 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Hypothesis Semantic Mapping for Robust Data Association
Dec 08, 2020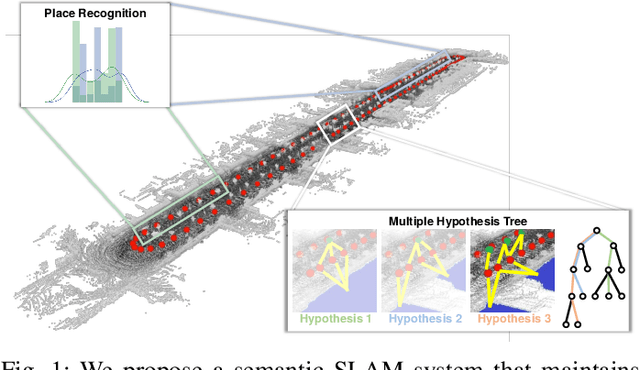
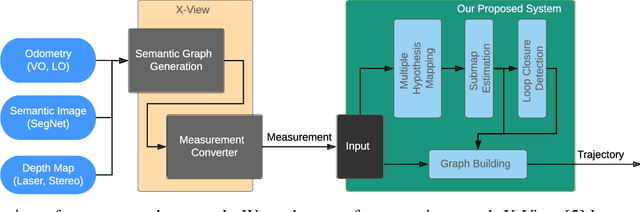
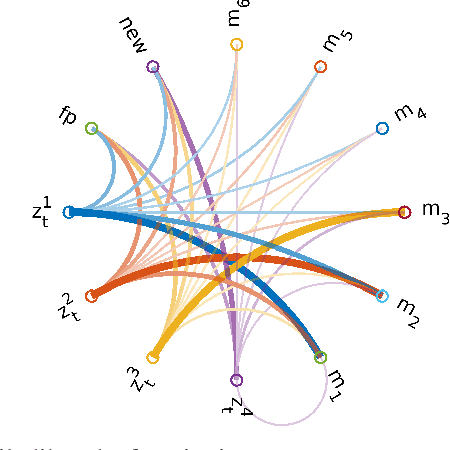
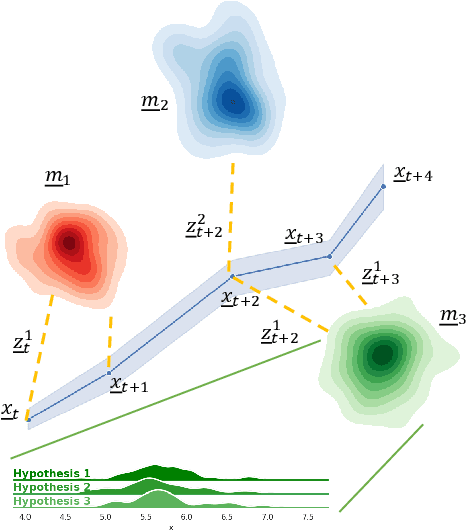
In this paper, we present a semantic mapping approach with multiple hypothesis tracking for data association. As semantic information has the potential to overcome ambiguity in measurements and place recognition, it forms an eminent modality for autonomous systems. This is particularly evident in urban scenarios with several similar looking surroundings. Nevertheless, it requires the handling of a non-Gaussian and discrete random variable coming from object detectors. Previous methods facilitate semantic information for global localization and data association to reduce the instance ambiguity between the landmarks. However, many of these approaches do not deal with the creation of complete globally consistent representations of the environment and typically do not scale well. We utilize multiple hypothesis trees to derive a probabilistic data association for semantic measurements by means of position, instance and class to create a semantic representation. We propose an optimized mapping method and make use of a pose graph to derive a novel semantic SLAM solution. Furthermore, we show that semantic covisibility graphs allow for a precise place recognition in urban environments. We verify our approach using real-world outdoor dataset and demonstrate an average drift reduction of 33 % w.r.t. the raw odometry source. Moreover, our approach produces 55 % less hypotheses on average than a regular multiple hypotheses approach.
NavRep: Unsupervised Representations for Reinforcement Learning of Robot Navigation in Dynamic Human Environments
Dec 08, 2020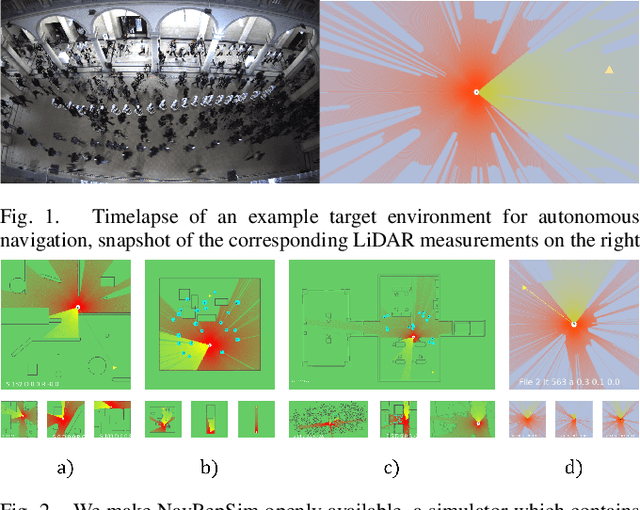
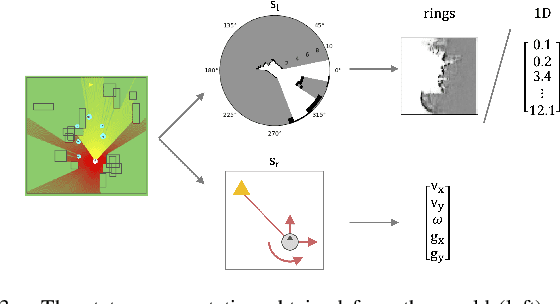
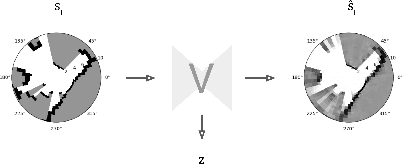
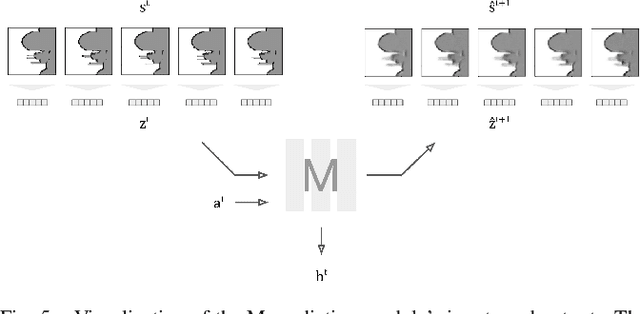
Robot navigation is a task where reinforcement learning approaches are still unable to compete with traditional path planning. State-of-the-art methods differ in small ways, and do not all provide reproducible, openly available implementations. This makes comparing methods a challenge. Recent research has shown that unsupervised learning methods can scale impressively, and be leveraged to solve difficult problems. In this work, we design ways in which unsupervised learning can be used to assist reinforcement learning for robot navigation. We train two end-to-end, and 18 unsupervised-learning-based architectures, and compare them, along with existing approaches, in unseen test cases. We demonstrate our approach working on a real life robot. Our results show that unsupervised learning methods are competitive with end-to-end methods. We also highlight the importance of various components such as input representation, predictive unsupervised learning, and latent features. We make all our models publicly available, as well as training and testing environments, and tools. This release also includes OpenAI-gym-compatible environments designed to emulate the training conditions described by other papers, with as much fidelity as possible. Our hope is that this helps in bringing together the field of RL for robot navigation, and allows meaningful comparisons across state-of-the-art methods.
Quantifying Aleatoric and Epistemic Uncertainty Using Density Estimation in Latent Space
Dec 05, 2020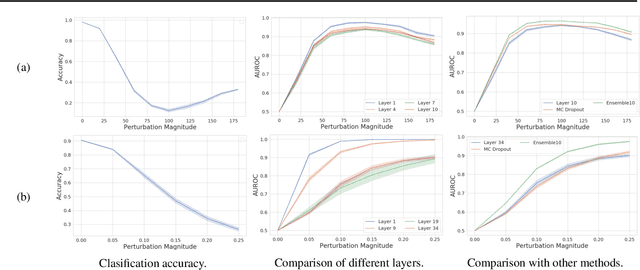
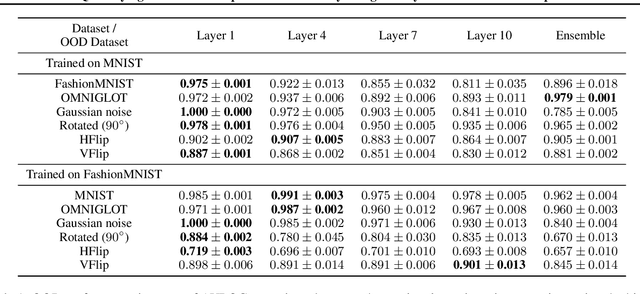

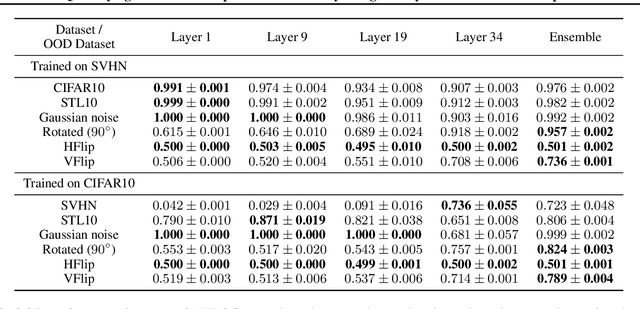
The distribution of a neural network's latent representations has been successfully used to detect Out-of-Distribution (OOD) data. Since OOD detection denotes a popular benchmark for epistemic uncertainty estimates, this raises the question of a deeper correlation. This work investigates whether the distribution of latent representations indeed contains information about the uncertainty associated with the predictions of a neural network. Prior work identifies epistemic uncertainty with the surprise, thus the negative log-likelihood, of observing a particular latent representation, which we verify empirically. Moreover, we demonstrate that the output-conditional distribution of hidden representations allows quantifying aleatoric uncertainty via the entropy of the predictive distribution. We analyze epistemic and aleatoric uncertainty inferred from the representations of different layers and conclude with the exciting finding that the hidden repesentations of a deterministic neural network indeed contain information about its uncertainty. We verify our findings on both classification and regression models.
3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer
Nov 30, 2020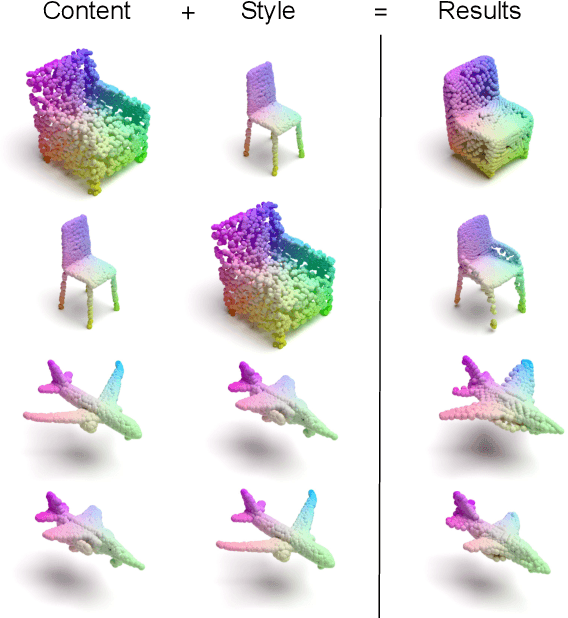
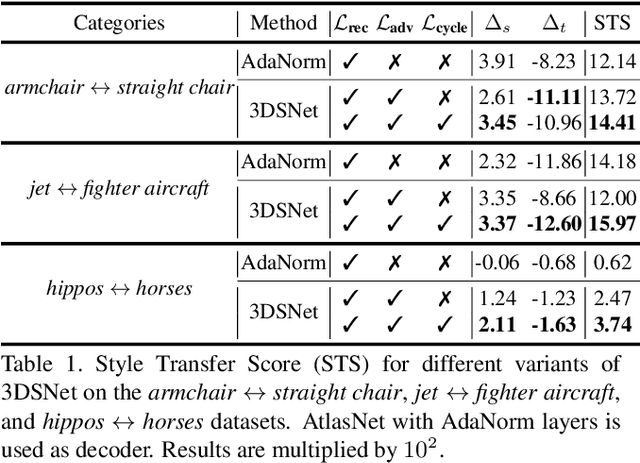
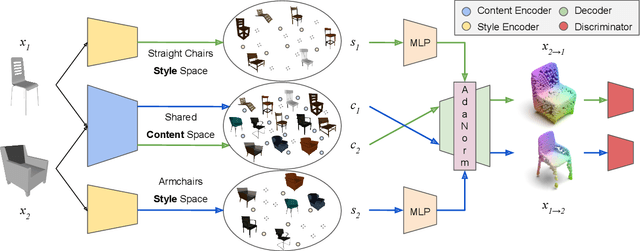

Transferring the style from one image onto another is a popular and widely studied task in computer vision. Yet, learning-based style transfer in the 3D setting remains a largely unexplored problem. To our knowledge, we propose the first learning-based generative approach for style transfer between 3D objects. Our method allows to combine the content and style of a source and target 3D model to generate a novel shape that resembles in style the target while retaining the source content. The proposed framework can synthesize new 3D shapes both in the form of point clouds and meshes. Furthermore, we extend our technique to implicitly learn the underlying multimodal style distribution of the individual category domains. By sampling style codes from the learned distributions, we increase the variety of styles that our model can confer to a given reference object. Experimental results validate the effectiveness of the proposed 3D style transfer method on a number of benchmarks.
Model Predictive Control for Micro Aerial Vehicles: A Survey
Nov 22, 2020
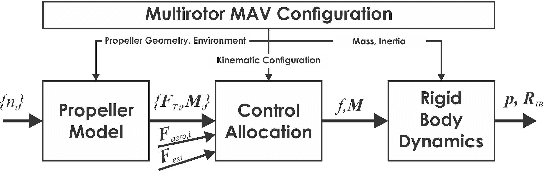
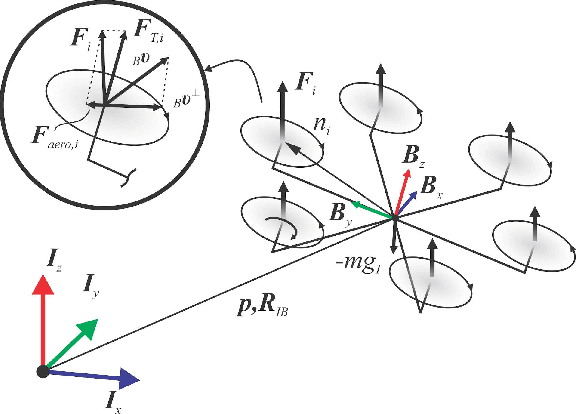
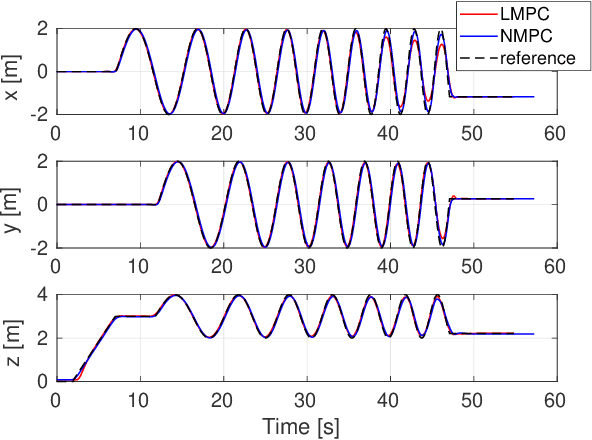
This paper presents a review of the design and application of model predictive control strategies for Micro Aerial Vehicles and specifically multirotor configurations such as quadrotors. The diverse set of works in the domain is organized based on the control law being optimized over linear or nonlinear dynamics, the integration of state and input constraints, possible fault-tolerant design, if reinforcement learning methods have been utilized and if the controller refers to free-flight or other tasks such as physical interaction or load transportation. A selected set of comparison results are also presented and serve to provide insight for the selection between linear and nonlinear schemes, the tuning of the prediction horizon, the importance of disturbance observer-based offset-free tracking and the intrinsic robustness of such methods to parameter uncertainty. Furthermore, an overview of recent research trends on the combined application of modern deep reinforcement learning techniques and model predictive control for multirotor vehicles is presented. Finally, this review concludes with explicit discussion regarding selected open-source software packages that deliver off-the-shelf model predictive control functionality applicable to a wide variety of Micro Aerial Vehicle configurations.
Learning Trajectories for Visual-Inertial System Calibration via Model-based Heuristic Deep Reinforcement Learning
Nov 04, 2020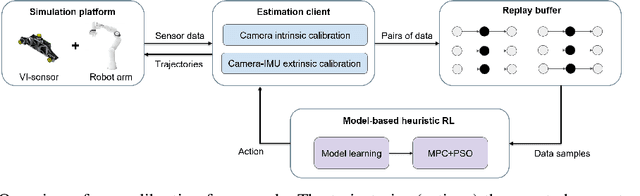
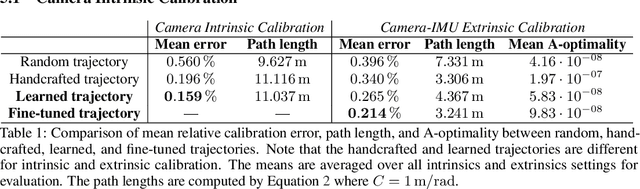
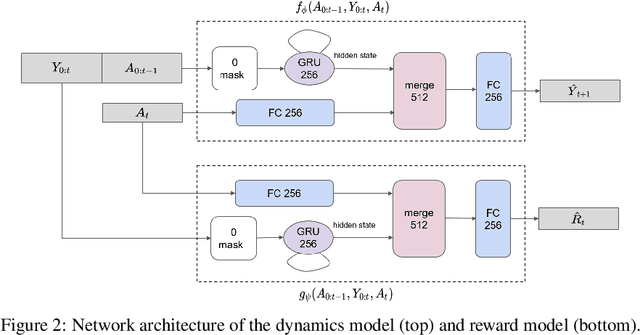
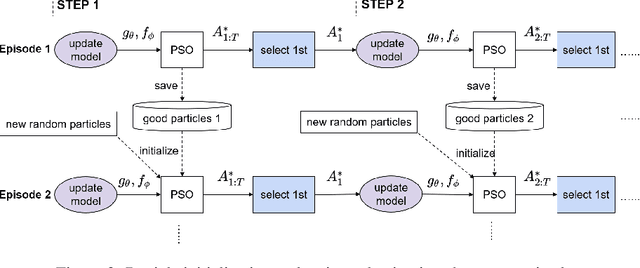
Visual-inertial systems rely on precise calibrations of both camera intrinsics and inter-sensor extrinsics, which typically require manually performing complex motions in front of a calibration target. In this work we present a novel approach to obtain favorable trajectories for visual-inertial system calibration, using model-based deep reinforcement learning. Our key contribution is to model the calibration process as a Markov decision process and then use model-based deep reinforcement learning with particle swarm optimization to establish a sequence of calibration trajectories to be performed by a robot arm. Our experiments show that while maintaining similar or shorter path lengths, the trajectories generated by our learned policy result in lower calibration errors compared to random or handcrafted trajectories.
Out-of-Distribution Detection for Automotive Perception
Nov 03, 2020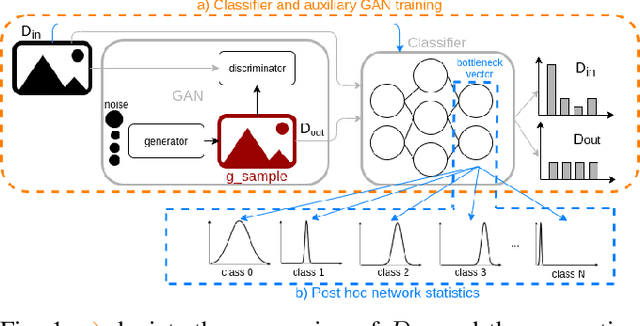
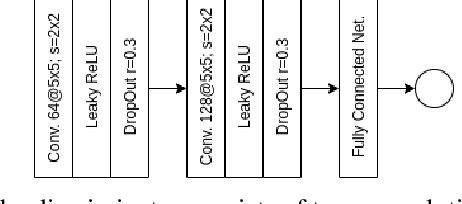
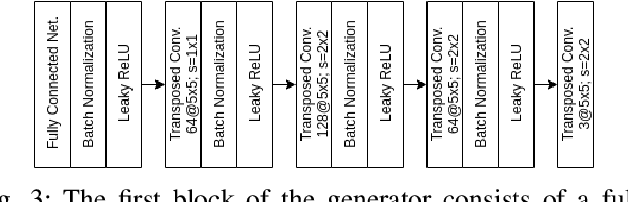
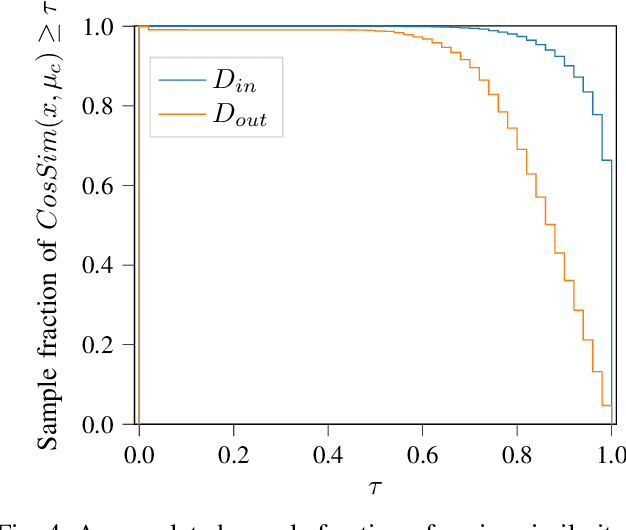
Neural networks (NNs) are widely used for object recognition tasks in autonomous driving. However, NNs can fail on input data not well represented by the training dataset, known as out-of-distribution (OOD) data. A mechanism to detect OOD samples is important in safety-critical applications, such as automotive perception, in order to trigger a safe fallback mode. NNs often rely on softmax normalization for confidence estimation, which can lead to high confidences being assigned to OOD samples, thus hindering the detection of failures. This paper presents a simple but effective method for determining whether inputs are OOD. We propose an OOD detection approach that combines auxiliary training techniques with post hoc statistics. Unlike other approaches, our proposed method does not require OOD data during training, and it does not increase the computational cost during inference. The latter property is especially important in automotive applications with limited computational resources and real-time constraints. Our proposed method outperforms state-of-the-art methods on real world automotive datasets.
LCD -- Line Clustering and Description for Place Recognition
Oct 21, 2020
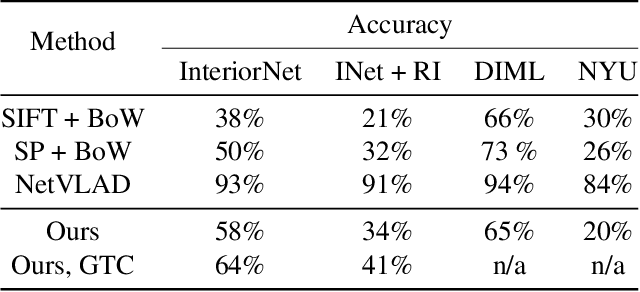
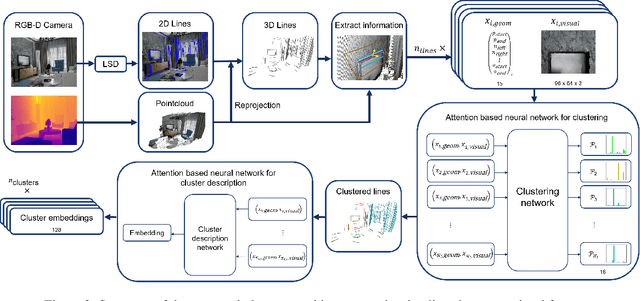
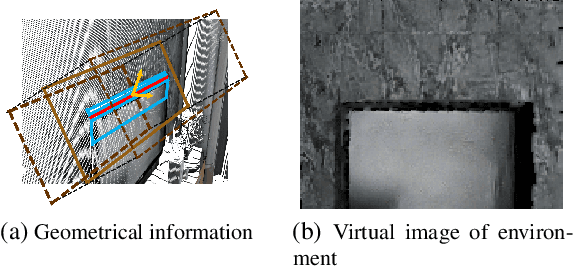
Current research on visual place recognition mostly focuses on aggregating local visual features of an image into a single vector representation. Therefore, high-level information such as the geometric arrangement of the features is typically lost. In this paper, we introduce a novel learning-based approach to place recognition, using RGB-D cameras and line clusters as visual and geometric features. We state the place recognition problem as a problem of recognizing clusters of lines instead of individual patches, thus maintaining structural information. In our work, line clusters are defined as lines that make up individual objects, hence our place recognition approach can be understood as object recognition. 3D line segments are detected in RGB-D images using state-of-the-art techniques. We present a neural network architecture based on the attention mechanism for frame-wise line clustering. A similar neural network is used for the description of these clusters with a compact embedding of 128 floating point numbers, trained with triplet loss on training data obtained from the InteriorNet dataset. We show experiments on a large number of indoor scenes and compare our method with the bag-of-words image-retrieval approach using SIFT and SuperPoint features and the global descriptor NetVLAD. Trained only on synthetic data, our approach generalizes well to real-world data captured with Kinect sensors, while also providing information about the geometric arrangement of instances.
Freetures: Localization in Signed Distance Function Maps
Oct 21, 2020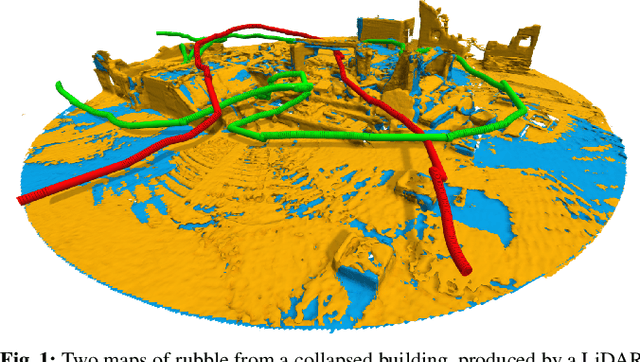
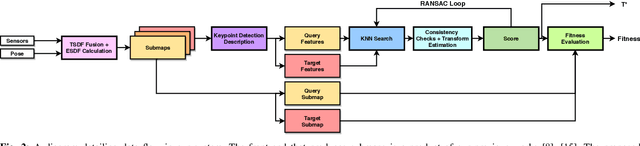


Localization of a robotic system within a previously mapped environment is important for reducing estimation drift and for reusing previously built maps. Existing techniques for geometry-based localization have focused on the description of local surface geometry, usually using pointclouds as the underlying representation. We propose a system for geometry-based localization that extracts features directly from an implicit surface representation: the Signed Distance Function (SDF). The SDF varies continuously through space, which allows the proposed system to extract and utilize features describing both surfaces and free-space. Through evaluations on public datasets, we demonstrate the flexibility of this approach, and show an increase in localization performance over state-of-the-art handcrafted surfaces-only descriptors. We achieve an average improvement of ~12% on an RGB-D dataset and ~18% on a LiDAR-based dataset. Finally, we demonstrate our system for localizing a LiDAR-equipped MAV within a previously built map of a search and rescue training ground.
Autonomous Extension of a Symbolic Mobile Manipulation Skill Set
Oct 20, 2020
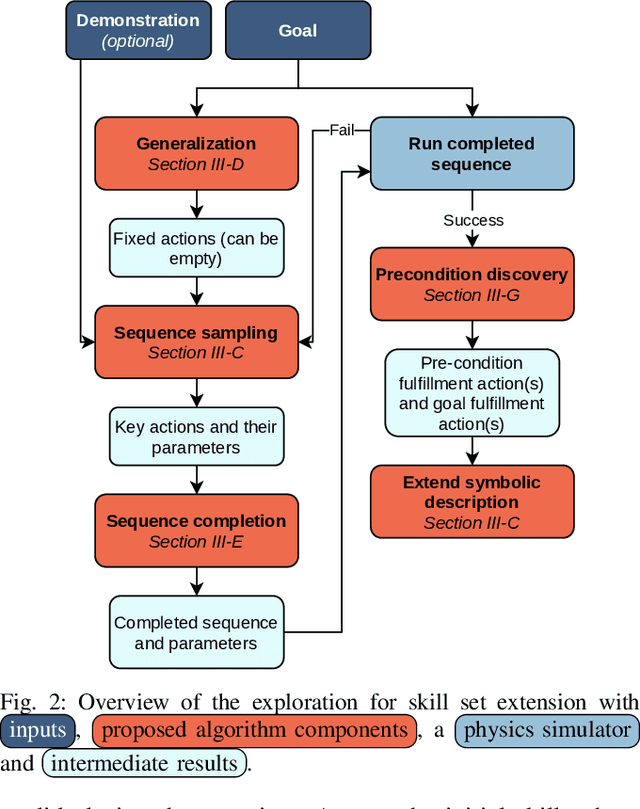
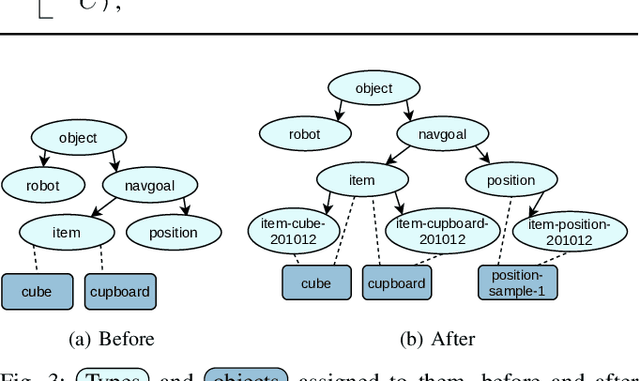

Today's methods of programming mobile manipulation systems' behavior for operating in unstructured environments do not generalize well to unseen tasks or changes in the environment not anticipated at design time. Although symbolic planning makes this task more accessible to non-expert users by allowing a user to specify a desired goal, it reaches its limits when a task or the current environment is not soundly represented by the abstract domain or problem description. We propose a method that allows an agent to autonomously extend its skill set and thus the abstract description upon encountering such a situation. For this, we combine a set of four basic skills (grasp, place, navigate, move) with an off-the-shelf symbolic planner upon which we base a skill sequence exploration scheme. To make the search over skill sequences more efficient and effective, we introduce strategies for generalizing from previous experience, completing sequences of key skills and discovering preconditions. The resulting system is evaluated in simulation using object rearrangement tasks. We can show qualitatively that the skill set extension works as expected and quantitatively that our strategies for more efficient search make the approach computationally tractable.