20 types of objects in different directions with different forces. Our results show that our model that integrates a forecaster with a planner outperforms a set of strong baselines that are based on tracking as well as pure model-based and model-free RL baselines.
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
Dec 03, 2019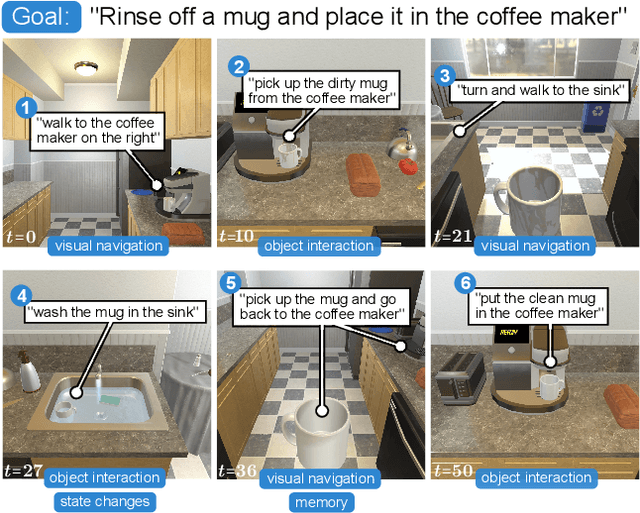
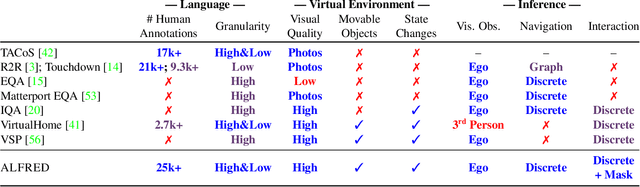
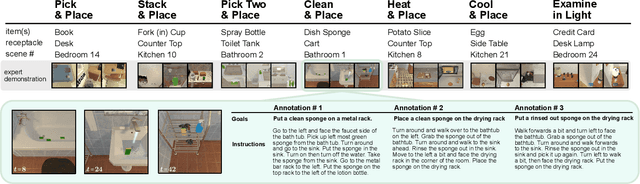
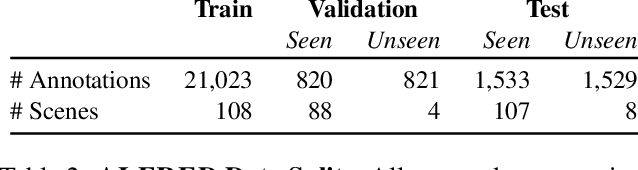
We present ALFRED (Action Learning From Realistic Environments and Directives), a benchmark for learning a mapping from natural language instructions and egocentric vision to sequences of actions for household tasks. Long composition rollouts with non-reversible state changes are among the phenomena we include to shrink the gap between research benchmarks and real-world applications. ALFRED consists of expert demonstrations in interactive visual environments for 25k natural language directives. These directives contain both high-level goals like "Rinse off a mug and place it in the coffee maker." and low-level language instructions like "Walk to the coffee maker on the right." ALFRED tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets. We show that a baseline model designed for recent embodied vision-and-language tasks performs poorly on ALFRED, suggesting that there is significant room for developing innovative grounded visual language understanding models with this benchmark.
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
May 31, 2019


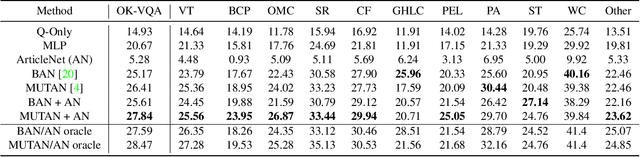
Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benchmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain. See http://okvqa.allenai.org to download and browse the dataset.