 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
On Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
3DV-TON: Textured 3D-Guided Consistent Video Try-on via Diffusion Models
Apr 24, 2025



Video try-on replaces clothing in videos with target garments. Existing methods struggle to generate high-quality and temporally consistent results when handling complex clothing patterns and diverse body poses. We present 3DV-TON, a novel diffusion-based framework for generating high-fidelity and temporally consistent video try-on results. Our approach employs generated animatable textured 3D meshes as explicit frame-level guidance, alleviating the issue of models over-focusing on appearance fidelity at the expanse of motion coherence. This is achieved by enabling direct reference to consistent garment texture movements throughout video sequences. The proposed method features an adaptive pipeline for generating dynamic 3D guidance: (1) selecting a keyframe for initial 2D image try-on, followed by (2) reconstructing and animating a textured 3D mesh synchronized with original video poses. We further introduce a robust rectangular masking strategy that successfully mitigates artifact propagation caused by leaking clothing information during dynamic human and garment movements. To advance video try-on research, we introduce HR-VVT, a high-resolution benchmark dataset containing 130 videos with diverse clothing types and scenarios. Quantitative and qualitative results demonstrate our superior performance over existing methods. The project page is at this link https://2y7c3.github.io/3DV-TON/
RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
Apr 21, 2025



Controllable character animation remains a challenging problem, particularly in handling rare poses, stylized characters, character-object interactions, complex illumination, and dynamic scenes. To tackle these issues, prior work has largely focused on injecting pose and appearance guidance via elaborate bypass networks, but often struggles to generalize to open-world scenarios. In this paper, we propose a new perspective that, as long as the foundation model is powerful enough, straightforward model modifications with flexible fine-tuning strategies can largely address the above challenges, taking a step towards controllable character animation in the wild. Specifically, we introduce RealisDance-DiT, built upon the Wan-2.1 video foundation model. Our sufficient analysis reveals that the widely adopted Reference Net design is suboptimal for large-scale DiT models. Instead, we demonstrate that minimal modifications to the foundation model architecture yield a surprisingly strong baseline. We further propose the low-noise warmup and "large batches and small iterations" strategies to accelerate model convergence during fine-tuning while maximally preserving the priors of the foundation model. In addition, we introduce a new test dataset that captures diverse real-world challenges, complementing existing benchmarks such as TikTok dataset and UBC fashion video dataset, to comprehensively evaluate the proposed method. Extensive experiments show that RealisDance-DiT outperforms existing methods by a large margin.
Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation
Apr 21, 2025



Camera and human motion controls have been extensively studied for video generation, but existing approaches typically address them separately, suffering from limited data with high-quality annotations for both aspects. To overcome this, we present Uni3C, a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions. First, we propose a plug-and-play control module trained with a frozen video generative backbone, PCDController, which utilizes unprojected point clouds from monocular depth to achieve accurate camera control. By leveraging the strong 3D priors of point clouds and the powerful capacities of video foundational models, PCDController shows impressive generalization, performing well regardless of whether the inference backbone is frozen or fine-tuned. This flexibility enables different modules of Uni3C to be trained in specific domains, i.e., either camera control or human motion control, reducing the dependency on jointly annotated data. Second, we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion, respectively. Extensive experiments confirm that PCDController enjoys strong robustness in driving camera motion for fine-tuned backbones of video generation. Uni3C substantially outperforms competitors in both camera controllability and human motion quality. Additionally, we collect tailored validation sets featuring challenging camera movements and human actions to validate the effectiveness of our method.
RealisDance: Equip controllable character animation with realistic hands
Sep 10, 2024Controllable character animation is an emerging task that generates character videos controlled by pose sequences from given character images. Although character consistency has made significant progress via reference UNet, another crucial factor, pose control, has not been well studied by existing methods yet, resulting in several issues: 1) The generation may fail when the input pose sequence is corrupted. 2) The hands generated using the DWPose sequence are blurry and unrealistic. 3) The generated video will be shaky if the pose sequence is not smooth enough. In this paper, we present RealisDance to handle all the above issues. RealisDance adaptively leverages three types of poses, avoiding failed generation caused by corrupted pose sequences. Among these pose types, HaMeR provides accurate 3D and depth information of hands, enabling RealisDance to generate realistic hands even for complex gestures. Besides using temporal attention in the main UNet, RealisDance also inserts temporal attention into the pose guidance network, smoothing the video from the pose condition aspect. Moreover, we introduce pose shuffle augmentation during training to further improve generation robustness and video smoothness. Qualitative experiments demonstrate the superiority of RealisDance over other existing methods, especially in hand quality.
RealisHuman: A Two-Stage Approach for Refining Malformed Human Parts in Generated Images
Sep 05, 2024



In recent years, diffusion models have revolutionized visual generation, outperforming traditional frameworks like Generative Adversarial Networks (GANs). However, generating images of humans with realistic semantic parts, such as hands and faces, remains a significant challenge due to their intricate structural complexity. To address this issue, we propose a novel post-processing solution named RealisHuman. The RealisHuman framework operates in two stages. First, it generates realistic human parts, such as hands or faces, using the original malformed parts as references, ensuring consistent details with the original image. Second, it seamlessly integrates the rectified human parts back into their corresponding positions by repainting the surrounding areas to ensure smooth and realistic blending. The RealisHuman framework significantly enhances the realism of human generation, as demonstrated by notable improvements in both qualitative and quantitative metrics. Code is available at https://github.com/Wangbenzhi/RealisHuman.
Adversarial Score Distillation: When score distillation meets GAN
Dec 01, 2023Existing score distillation methods are sensitive to classifier-free guidance (CFG) scale: manifested as over-smoothness or instability at small CFG scales, while over-saturation at large ones. To explain and analyze these issues, we revisit the derivation of Score Distillation Sampling (SDS) and decipher existing score distillation with the Wasserstein Generative Adversarial Network (WGAN) paradigm. With the WGAN paradigm, we find that existing score distillation either employs a fixed sub-optimal discriminator or conducts incomplete discriminator optimization, resulting in the scale-sensitive issue. We propose the Adversarial Score Distillation (ASD), which maintains an optimizable discriminator and updates it using the complete optimization objective. Experiments show that the proposed ASD performs favorably in 2D distillation and text-to-3D tasks against existing methods. Furthermore, to explore the generalization ability of our WGAN paradigm, we extend ASD to the image editing task, which achieves competitive results. The project page and code are at https://github.com/2y7c3/ASD.
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.
ELSA: Enhanced Local Self-Attention for Vision Transformer
Dec 23, 2021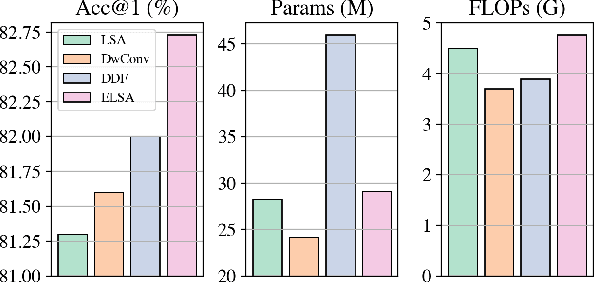
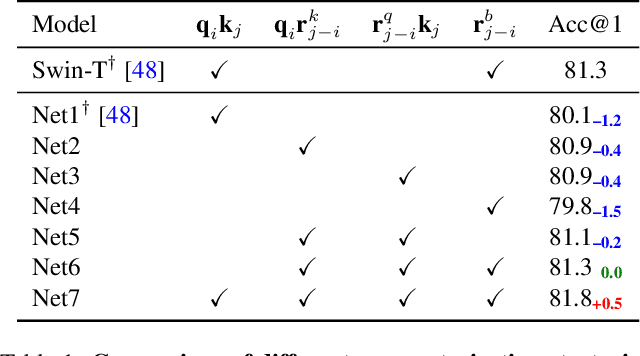
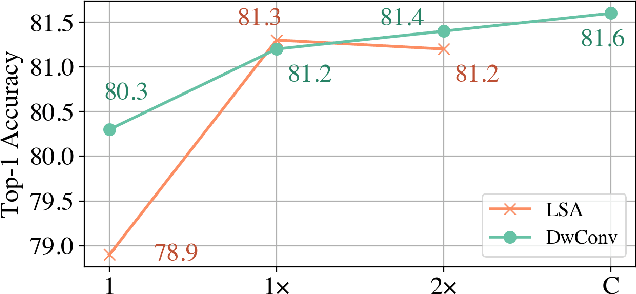

Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning. The performance of local self-attention (LSA) is just on par with convolution and inferior to dynamic filters, which puzzles researchers on whether to use LSA or its counterparts, which one is better, and what makes LSA mediocre. To clarify these, we comprehensively investigate LSA and its counterparts from two sides: \emph{channel setting} and \emph{spatial processing}. We find that the devil lies in the generation and application of spatial attention, where relative position embeddings and the neighboring filter application are key factors. Based on these findings, we propose the enhanced local self-attention (ELSA) with Hadamard attention and the ghost head. Hadamard attention introduces the Hadamard product to efficiently generate attention in the neighboring case, while maintaining the high-order mapping. The ghost head combines attention maps with static matrices to increase channel capacity. Experiments demonstrate the effectiveness of ELSA. Without architecture / hyperparameter modification, drop-in replacing LSA with ELSA boosts Swin Transformer \cite{swin} by up to +1.4 on top-1 accuracy. ELSA also consistently benefits VOLO \cite{volo} from D1 to D5, where ELSA-VOLO-D5 achieves 87.2 on the ImageNet-1K without extra training images. In addition, we evaluate ELSA in downstream tasks. ELSA significantly improves the baseline by up to +1.9 box Ap / +1.3 mask Ap on the COCO, and by up to +1.9 mIoU on the ADE20K. Code is available at \url{https://github.com/damo-cv/ELSA}.