 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Jun 07, 2025Recent generations of language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established math and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from contamination and does not provide insights into the reasoning traces. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs think. Through extensive experiments, we show that LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having remaining token budget. By comparing LRMs with their standard LLM counterparts under same inference compute, we identify three performance regimes: (1) low-complexity tasks where standard models outperform LRMs, (2) medium-complexity tasks where LRMs demonstrates advantage, and (3) high-complexity tasks where both models face complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across scales. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models' computational behavior, shedding light on their strengths, limitations, and raising questions about their reasoning capabilities.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
SALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF
Nov 04, 2024



In Large Language Model (LLM) development, Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning models with human values and preferences. RLHF traditionally relies on the Kullback-Leibler (KL) divergence between the current policy and a frozen initial policy as a reference, which is added as a penalty in policy optimization algorithms like Proximal Policy Optimization (PPO). While this constraint prevents models from deviating too far from the initial checkpoint, it limits exploration of the reward landscape, reducing the model's ability to discover higher-quality solutions. As a result, policy optimization is often trapped in a narrow region of the parameter space, leading to suboptimal alignment and performance. This paper presents SALSA (Soup-based Alignment Learning for Stronger Adaptation), a novel approach designed to overcome these limitations by creating a more flexible and better located reference model through weight-space averaging of two independent supervised fine-tuned (SFT) models. This model soup allows for larger deviation in KL divergence and exploring a promising region of the solution space without sacrificing stability. By leveraging this more robust reference model, SALSA fosters better exploration, achieving higher rewards and improving model robustness, out-of-distribution generalization, and performance. We validate the effectiveness of SALSA through extensive experiments on popular open models (Llama2-7B, Mistral-7B, and Gemma-2B) across various benchmarks (MT-Bench, Arena-Hard, UltraFeedback), where it consistently surpasses PPO by fostering deeper exploration and achieving superior alignment in LLMs.
Computational Bottlenecks of Training Small-scale Large Language Models
Oct 25, 2024



While large language models (LLMs) dominate the AI landscape, Small-scale large Language Models (SLMs) are gaining attention due to cost and efficiency demands from consumers. However, there is limited research on the training behavior and computational requirements of SLMs. In this study, we explore the computational bottlenecks of training SLMs (up to 2B parameters) by examining the effects of various hyperparameters and configurations, including GPU type, batch size, model size, communication protocol, attention type, and the number of GPUs. We assess these factors on popular cloud services using metrics such as loss per dollar and tokens per second. Our findings aim to support the broader adoption and optimization of language model training for low-resource AI research institutes.
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Oct 07, 2024



Recent advancements in Large Language Models (LLMs) have sparked interest in their formal reasoning capabilities, particularly in mathematics. The GSM8K benchmark is widely used to assess the mathematical reasoning of models on grade-school-level questions. While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics. To address these concerns, we conduct a large-scale study on several SOTA open and closed models. To overcome the limitations of existing evaluations, we introduce GSM-Symbolic, an improved benchmark created from symbolic templates that allow for the generation of a diverse set of questions. GSM-Symbolic enables more controllable evaluations, providing key insights and more reliable metrics for measuring the reasoning capabilities of models.Our findings reveal that LLMs exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of all models declines when only the numerical values in the question are altered in the GSM-Symbolic benchmark. Furthermore, we investigate the fragility of mathematical reasoning in these models and show that their performance significantly deteriorates as the number of clauses in a question increases. We hypothesize that this decline is because current LLMs cannot perform genuine logical reasoning; they replicate reasoning steps from their training data. Adding a single clause that seems relevant to the question causes significant performance drops (up to 65%) across all state-of-the-art models, even though the clause doesn't contribute to the reasoning chain needed for the final answer. Overall, our work offers a more nuanced understanding of LLMs' capabilities and limitations in mathematical reasoning.
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Dec 12, 2023



Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, "windowing'" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
Oct 06, 2023Large Language Models (LLMs) with billions of parameters have drastically transformed AI applications. However, their demanding computation during inference has raised significant challenges for deployment on resource-constrained devices. Despite recent trends favoring alternative activation functions such as GELU or SiLU, known for increased computation, this study strongly advocates for reinstating ReLU activation in LLMs. We demonstrate that using the ReLU activation function has a negligible impact on convergence and performance while significantly reducing computation and weight transfer. This reduction is particularly valuable during the memory-bound inference step, where efficiency is paramount. Exploring sparsity patterns in ReLU-based LLMs, we unveil the reutilization of activated neurons for generating new tokens and leveraging these insights, we propose practical strategies to substantially reduce LLM inference computation up to three times, using ReLU activations with minimal performance trade-offs.
ActiLabel: A Combinatorial Transfer Learning Framework for Activity Recognition
Mar 16, 2020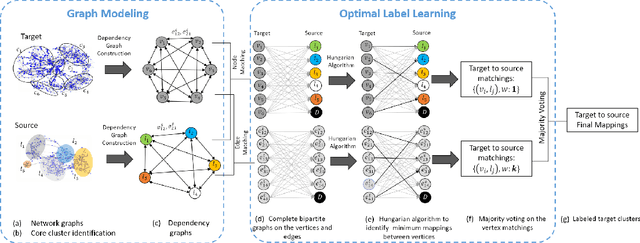
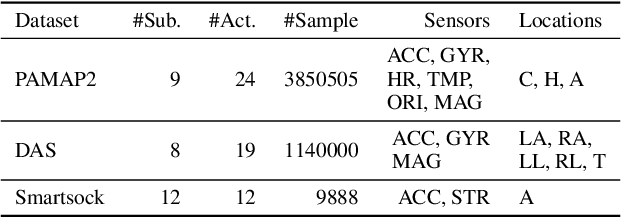
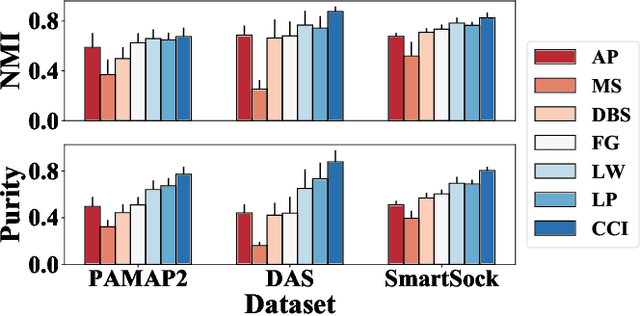
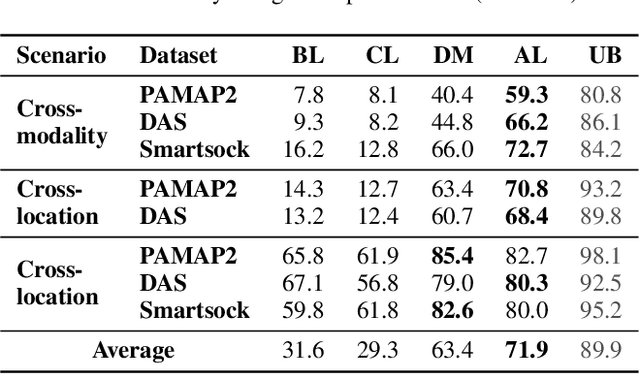
Sensor-based human activity recognition has become a critical component of many emerging applications ranging from behavioral medicine to gaming. However, an unprecedented increase in the diversity of sensor devices in the Internet-of-Things era has limited the adoption of activity recognition models for use across different domains. We propose ActiLabel a combinatorial framework that learns structural similarities among the events in an arbitrary domain and those of a different domain. The structural similarities are captured through a graph model, referred to as the it dependency graph, which abstracts details of activity patterns in low-level signal and feature space. The activity labels are then autonomously learned by finding an optimal tiered mapping between the dependency graphs. Extensive experiments based on three public datasets demonstrate the superiority of ActiLabel over state-of-the-art transfer learning and deep learning methods.