 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Mar 20, 2026Recent advances in reinforcement learning (RL) have enabled impressive humanoid behaviors in simulation, yet transferring these results to new robots remains challenging. In many real deployments, the primary bottleneck is no longer simulation throughput or algorithm design, but the absence of systematic infrastructure that links environment verification, training, evaluation, and deployment in a coherent loop. To address this gap, we present AGILE, an end-to-end workflow for humanoid RL that standardizes the policy-development lifecycle to mitigate common sim-to-real failure modes. AGILE comprises four stages: (1) interactive environment verification, (2) reproducible training, (3) unified evaluation, and (4) descriptor-driven deployment via robot/task configuration descriptors. For evaluation stage, AGILE supports both scenario-based tests and randomized rollouts under a shared suite of motion-quality diagnostics, enabling automated regression testing and principled robustness assessment. AGILE also incorporates a set of training stabilizations and algorithmic enhancements in training stage to improve optimization stability and sim-to-real transfer. With this pipeline in place, we validate AGILE across five representative humanoid skills spanning locomotion, recovery, motion imitation, and loco-manipulation on two hardware platforms (Unitree G1 and Booster T1), achieving consistent sim-to-real transfer. Overall, AGILE shows that a standardized, end-to-end workflow can substantially improve the reliability and reproducibility of humanoid RL development.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Ascento: A Two-Wheeled Jumping Robot
May 23, 2020
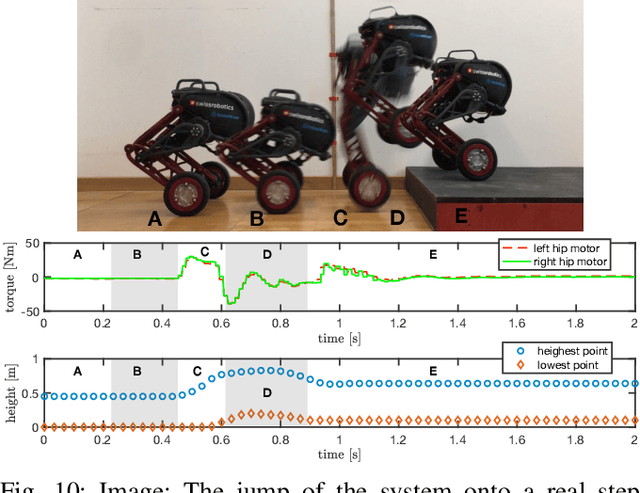
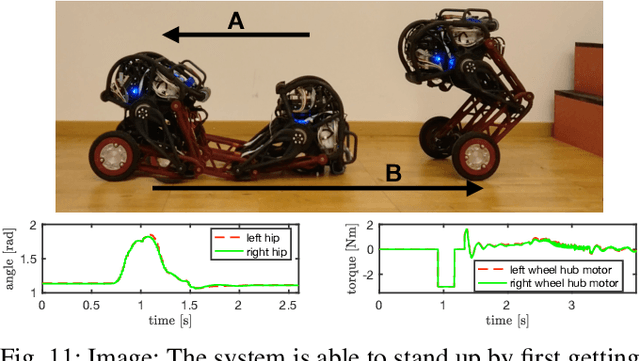
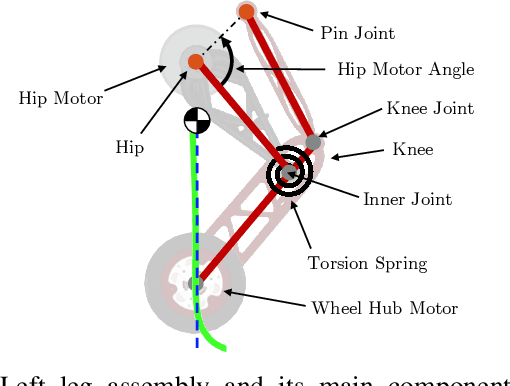
Applications of mobile ground robots demand high speed and agility while navigating in complex indoor environments. These present an ongoing challenge in mobile robotics. A system with these specifications would be of great use for a wide range of indoor inspection tasks. This paper introduces Ascento, a compact wheeled bipedal robot that is able to move quickly on flat terrain, and to overcome obstacles by jumping. The mechanical design and overall architecture of the system is presented, as well as the development of various controllers for different scenarios. A series of experiments with the final prototype system validate these behaviors in realistic scenarios.
* 7 pages, 11 Figures, ICRA 2019
LQR-Assisted Whole-Body Control of a Wheeled Bipedal Robot with Kinematic Loops
May 23, 2020
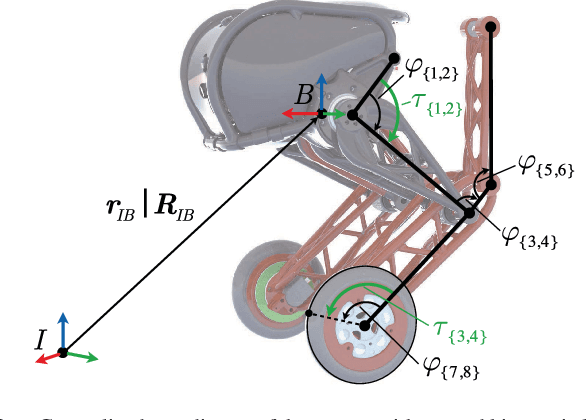
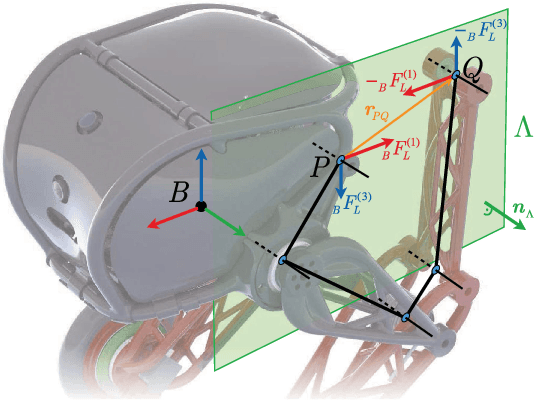
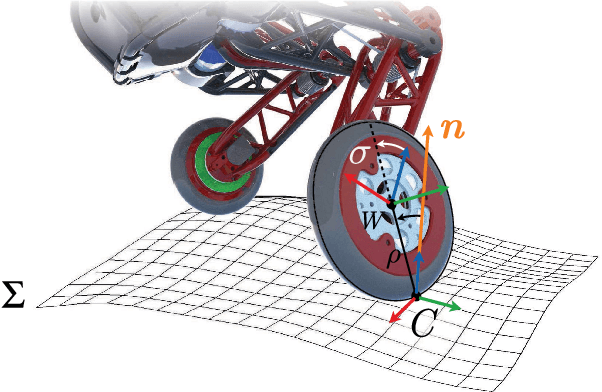
We present a hierarchical whole-body controller leveraging the full rigid body dynamics of the wheeled bipedal robot Ascento. We derive closed-form expressions for the dynamics of its kinematic loops in a way that readily generalizes to more complex systems. The rolling constraint is incorporated using a compact analytic solution based on rotation matrices. The non-minimum phase balancing dynamics are accounted for by including a linear-quadratic regulator as a motion task. Robustness when driving curves is increased by regulating the lean angle as a function of the zero-moment point. The proposed controller is computationally lightweight and significantly extends the rough-terrain capabilities and robustness of the system, as we demonstrate in several experiments.
* 8 pages, 10 figures, RA-L/ICRA 2020