 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth4Seg -- Learning Defect Data Synthesis for Defect Segmentation using Bi-level Optimization
Oct 24, 2024Defect segmentation is crucial for quality control in advanced manufacturing, yet data scarcity poses challenges for state-of-the-art supervised deep learning. Synthetic defect data generation is a popular approach for mitigating data challenges. However, many current methods simply generate defects following a fixed set of rules, which may not directly relate to downstream task performance. This can lead to suboptimal performance and may even hinder the downstream task. To solve this problem, we leverage a novel bi-level optimization-based synthetic defect data generation framework. We use an online synthetic defect generation module grounded in the commonly-used Cut\&Paste framework, and adopt an efficient gradient-based optimization algorithm to solve the bi-level optimization problem. We achieve simultaneous training of the defect segmentation network, and learn various parameters of the data synthesis module by maximizing the validation performance of the trained defect segmentation network. Our experimental results on benchmark datasets under limited data settings show that the proposed bi-level optimization method can be used for learning the most effective locations for pasting synthetic defects thereby improving the segmentation performance by up to 18.3\% when compared to pasting defects at random locations. We also demonstrate up to 2.6\% performance gain by learning the importance weights for different augmentation-specific defect data sources when compared to giving equal importance to all the data sources.
TIS-DPO: Token-level Importance Sampling for Direct Preference Optimization With Estimated Weights
Oct 06, 2024



Direct Preference Optimization (DPO) has been widely adopted for preference alignment of Large Language Models (LLMs) due to its simplicity and effectiveness. However, DPO is derived as a bandit problem in which the whole response is treated as a single arm, ignoring the importance differences between tokens, which may affect optimization efficiency and make it difficult to achieve optimal results. In this work, we propose that the optimal data for DPO has equal expected rewards for each token in winning and losing responses, as there is no difference in token importance. However, since the optimal dataset is unavailable in practice, we propose using the original dataset for importance sampling to achieve unbiased optimization. Accordingly, we propose a token-level importance sampling DPO objective named TIS-DPO that assigns importance weights to each token based on its reward. Inspired by previous works, we estimate the token importance weights using the difference in prediction probabilities from a pair of contrastive LLMs. We explore three methods to construct these contrastive LLMs: (1) guiding the original LLM with contrastive prompts, (2) training two separate LLMs using winning and losing responses, and (3) performing forward and reverse DPO training with winning and losing responses. Experiments show that TIS-DPO significantly outperforms various baseline methods on harmlessness and helpfulness alignment and summarization tasks. We also visualize the estimated weights, demonstrating their ability to identify key token positions.
Direct Large Language Model Alignment Through Self-Rewarding Contrastive Prompt Distillation
Feb 19, 2024



Aligning large language models (LLMs) with human expectations without human-annotated preference data is an important problem. In this paper, we propose a method to evaluate the response preference by using the output probabilities of response pairs under contrastive prompt pairs, which could achieve better performance on LLaMA2-7B and LLaMA2-13B compared to RLAIF. Based on this, we propose an automatic alignment method, Direct Large Model Alignment (DLMA). First, we use contrastive prompt pairs to automatically generate preference data. Then, we continue to evaluate the generated preference data using contrastive prompt pairs and calculate a self-rewarding score. Finally, we use the DPO algorithm to effectively align LLMs by combining this self-rewarding score. In the experimental stage, our DLMA method could surpass the \texttt{RLHF} method without relying on human-annotated preference data.
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
Oct 11, 2023Web-crawled datasets are pivotal to the success of pre-training vision-language models, exemplified by CLIP. However, web-crawled AltTexts can be noisy and potentially irrelevant to images, thereby undermining the crucial image-text alignment. Existing methods for rewriting captions using large language models (LLMs) have shown promise on small, curated datasets like CC3M and CC12M. Nevertheless, their efficacy on massive web-captured captions is constrained by the inherent noise and randomness in such data. In this study, we address this limitation by focusing on two key aspects: data quality and data variety. Unlike recent LLM rewriting techniques, we emphasize exploiting visual concepts and their integration into the captions to improve data quality. For data variety, we propose a novel mixed training scheme that optimally leverages AltTexts alongside newly generated Visual-enriched Captions (VeC). We use CLIP as one example and adapt the method for CLIP training on large-scale web-crawled datasets, named VeCLIP. We conduct a comprehensive evaluation of VeCLIP across small, medium, and large scales of raw data. Our results show significant advantages in image-text alignment and overall model performance, underscoring the effectiveness of VeCLIP in improving CLIP training. For example, VeCLIP achieves a remarkable over 20% improvement in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, we also achieve a notable over 3% improvement while using only 14% of the data employed in the vanilla CLIP and 11% in ALIGN.
VISION Datasets: A Benchmark for Vision-based InduStrial InspectiON
Jun 18, 2023Despite progress in vision-based inspection algorithms, real-world industrial challenges -- specifically in data availability, quality, and complex production requirements -- often remain under-addressed. We introduce the VISION Datasets, a diverse collection of 14 industrial inspection datasets, uniquely poised to meet these challenges. Unlike previous datasets, VISION brings versatility to defect detection, offering annotation masks across all splits and catering to various detection methodologies. Our datasets also feature instance-segmentation annotation, enabling precise defect identification. With a total of 18k images encompassing 44 defect types, VISION strives to mirror a wide range of real-world production scenarios. By supporting two ongoing challenge competitions on the VISION Datasets, we hope to foster further advancements in vision-based industrial inspection.
RGI: robust GAN-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection
Feb 24, 2023



Generative adversarial networks (GANs), trained on a large-scale image dataset, can be a good approximator of the natural image manifold. GAN-inversion, using a pre-trained generator as a deep generative prior, is a promising tool for image restoration under corruptions. However, the performance of GAN-inversion can be limited by a lack of robustness to unknown gross corruptions, i.e., the restored image might easily deviate from the ground truth. In this paper, we propose a Robust GAN-inversion (RGI) method with a provable robustness guarantee to achieve image restoration under unknown \textit{gross} corruptions, where a small fraction of pixels are completely corrupted. Under mild assumptions, we show that the restored image and the identified corrupted region mask converge asymptotically to the ground truth. Moreover, we extend RGI to Relaxed-RGI (R-RGI) for generator fine-tuning to mitigate the gap between the GAN learned manifold and the true image manifold while avoiding trivial overfitting to the corrupted input image, which further improves the image restoration and corrupted region mask identification performance. The proposed RGI/R-RGI method unifies two important applications with state-of-the-art (SOTA) performance: (i) mask-free semantic inpainting, where the corruptions are unknown missing regions, the restored background can be used to restore the missing content; (ii) unsupervised pixel-wise anomaly detection, where the corruptions are unknown anomalous regions, the retrieved mask can be used as the anomalous region's segmentation mask.
PAEDID: Patch Autoencoder Based Deep Image Decomposition For Pixel-level Defective Region Segmentation
Apr 11, 2022
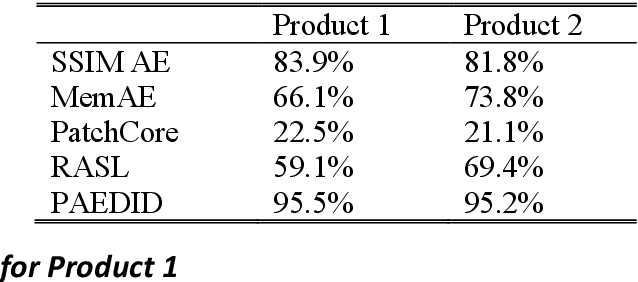

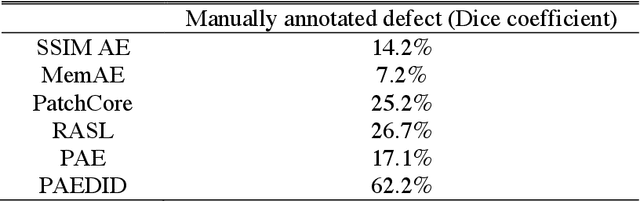
Unsupervised pixel-level defective region segmentation is an important task in image-based anomaly detection for various industrial applications. The state-of-the-art methods have their own advantages and limitations: matrix-decomposition-based methods are robust to noise but lack complex background image modeling capability; representation-based methods are good at defective region localization but lack accuracy in defective region shape contour extraction; reconstruction-based methods detected defective region match well with the ground truth defective region shape contour but are noisy. To combine the best of both worlds, we present an unsupervised patch autoencoder based deep image decomposition (PAEDID) method for defective region segmentation. In the training stage, we learn the common background as a deep image prior by a patch autoencoder (PAE) network. In the inference stage, we formulate anomaly detection as an image decomposition problem with the deep image prior and domain-specific regularizations. By adopting the proposed approach, the defective regions in the image can be accurately extracted in an unsupervised fashion. We demonstrate the effectiveness of the PAEDID method in simulation studies and an industrial dataset in the case study.
Self-supervised Semi-supervised Learning for Data Labeling and Quality Evaluation
Nov 22, 2021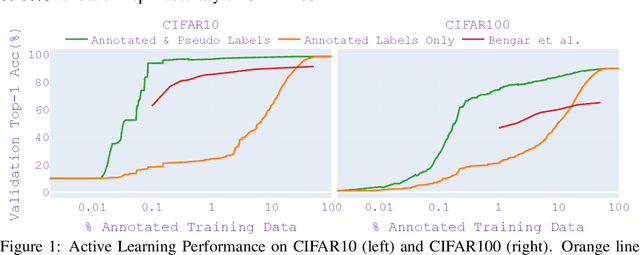
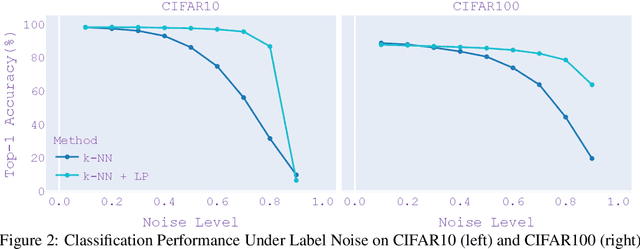
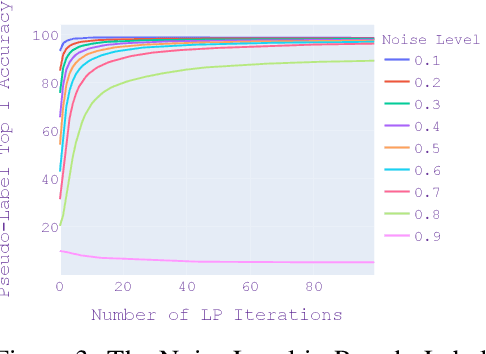
As the adoption of deep learning techniques in industrial applications grows with increasing speed and scale, successful deployment of deep learning models often hinges on the availability, volume, and quality of annotated data. In this paper, we tackle the problems of efficient data labeling and annotation verification under the human-in-the-loop setting. We showcase that the latest advancements in the field of self-supervised visual representation learning can lead to tools and methods that benefit the curation and engineering of natural image datasets, reducing annotation cost and increasing annotation quality. We propose a unifying framework by leveraging self-supervised semi-supervised learning and use it to construct workflows for data labeling and annotation verification tasks. We demonstrate the effectiveness of our workflows over existing methodologies. On active learning task, our method achieves 97.0% Top-1 Accuracy on CIFAR10 with 0.1% annotated data, and 83.9% Top-1 Accuracy on CIFAR100 with 10% annotated data. When learning with 50% of wrong labels, our method achieves 97.4% Top-1 Accuracy on CIFAR10 and 85.5% Top-1 Accuracy on CIFAR100.
BatchQuant: Quantized-for-all Architecture Search with Robust Quantizer
May 19, 2021
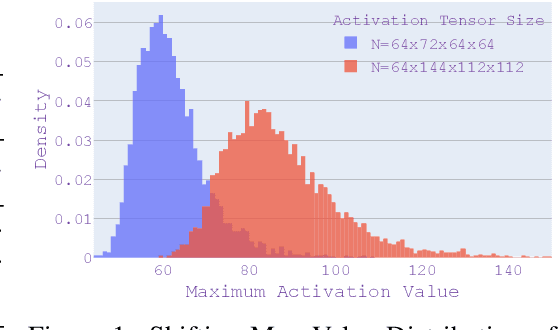
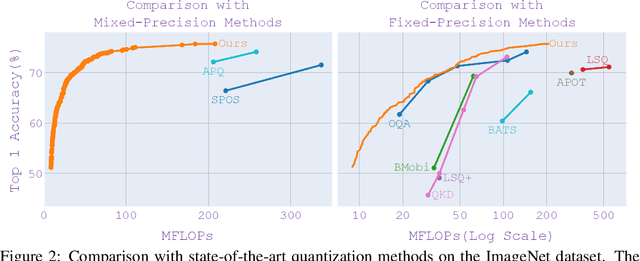
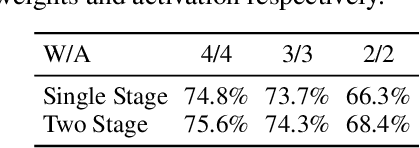
As the applications of deep learning models on edge devices increase at an accelerating pace, fast adaptation to various scenarios with varying resource constraints has become a crucial aspect of model deployment. As a result, model optimization strategies with adaptive configuration are becoming increasingly popular. While single-shot quantized neural architecture search enjoys flexibility in both model architecture and quantization policy, the combined search space comes with many challenges, including instability when training the weight-sharing supernet and difficulty in navigating the exponentially growing search space. Existing methods tend to either limit the architecture search space to a small set of options or limit the quantization policy search space to fixed precision policies. To this end, we propose BatchQuant, a robust quantizer formulation that allows fast and stable training of a compact, single-shot, mixed-precision, weight-sharing supernet. We employ BatchQuant to train a compact supernet (offering over $10^{76}$ quantized subnets) within substantially fewer GPU hours than previous methods. Our approach, Quantized-for-all (QFA), is the first to seamlessly extend one-shot weight-sharing NAS supernet to support subnets with arbitrary ultra-low bitwidth mixed-precision quantization policies without retraining. QFA opens up new possibilities in joint hardware-aware neural architecture search and quantization. We demonstrate the effectiveness of our method on ImageNet and achieve SOTA Top-1 accuracy under a low complexity constraint ($<20$ MFLOPs). The code and models will be made publicly available at https://github.com/bhpfelix/QFA.
MTL-NAS: Task-Agnostic Neural Architecture Search towards General-Purpose Multi-Task Learning
Mar 31, 2020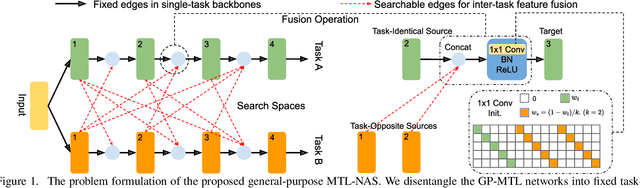
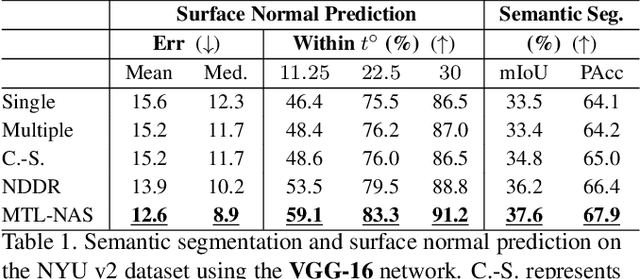
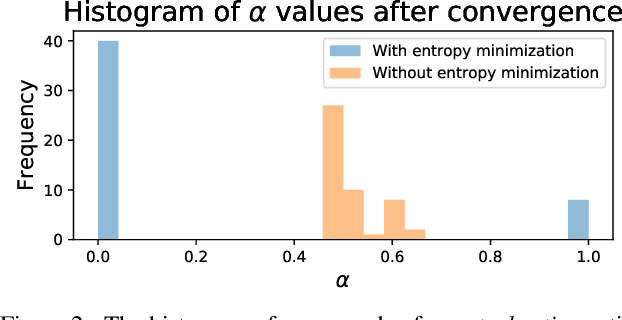
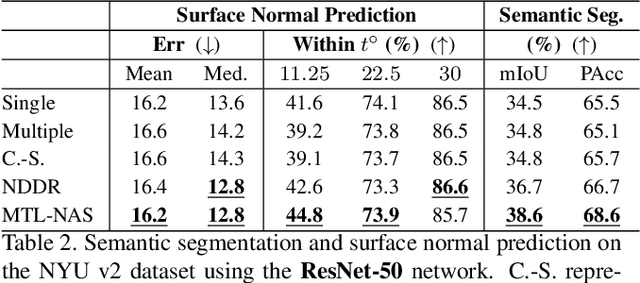
We propose to incorporate neural architecture search (NAS) into general-purpose multi-task learning (GP-MTL). Existing NAS methods typically define different search spaces according to different tasks. In order to adapt to different task combinations (i.e., task sets), we disentangle the GP-MTL networks into single-task backbones (optionally encode the task priors), and a hierarchical and layerwise features sharing/fusing scheme across them. This enables us to design a novel and general task-agnostic search space, which inserts cross-task edges (i.e., feature fusion connections) into fixed single-task network backbones. Moreover, we also propose a novel single-shot gradient-based search algorithm that closes the performance gap between the searched architectures and the final evaluation architecture. This is realized with a minimum entropy regularization on the architecture weights during the search phase, which makes the architecture weights converge to near-discrete values and therefore achieves a single model. As a result, our searched model can be directly used for evaluation without (re-)training from scratch. We perform extensive experiments using different single-task backbones on various task sets, demonstrating the promising performance obtained by exploiting the hierarchical and layerwise features, as well as the desirable generalizability to different i) task sets and ii) single-task backbones. The code of our paper is available at https://github.com/bhpfelix/MTLNAS.
* Accepted to CVPR2020. The first two authors contribute equally