 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustNav: Towards Benchmarking Robustness in Embodied Navigation
Jun 08, 2021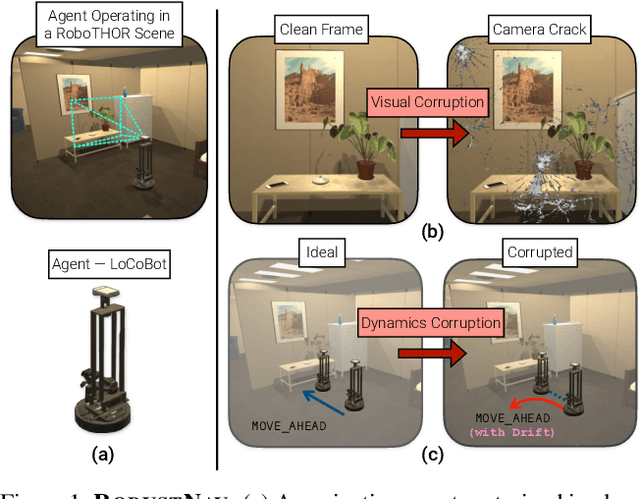
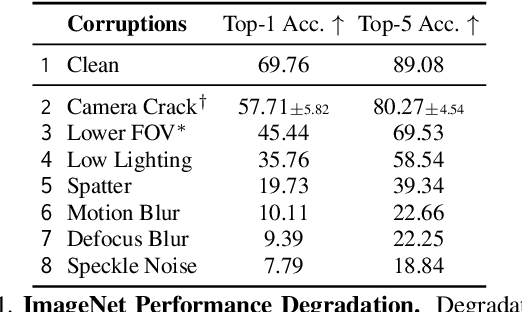

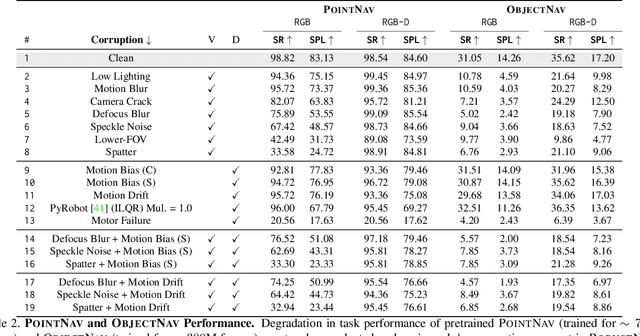
As an attempt towards assessing the robustness of embodied navigation agents, we propose RobustNav, a framework to quantify the performance of embodied navigation agents when exposed to a wide variety of visual - affecting RGB inputs - and dynamics - affecting transition dynamics - corruptions. Most recent efforts in visual navigation have typically focused on generalizing to novel target environments with similar appearance and dynamics characteristics. With RobustNav, we find that some standard embodied navigation agents significantly underperform (or fail) in the presence of visual or dynamics corruptions. We systematically analyze the kind of idiosyncrasies that emerge in the behavior of such agents when operating under corruptions. Finally, for visual corruptions in RobustNav, we show that while standard techniques to improve robustness such as data-augmentation and self-supervised adaptation offer some zero-shot resistance and improvements in navigation performance, there is still a long way to go in terms of recovering lost performance relative to clean "non-corrupt" settings, warranting more research in this direction. Our code is available at https://github.com/allenai/robustnav
Container: Context Aggregation Network
Jun 02, 2021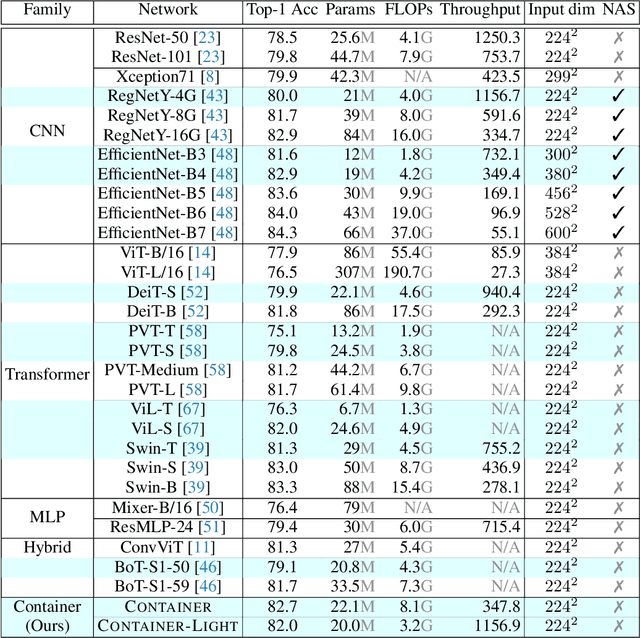
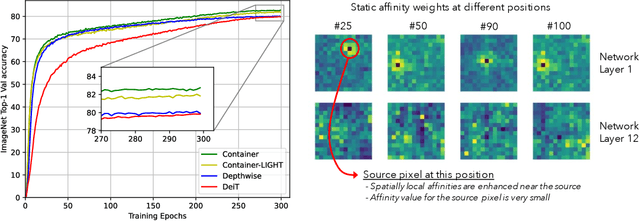
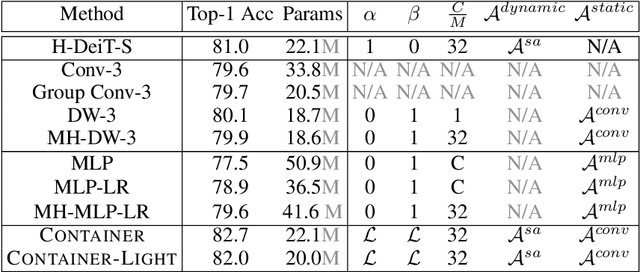
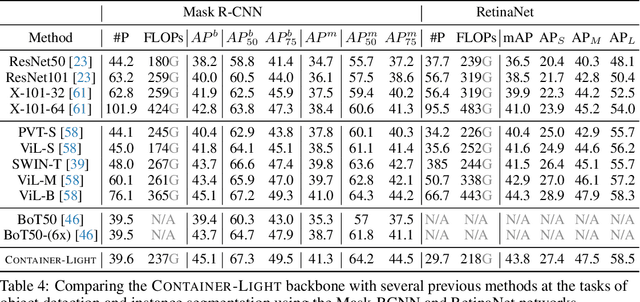
Convolutional neural networks (CNNs) are ubiquitous in computer vision, with a myriad of effective and efficient variations. Recently, Transformers -- originally introduced in natural language processing -- have been increasingly adopted in computer vision. While early adopters continue to employ CNN backbones, the latest networks are end-to-end CNN-free Transformer solutions. A recent surprising finding shows that a simple MLP based solution without any traditional convolutional or Transformer components can produce effective visual representations. While CNNs, Transformers and MLP-Mixers may be considered as completely disparate architectures, we provide a unified view showing that they are in fact special cases of a more general method to aggregate spatial context in a neural network stack. We present the \model (CONText AggregatIon NEtwoRk), a general-purpose building block for multi-head context aggregation that can exploit long-range interactions \emph{a la} Transformers while still exploiting the inductive bias of the local convolution operation leading to faster convergence speeds, often seen in CNNs. In contrast to Transformer-based methods that do not scale well to downstream tasks that rely on larger input image resolutions, our efficient network, named \modellight, can be employed in object detection and instance segmentation networks such as DETR, RetinaNet and Mask-RCNN to obtain an impressive detection mAP of 38.9, 43.8, 45.1 and mask mAP of 41.3, providing large improvements of 6.6, 7.3, 6.9 and 6.6 pts respectively, compared to a ResNet-50 backbone with a comparable compute and parameter size. Our method also achieves promising results on self-supervised learning compared to DeiT on the DINO framework.
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
Jun 01, 2021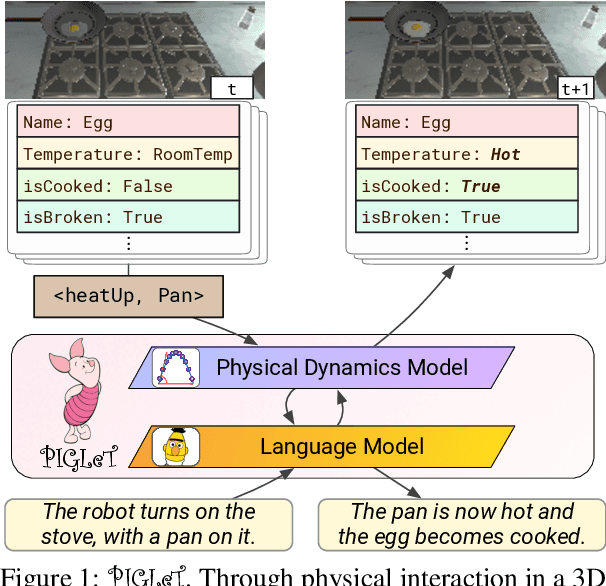
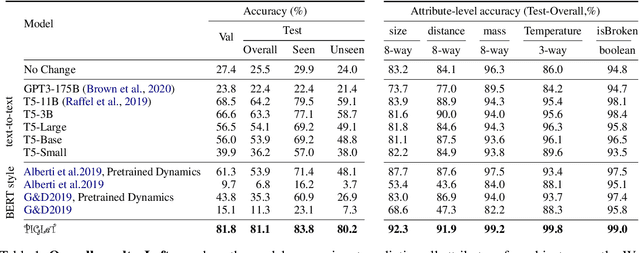

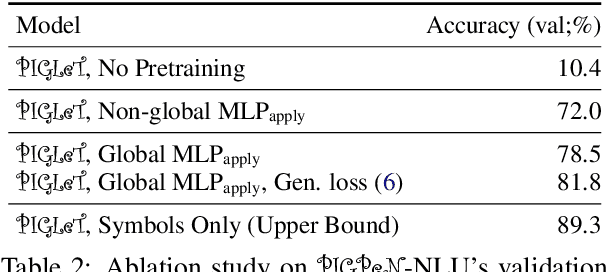
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don't. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast "what happens next" given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
Pushing it out of the Way: Interactive Visual Navigation
May 02, 2021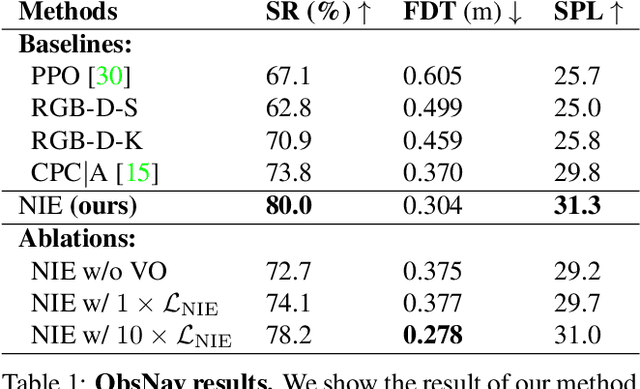
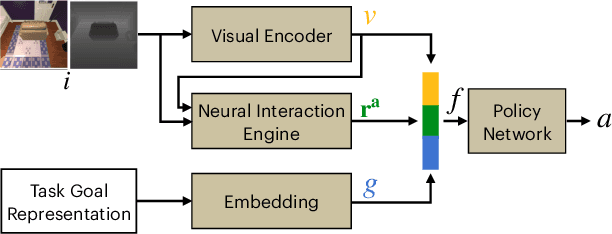
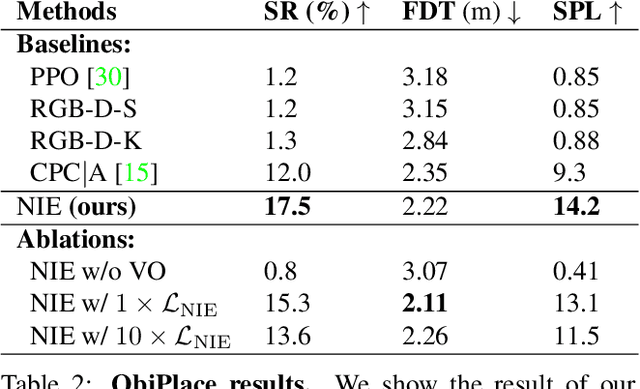
We have observed significant progress in visual navigation for embodied agents. A common assumption in studying visual navigation is that the environments are static; this is a limiting assumption. Intelligent navigation may involve interacting with the environment beyond just moving forward/backward and turning left/right. Sometimes, the best way to navigate is to push something out of the way. In this paper, we study the problem of interactive navigation where agents learn to change the environment to navigate more efficiently to their goals. To this end, we introduce the Neural Interaction Engine (NIE) to explicitly predict the change in the environment caused by the agent's actions. By modeling the changes while planning, we find that agents exhibit significant improvements in their navigational capabilities. More specifically, we consider two downstream tasks in the physics-enabled, visually rich, AI2-THOR environment: (1) reaching a target while the path to the target is blocked (2) moving an object to a target location by pushing it. For both tasks, agents equipped with an NIE significantly outperform agents without the understanding of the effect of the actions indicating the benefits of our approach.
ManipulaTHOR: A Framework for Visual Object Manipulation
Apr 22, 2021
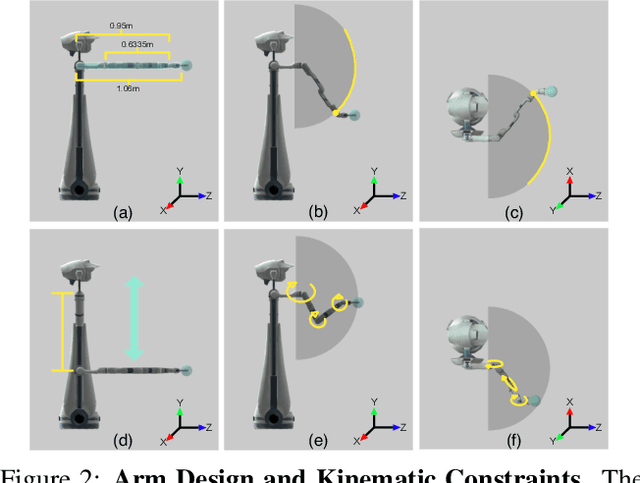
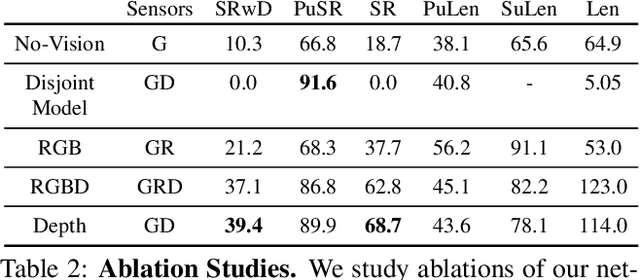

The domain of Embodied AI has recently witnessed substantial progress, particularly in navigating agents within their environments. These early successes have laid the building blocks for the community to tackle tasks that require agents to actively interact with objects in their environment. Object manipulation is an established research domain within the robotics community and poses several challenges including manipulator motion, grasping and long-horizon planning, particularly when dealing with oft-overlooked practical setups involving visually rich and complex scenes, manipulation using mobile agents (as opposed to tabletop manipulation), and generalization to unseen environments and objects. We propose a framework for object manipulation built upon the physics-enabled, visually rich AI2-THOR framework and present a new challenge to the Embodied AI community known as ArmPointNav. This task extends the popular point navigation task to object manipulation and offers new challenges including 3D obstacle avoidance, manipulating objects in the presence of occlusion, and multi-object manipulation that necessitates long term planning. Popular learning paradigms that are successful on PointNav challenges show promise, but leave a large room for improvement.
Visual Room Rearrangement
Mar 30, 2021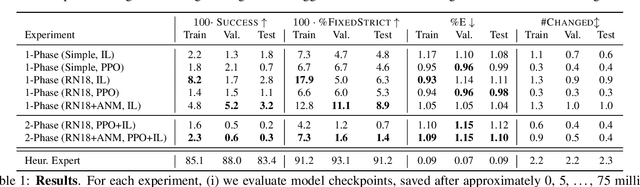
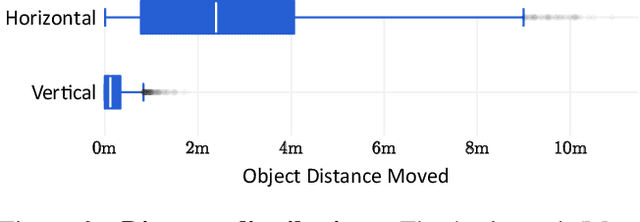
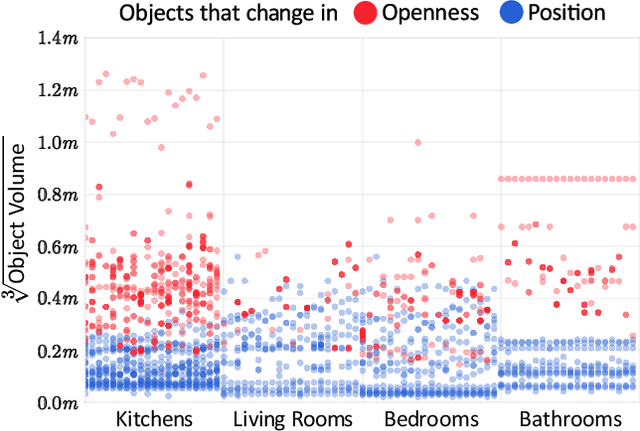
There has been a significant recent progress in the field of Embodied AI with researchers developing models and algorithms enabling embodied agents to navigate and interact within completely unseen environments. In this paper, we propose a new dataset and baseline models for the task of Rearrangement. We particularly focus on the task of Room Rearrangement: an agent begins by exploring a room and recording objects' initial configurations. We then remove the agent and change the poses and states (e.g., open/closed) of some objects in the room. The agent must restore the initial configurations of all objects in the room. Our dataset, named RoomR, includes 6,000 distinct rearrangement settings involving 72 different object types in 120 scenes. Our experiments show that solving this challenging interactive task that involves navigation and object interaction is beyond the capabilities of the current state-of-the-art techniques for embodied tasks and we are still very far from achieving perfect performance on these types of tasks. The code and the dataset are available at: https://ai2thor.allenai.org/rearrangement
Contrasting Contrastive Self-Supervised Representation Learning Models
Mar 25, 2021
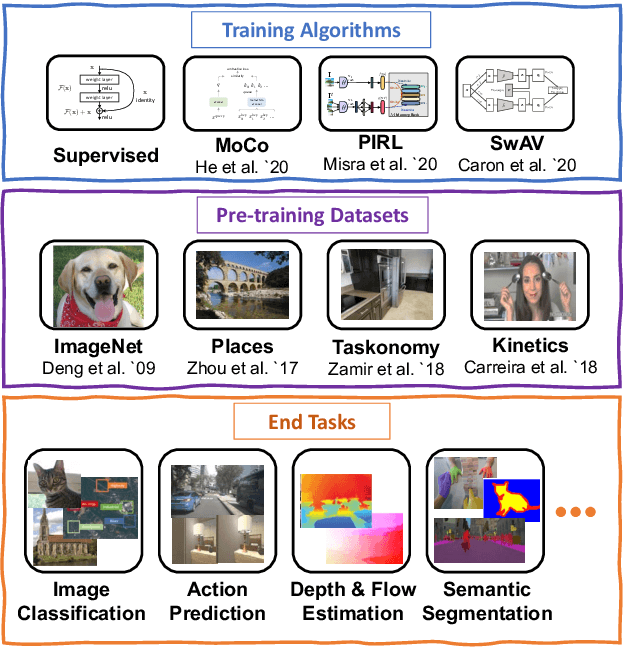

In the past few years, we have witnessed remarkable breakthroughs in self-supervised representation learning. Despite the success and adoption of representations learned through this paradigm, much is yet to be understood about how different training methods and datasets influence performance on downstream tasks. In this paper, we analyze contrastive approaches as one of the most successful and popular variants of self-supervised representation learning. We perform this analysis from the perspective of the training algorithms, pre-training datasets and end tasks. We examine over 700 training experiments including 30 encoders, 4 pre-training datasets and 20 diverse downstream tasks. Our experiments address various questions regarding the performance of self-supervised models compared to their supervised counterparts, current benchmarks used for evaluation, and the effect of the pre-training data on end task performance. We hope the insights and empirical evidence provided by this work will help future research in learning better visual representations.
Multi-Modal Answer Validation for Knowledge-Based VQA
Mar 23, 2021
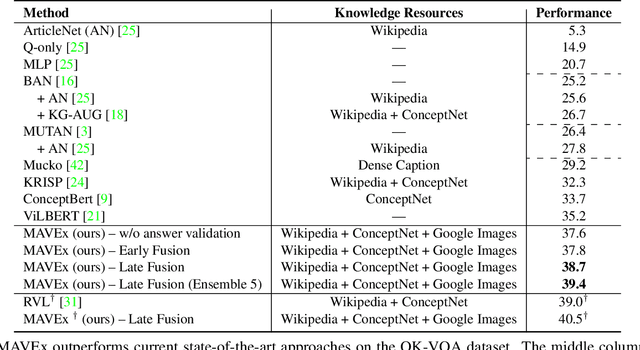

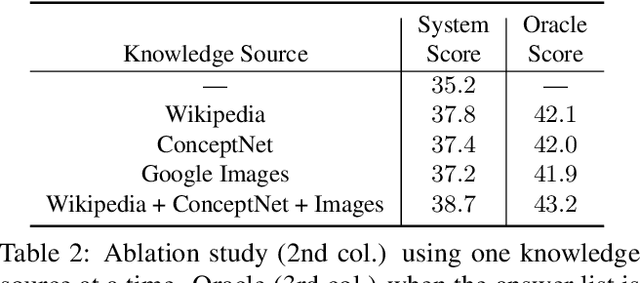
The problem of knowledge-based visual question answering involves answering questions that require external knowledge in addition to the content of the image. Such knowledge typically comes in a variety of forms, including visual, textual, and commonsense knowledge. The use of more knowledge sources, however, also increases the chance of retrieving more irrelevant or noisy facts, making it difficult to comprehend the facts and find the answer. To address this challenge, we propose Multi-modal Answer Validation using External knowledge (MAVEx), where the idea is to validate a set of promising answer candidates based on answer-specific knowledge retrieval. This is in contrast to existing approaches that search for the answer in a vast collection of often irrelevant facts. Our approach aims to learn which knowledge source should be trusted for each answer candidate and how to validate the candidate using that source. We consider a multi-modal setting, relying on both textual and visual knowledge resources, including images searched using Google, sentences from Wikipedia articles, and concepts from ConceptNet. Our experiments with OK-VQA, a challenging knowledge-based VQA dataset, demonstrate that MAVEx achieves new state-of-the-art results.
MOCA: A Modular Object-Centric Approach for Interactive Instruction Following
Dec 06, 2020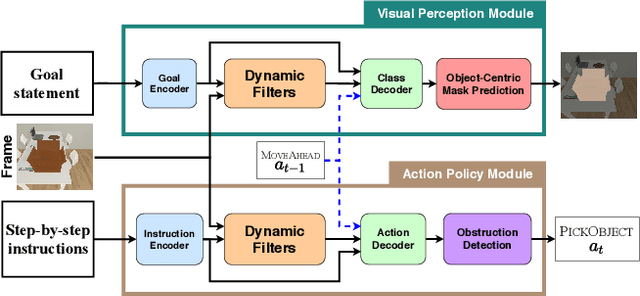
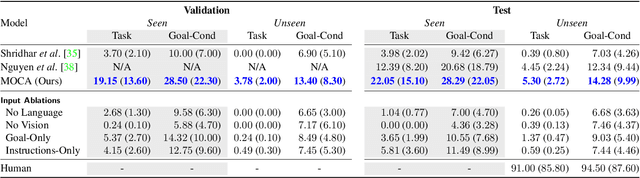
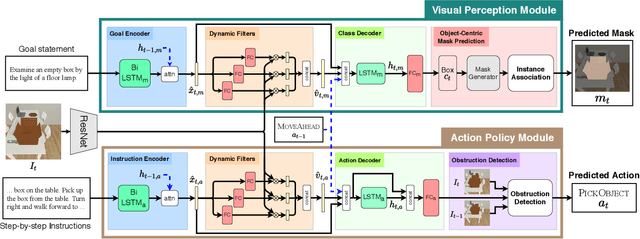
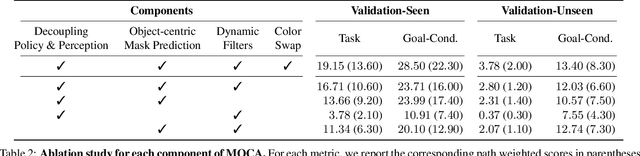
Performing simple household tasks based on language directives is very natural to humans, yet it remains an open challenge for an AI agent. Recently, an `interactive instruction following' task has been proposed to foster research in reasoning over long instruction sequences that requires object interactions in a simulated environment. It involves solving open problems in vision, language and navigation literature at each step. To address this multifaceted problem, we propose a modular architecture that decouples the task into visual perception and action policy, and name it as MOCA, a Modular Object-Centric Approach. We evaluate our method on the ALFRED benchmark and empirically validate that it outperforms prior arts by significant margins in all metrics with good generalization performance (high success rate in unseen environments). Our code is available at https://github.com/gistvision/moca.
Rearrangement: A Challenge for Embodied AI
Nov 03, 2020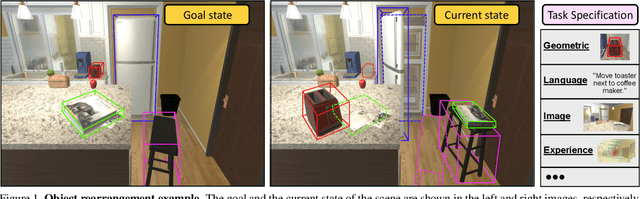
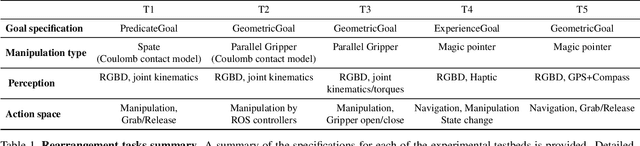


We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.