 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022



We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
Modular Hybrid Autoregressive Transducer
Oct 31, 2022



Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
JOIST: A Joint Speech and Text Streaming Model For ASR
Oct 13, 2022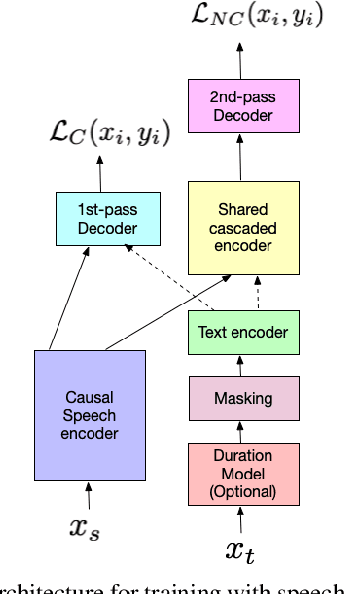
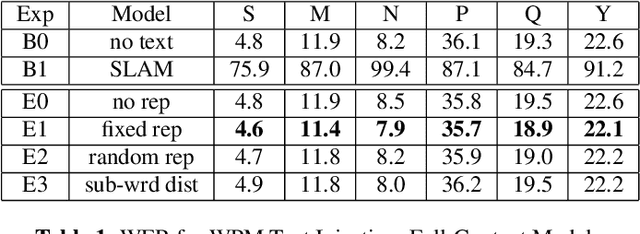
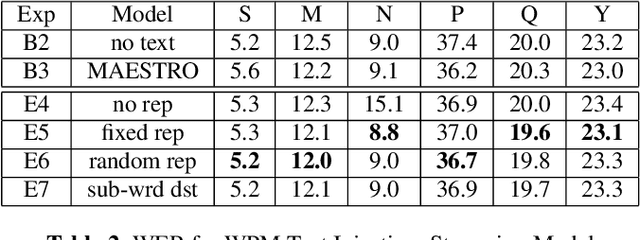
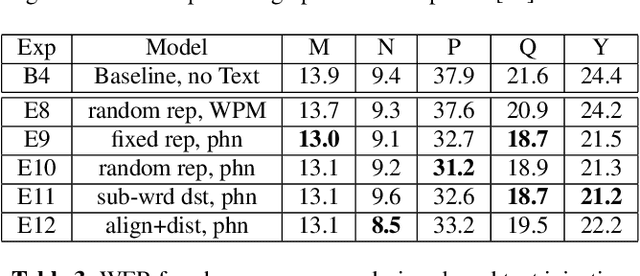
We present JOIST, an algorithm to train a streaming, cascaded, encoder end-to-end (E2E) model with both speech-text paired inputs, and text-only unpaired inputs. Unlike previous works, we explore joint training with both modalities, rather than pre-training and fine-tuning. In addition, we explore JOIST using a streaming E2E model with an order of magnitude more data, which are also novelties compared to previous works. Through a series of ablation studies, we explore different types of text modeling, including how to model the length of the text sequence and the appropriate text sub-word unit representation. We find that best text representation for JOIST improves WER across a variety of search and rare-word test sets by 4-14% relative, compared to a model not trained with text. In addition, we quantitatively show that JOIST maintains streaming capabilities, which is important for good user-level experience.
Improving Deliberation by Text-Only and Semi-Supervised Training
Jun 29, 2022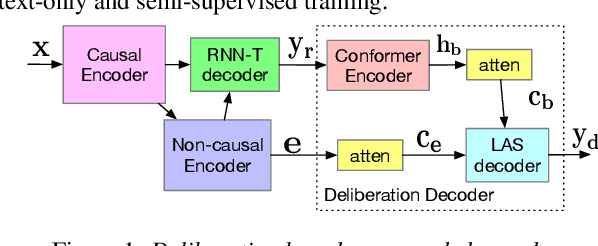
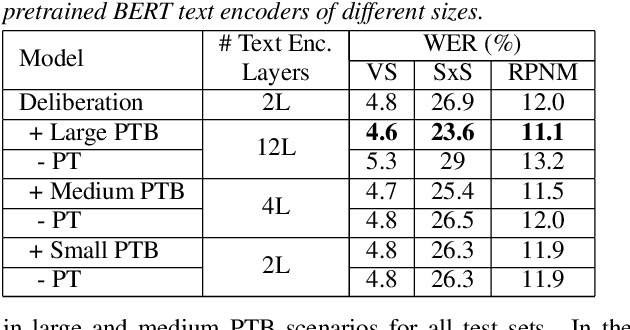
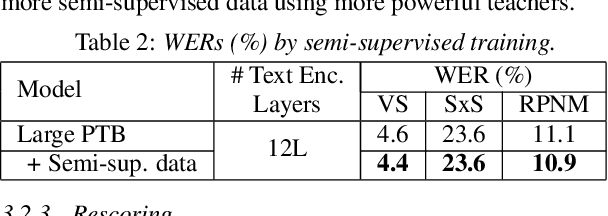
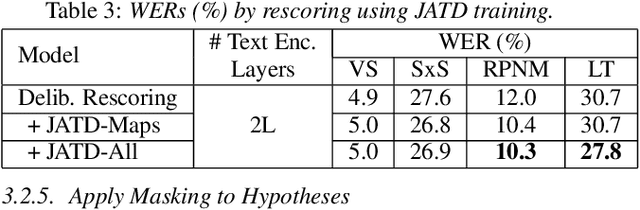
Text-only and semi-supervised training based on audio-only data has gained popularity recently due to the wide availability of unlabeled text and speech data. In this work, we propose incorporating text-only and semi-supervised training into an attention-based deliberation model. By incorporating text-only data in training a bidirectional encoder representation from transformer (BERT) for the deliberation text encoder, and large-scale text-to-speech and audio-only utterances using joint acoustic and text decoder (JATD) and semi-supervised training, we achieved 4%-12% WER reduction for various tasks compared to the baseline deliberation. Compared to a state-of-the-art language model (LM) rescoring method, the deliberation model reduces the Google Voice Search WER by 11% relative. We show that the deliberation model also achieves a positive human side-by-side evaluation compared to the state-of-the-art LM rescorer with reasonable endpointer latencies.
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022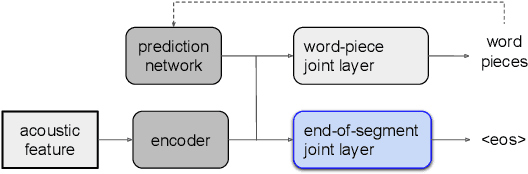
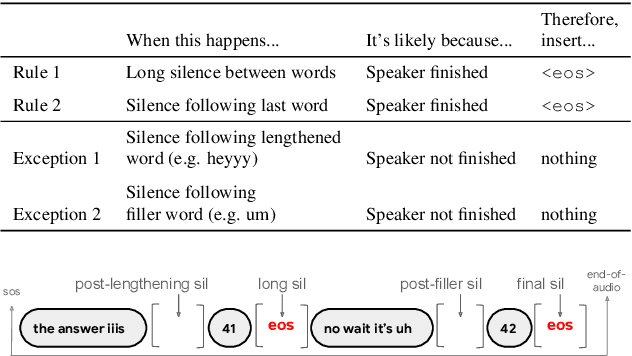
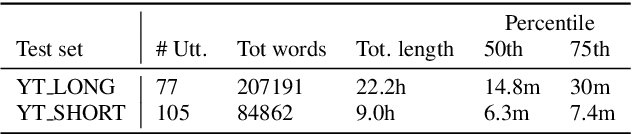
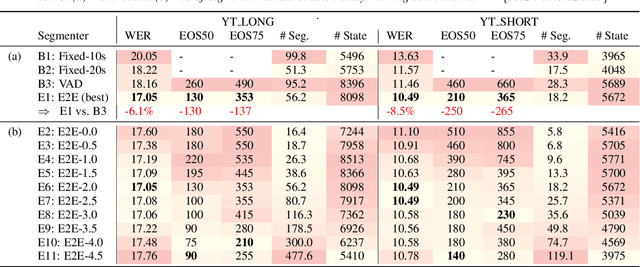
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022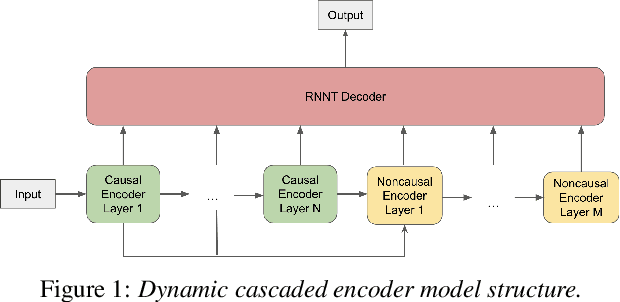
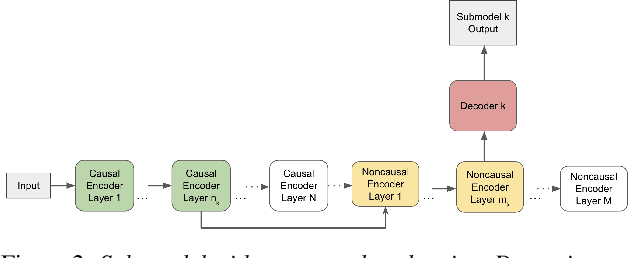
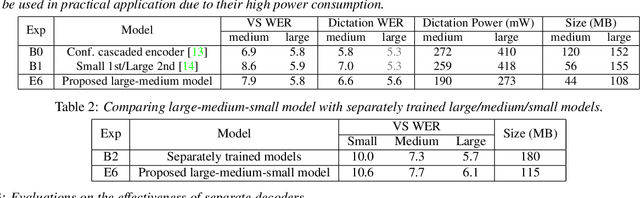
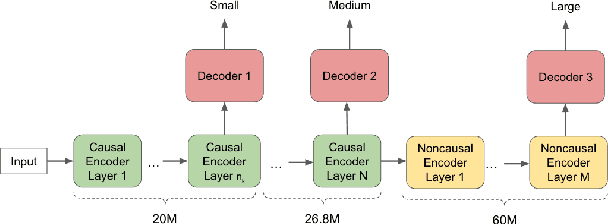
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Improving Rare Word Recognition with LM-aware MWER Training
Apr 15, 2022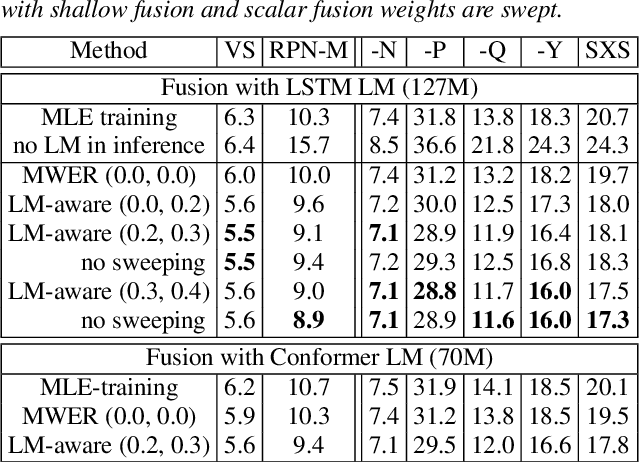
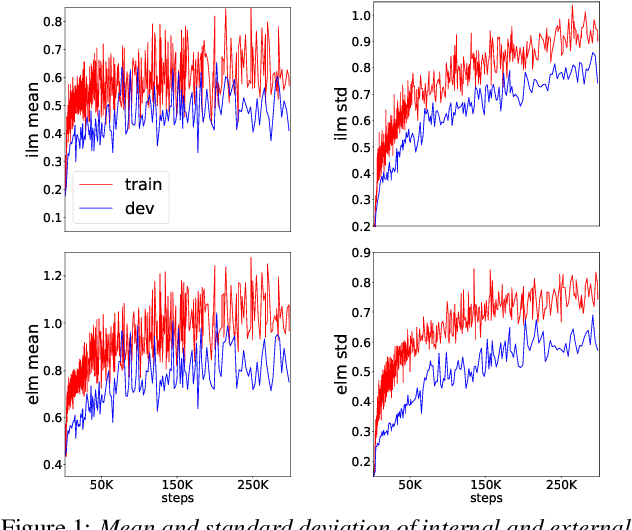

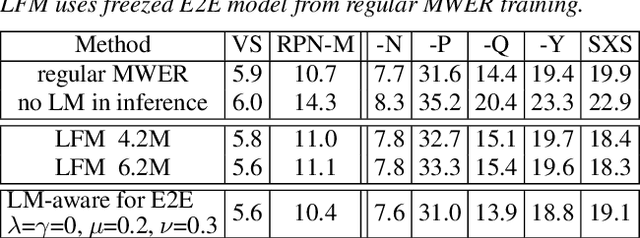
Language models (LMs) significantly improve the recognition accuracy of end-to-end (E2E) models on words rarely seen during training, when used in either the shallow fusion or the rescoring setups. In this work, we introduce LMs in the learning of hybrid autoregressive transducer (HAT) models in the discriminative training framework, to mitigate the training versus inference gap regarding the use of LMs. For the shallow fusion setup, we use LMs during both hypotheses generation and loss computation, and the LM-aware MWER-trained model achieves 10\% relative improvement over the model trained with standard MWER on voice search test sets containing rare words. For the rescoring setup, we learn a small neural module to generate per-token fusion weights in a data-dependent manner. This model achieves the same rescoring WER as regular MWER-trained model, but without the need for sweeping fusion weights.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022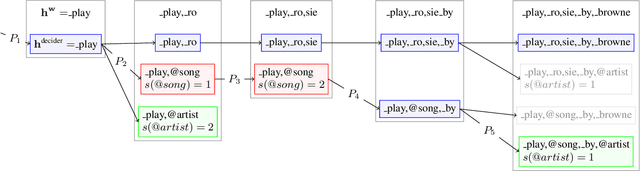
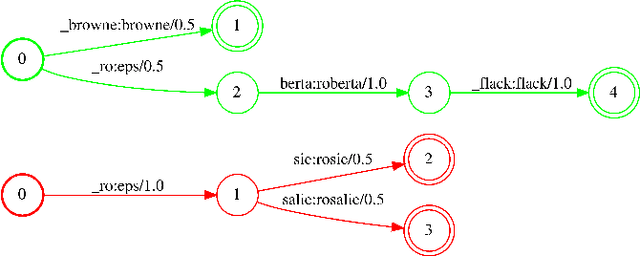
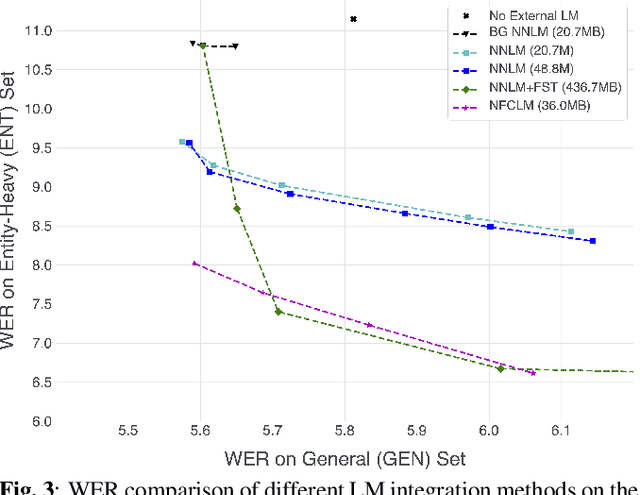
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
Input Length Matters: An Empirical Study Of RNN-T And MWER Training For Long-form Telephony Speech Recognition
Oct 08, 2021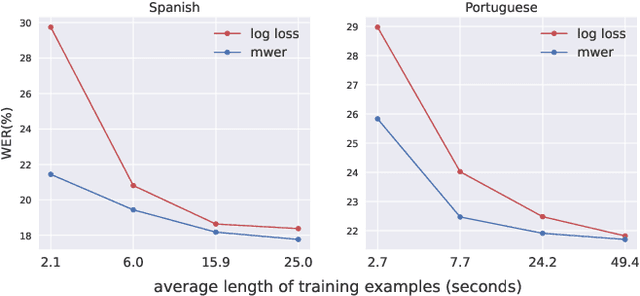
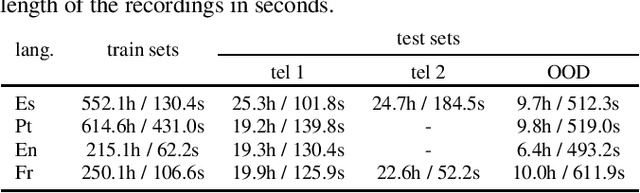


End-to-end models have achieved state-of-the-art results on several automatic speech recognition tasks. However, they perform poorly when evaluated on long-form data, e.g., minutes long conversational telephony audio. One reason the model fails on long-form speech is that it has only seen short utterances during training. This paper presents an empirical study on the effect of training utterance length on the word error rate (WER) for RNN-transducer (RNN-T) model. We compare two widely used training objectives, log loss (or RNN-T loss) and minimum word error rate (MWER) loss. We conduct experiments on telephony datasets in four languages. Our experiments show that for both losses, the WER on long-form speech reduces substantially as the training utterance length increases. The average relative WER gain is 15.7% for log loss and 8.8% for MWER loss. When training on short utterances, MWER loss leads to a lower WER than the log loss. Such difference between the two losses diminishes when the input length increases.
A Neural Acoustic Echo Canceller Optimized Using An Automatic Speech Recognizer And Large Scale Synthetic Data
Jun 01, 2021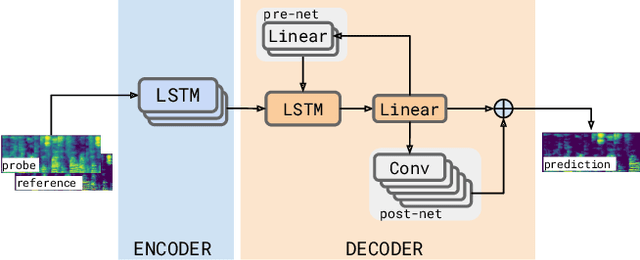
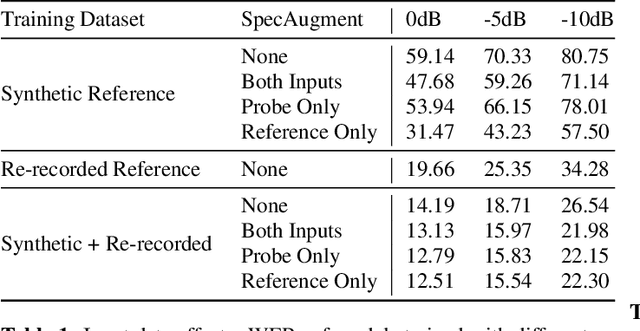
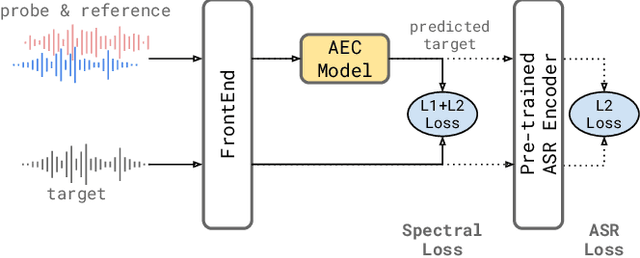
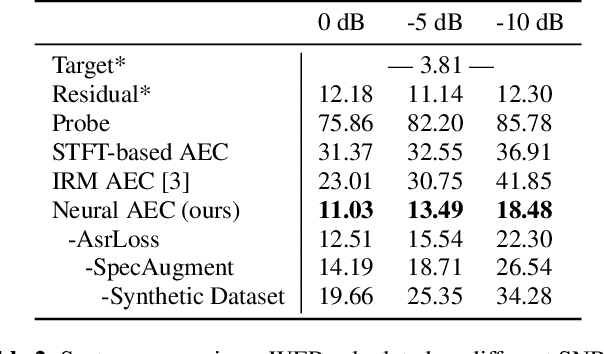
We consider the problem of recognizing speech utterances spoken to a device which is generating a known sound waveform; for example, recognizing queries issued to a digital assistant which is generating responses to previous user inputs. Previous work has proposed building acoustic echo cancellation (AEC) models for this task that optimize speech enhancement metrics using both neural network as well as signal processing approaches. Since our goal is to recognize the input speech, we consider enhancements which improve word error rates (WERs) when the predicted speech signal is passed to an automatic speech recognition (ASR) model. First, we augment the loss function with a term that produces outputs useful to a pre-trained ASR model and show that this augmented loss function improves WER metrics. Second, we demonstrate that augmenting our training dataset of real world examples with a large synthetic dataset improves performance. Crucially, applying SpecAugment style masks to the reference channel during training aids the model in adapting from synthetic to real domains. In experimental evaluations, we find the proposed approaches improve performance, on average, by 57% over a signal processing baseline and 45% over the neural AEC model without the proposed changes.