 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntroformer: A Transformer-based Entropy Model for Learned Image Compression
Feb 11, 2022

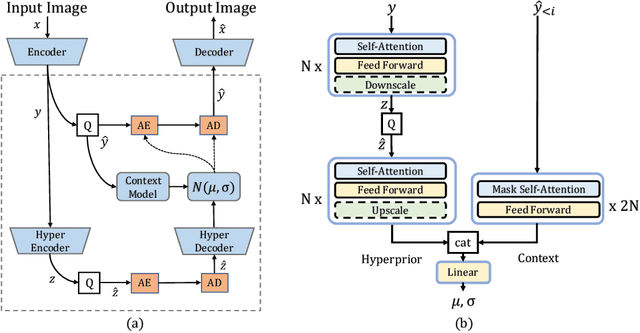

One critical component in lossy deep image compression is the entropy model, which predicts the probability distribution of the quantized latent representation in the encoding and decoding modules. Previous works build entropy models upon convolutional neural networks which are inefficient in capturing global dependencies. In this work, we propose a novel transformer-based entropy model, termed Entroformer, to capture long-range dependencies in probability distribution estimation effectively and efficiently. Different from vision transformers in image classification, the Entroformer is highly optimized for image compression, including a top-k self-attention and a diamond relative position encoding. Meanwhile, we further expand this architecture with a parallel bidirectional context model to speed up the decoding process. The experiments show that the Entroformer achieves state-of-the-art performance on image compression while being time-efficient.
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
Jan 30, 2022
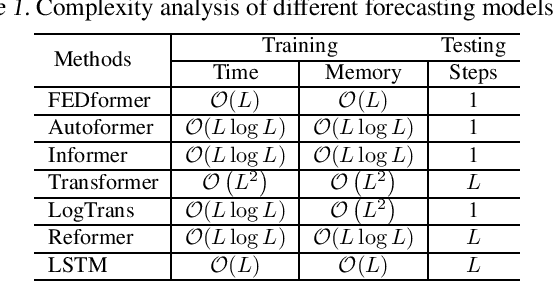
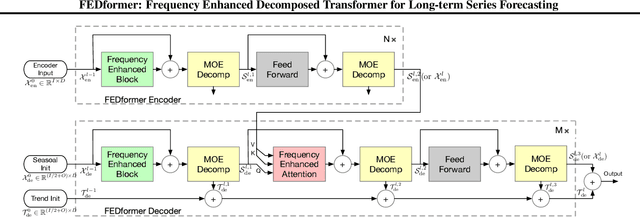
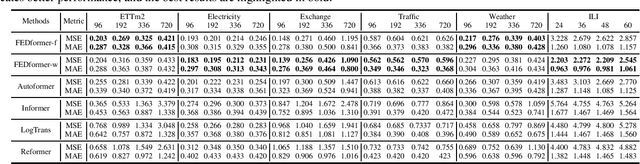
Although Transformer-based methods have significantly improved state-of-the-art results for long-term series forecasting, they are not only computationally expensive but more importantly, are unable to capture the global view of time series (e.g. overall trend). To address these problems, we propose to combine Transformer with the seasonal-trend decomposition method, in which the decomposition method captures the global profile of time series while Transformers capture more detailed structures. To further enhance the performance of Transformer for long-term prediction, we exploit the fact that most time series tend to have a sparse representation in well-known basis such as Fourier transform, and develop a frequency enhanced Transformer. Besides being more effective, the proposed method, termed as Frequency Enhanced Decomposed Transformer ({\bf FEDformer}), is more efficient than standard Transformer with a linear complexity to the sequence length. Our empirical studies with six benchmark datasets show that compared with state-of-the-art methods, FEDformer can reduce prediction error by $14.8\%$ and $22.6\%$ for multivariate and univariate time series, respectively. the code will be released soon.
ELSA: Enhanced Local Self-Attention for Vision Transformer
Dec 23, 2021
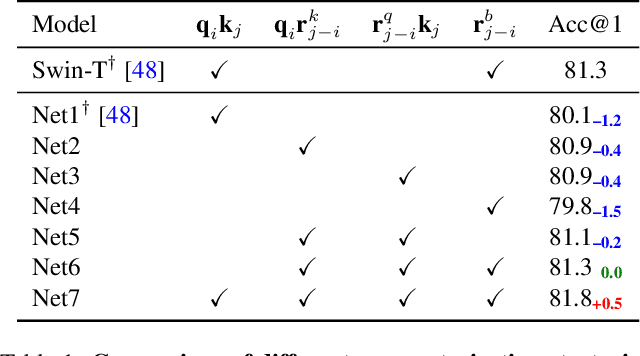
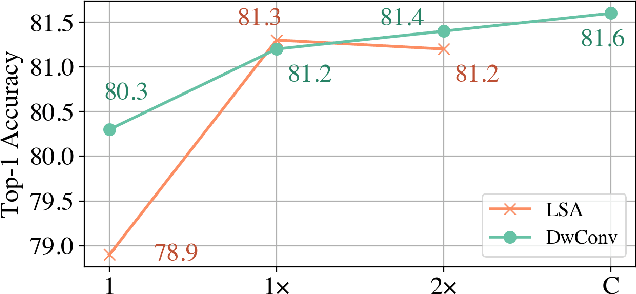

Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning. The performance of local self-attention (LSA) is just on par with convolution and inferior to dynamic filters, which puzzles researchers on whether to use LSA or its counterparts, which one is better, and what makes LSA mediocre. To clarify these, we comprehensively investigate LSA and its counterparts from two sides: \emph{channel setting} and \emph{spatial processing}. We find that the devil lies in the generation and application of spatial attention, where relative position embeddings and the neighboring filter application are key factors. Based on these findings, we propose the enhanced local self-attention (ELSA) with Hadamard attention and the ghost head. Hadamard attention introduces the Hadamard product to efficiently generate attention in the neighboring case, while maintaining the high-order mapping. The ghost head combines attention maps with static matrices to increase channel capacity. Experiments demonstrate the effectiveness of ELSA. Without architecture / hyperparameter modification, drop-in replacing LSA with ELSA boosts Swin Transformer \cite{swin} by up to +1.4 on top-1 accuracy. ELSA also consistently benefits VOLO \cite{volo} from D1 to D5, where ELSA-VOLO-D5 achieves 87.2 on the ImageNet-1K without extra training images. In addition, we evaluate ELSA in downstream tasks. ELSA significantly improves the baseline by up to +1.9 box Ap / +1.3 mask Ap on the COCO, and by up to +1.9 mIoU on the ADE20K. Code is available at \url{https://github.com/damo-cv/ELSA}.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021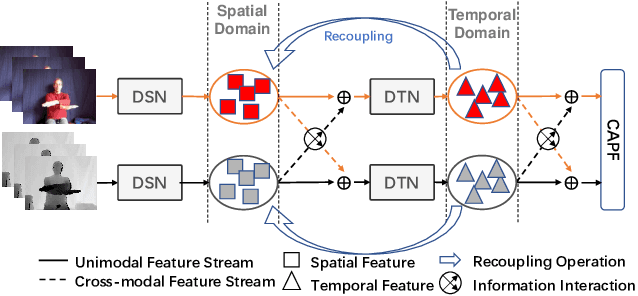
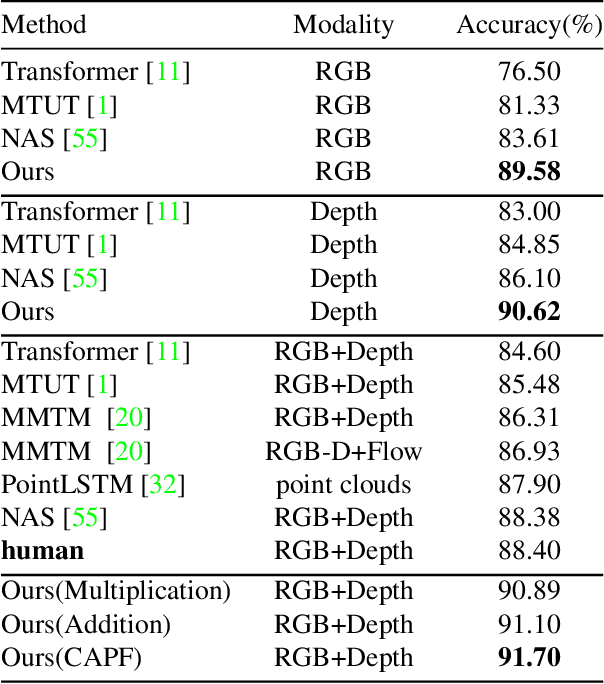
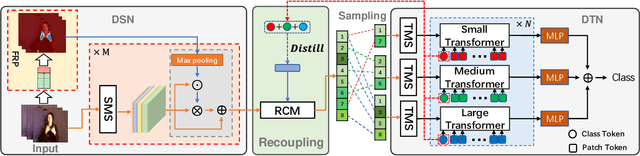
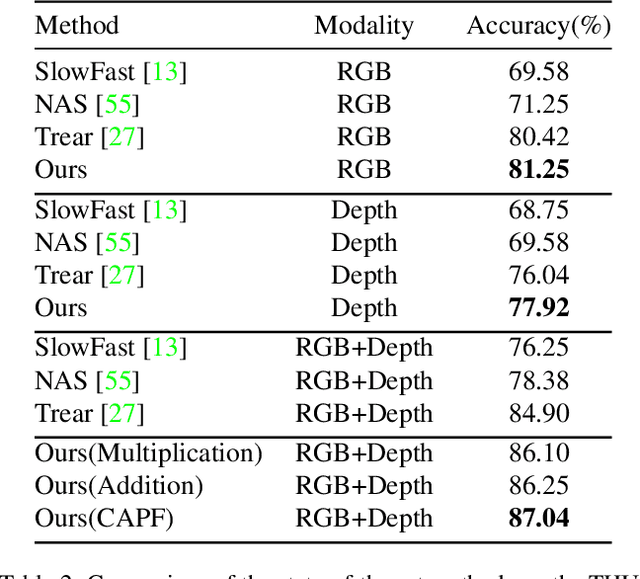
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
A Novel Convergence Analysis for Algorithms of the Adam Family
Dec 07, 2021

Since its invention in 2014, the Adam optimizer has received tremendous attention. On one hand, it has been widely used in deep learning and many variants have been proposed, while on the other hand their theoretical convergence property remains to be a mystery. It is far from satisfactory in the sense that some studies require strong assumptions about the updates, which are not necessarily applicable in practice, while other studies still follow the original problematic convergence analysis of Adam, which was shown to be not sufficient to ensure convergence. Although rigorous convergence analysis exists for Adam, they impose specific requirements on the update of the adaptive step size, which are not generic enough to cover many other variants of Adam. To address theses issues, in this extended abstract, we present a simple and generic proof of convergence for a family of Adam-style methods (including Adam, AMSGrad, Adabound, etc.). Our analysis only requires an increasing or large "momentum" parameter for the first-order moment, which is indeed the case used in practice, and a boundness condition on the adaptive factor of the step size, which applies to all variants of Adam under mild conditions of stochastic gradients. We also establish a variance diminishing result for the used stochastic gradient estimators. Indeed, our analysis of Adam is so simple and generic that it can be leveraged to establish the convergence for solving a broader family of non-convex optimization problems, including min-max, compositional, and bilevel optimization problems. For the full (earlier) version of this extended abstract, please refer to arXiv:2104.14840.
TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Dec 02, 2021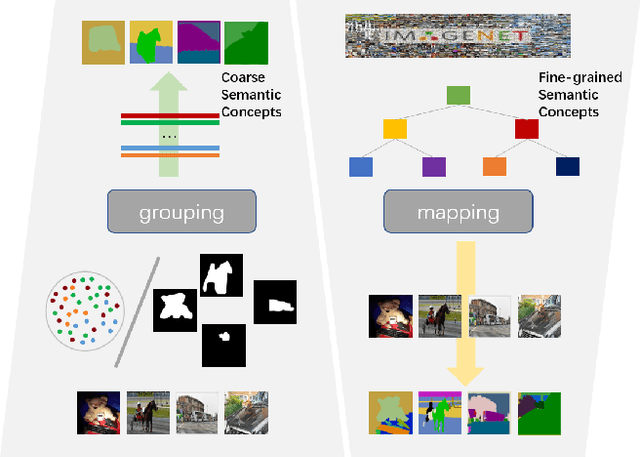
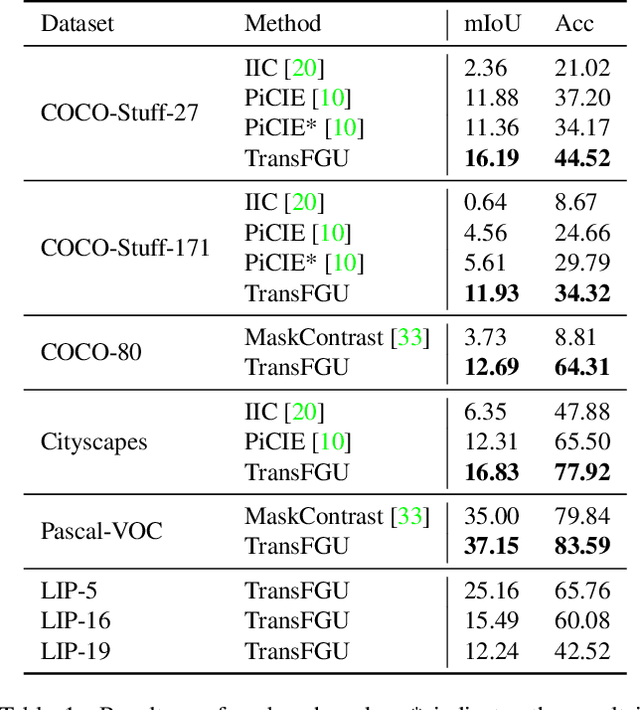
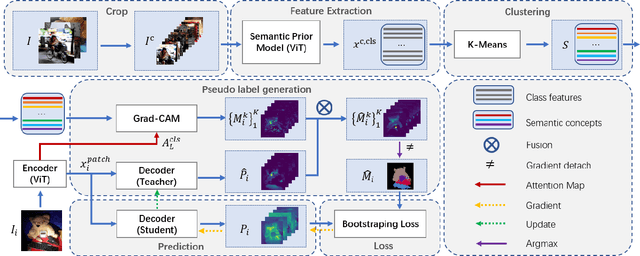
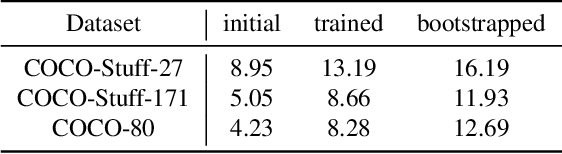
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations. Most existing methods are bottom-up approaches that try to group pixels into regions based on their visual cues or certain predefined rules. As a result, it is difficult for these bottom-up approaches to generate fine-grained semantic segmentation when coming to complicated scenes with multiple objects and some objects sharing similar visual appearance. In contrast, we propose the first top-down unsupervised semantic segmentation framework for fine-grained segmentation in extremely complicated scenarios. Specifically, we first obtain rich high-level structured semantic concept information from large-scale vision data in a self-supervised learning manner, and use such information as a prior to discover potential semantic categories presented in target datasets. Secondly, the discovered high-level semantic categories are mapped to low-level pixel features by calculating the class activate map (CAM) with respect to certain discovered semantic representation. Lastly, the obtained CAMs serve as pseudo labels to train the segmentation module and produce final semantic segmentation. Experimental results on multiple semantic segmentation benchmarks show that our top-down unsupervised segmentation is robust to both object-centric and scene-centric datasets under different semantic granularity levels, and outperforms all the current state-of-the-art bottom-up methods. Our code is available at \url{https://github.com/damo-cv/TransFGU}.
Revisiting Efficient Object Detection Backbones from Zero-Shot Neural Architecture Search
Nov 26, 2021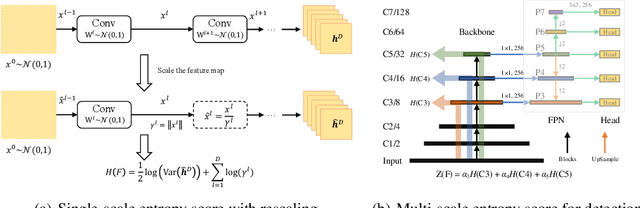
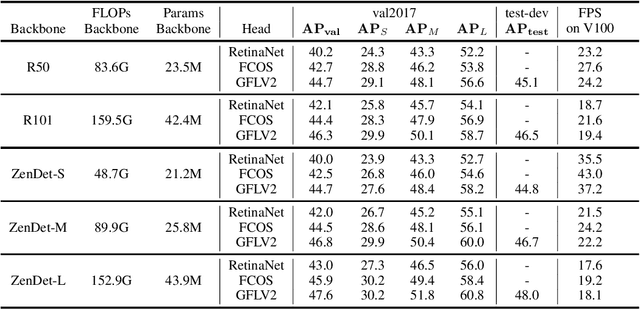
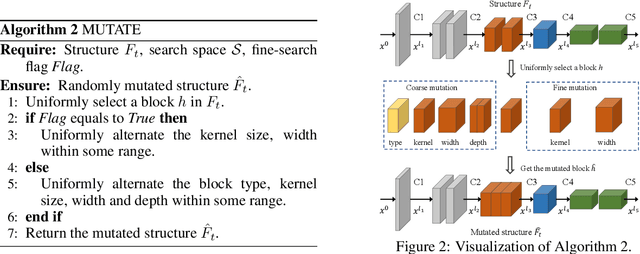
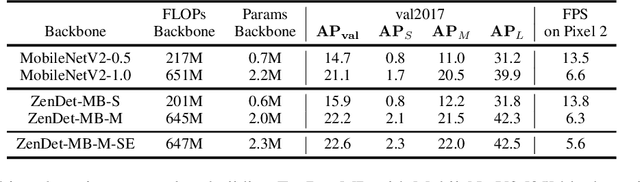
In object detection models, the detection backbone consumes more than half of the overall inference cost. Recent researches attempt to reduce this cost by optimizing the backbone architecture with the help of Neural Architecture Search (NAS). However, existing NAS methods for object detection require hundreds to thousands of GPU hours of searching, making them impractical in fast-paced research and development. In this work, we propose a novel zero-shot NAS method to address this issue. The proposed method, named ZenDet, automatically designs efficient detection backbones without training network parameters, reducing the architecture design cost to nearly zero yet delivering the state-of-the-art (SOTA) performance. Under the hood, ZenDet maximizes the differential entropy of detection backbones, leading to a better feature extractor for object detection under the same computational budgets. After merely one GPU day of fully automatic design, ZenDet innovates SOTA detection backbones on multiple detection benchmark datasets with little human intervention. Comparing to ResNet-50 backbone, ZenDet is +2.0% better in mAP when using the same amount of FLOPs/parameters and is 1.54 times faster on NVIDIA V100 at the same mAP. Code and pre-trained models will be released later.
Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice
Nov 24, 2021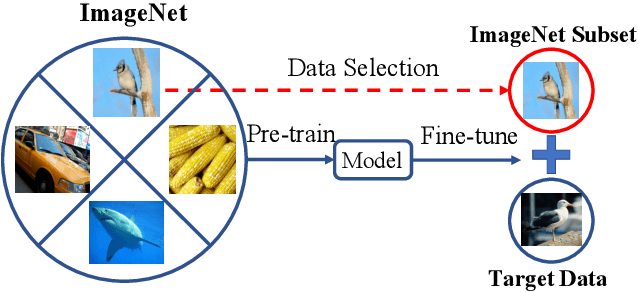
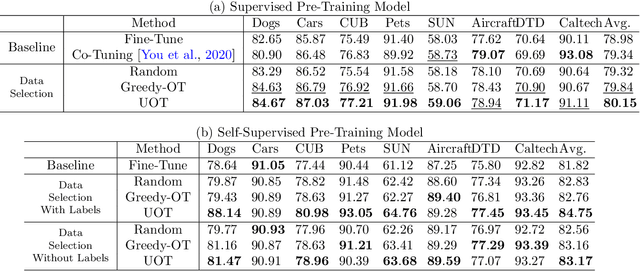
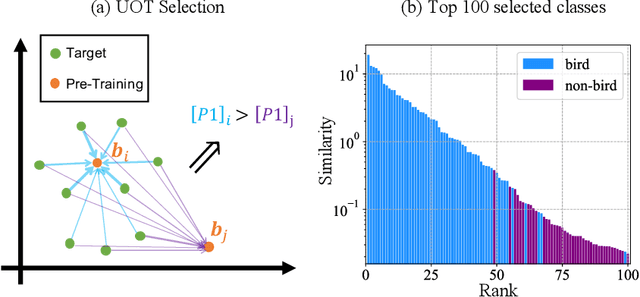

As a dominant paradigm, fine-tuning a pre-trained model on the target data is widely used in many deep learning applications, especially for small data sets. However, recent studies have empirically shown that training from scratch has the final performance that is no worse than this pre-training strategy once the number of training iterations is increased in some vision tasks. In this work, we revisit this phenomenon from the perspective of generalization analysis which is popular in learning theory. Our result reveals that the final prediction precision may have a weak dependency on the pre-trained model especially in the case of large training iterations. The observation inspires us to leverage pre-training data for fine-tuning, since this data is also available for fine-tuning. The generalization result of using pre-training data shows that the final performance on a target task can be improved when the appropriate pre-training data is included in fine-tuning. With the insight of the theoretical finding, we propose a novel selection strategy to select a subset from pre-training data to help improve the generalization on the target task. Extensive experimental results for image classification tasks on 8 benchmark data sets verify the effectiveness of the proposed data selection based fine-tuning pipeline.
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Nov 23, 2021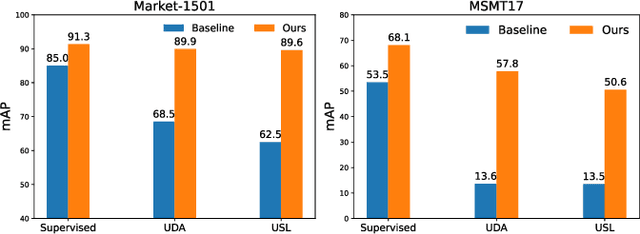
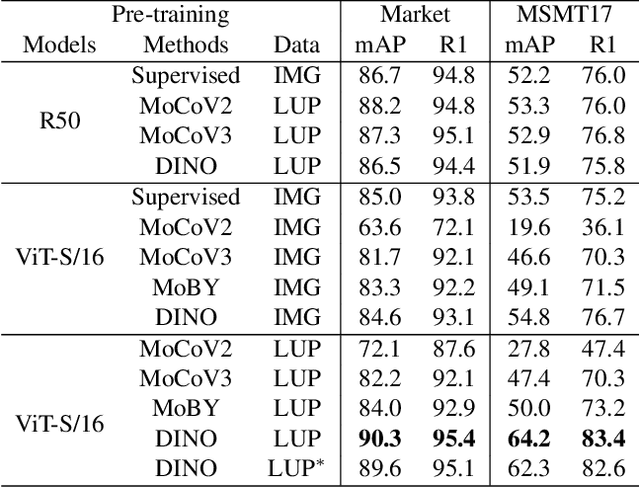
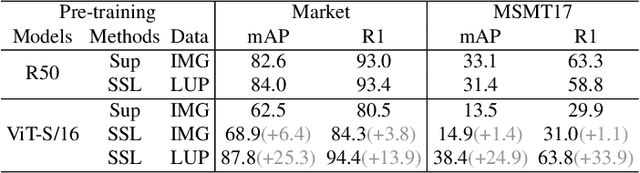
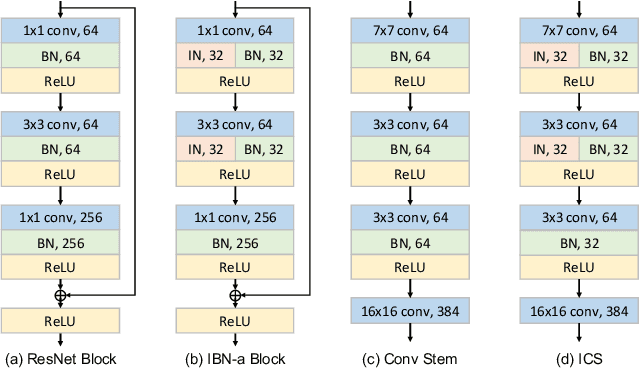
Transformer-based supervised pre-training achieves great performance in person re-identification (ReID). However, due to the domain gap between ImageNet and ReID datasets, it usually needs a larger pre-training dataset (e.g. ImageNet-21K) to boost the performance because of the strong data fitting ability of the transformer. To address this challenge, this work targets to mitigate the gap between the pre-training and ReID datasets from the perspective of data and model structure, respectively. We first investigate self-supervised learning (SSL) methods with Vision Transformer (ViT) pretrained on unlabelled person images (the LUPerson dataset), and empirically find it significantly surpasses ImageNet supervised pre-training models on ReID tasks. To further reduce the domain gap and accelerate the pre-training, the Catastrophic Forgetting Score (CFS) is proposed to evaluate the gap between pre-training and fine-tuning data. Based on CFS, a subset is selected via sampling relevant data close to the down-stream ReID data and filtering irrelevant data from the pre-training dataset. For the model structure, a ReID-specific module named IBN-based convolution stem (ICS) is proposed to bridge the domain gap by learning more invariant features. Extensive experiments have been conducted to fine-tune the pre-training models under supervised learning, unsupervised domain adaptation (UDA), and unsupervised learning (USL) settings. We successfully downscale the LUPerson dataset to 50% with no performance degradation. Finally, we achieve state-of-the-art performance on Market-1501 and MSMT17. For example, our ViT-S/16 achieves 91.3%/89.9%/89.6% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Codes and models will be released to https://github.com/michuanhaohao/TransReID-SSL.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
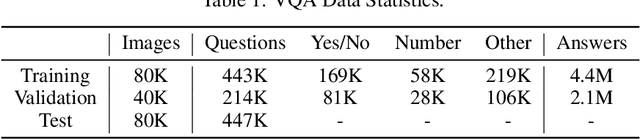
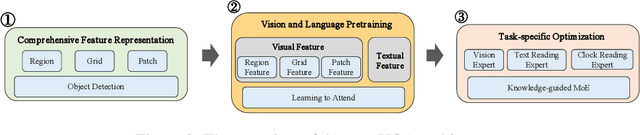
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.