 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCINS: Comprehensive Instruction for Few-shot Learning in Task-oriented Dialog Systems
Sep 14, 2021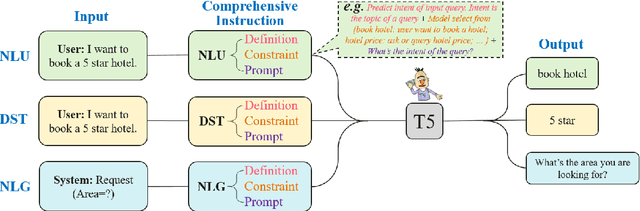
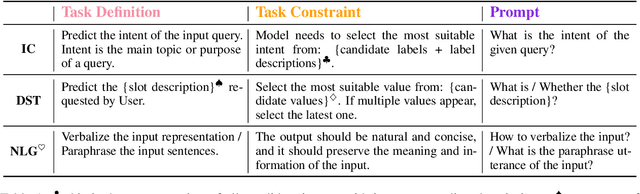
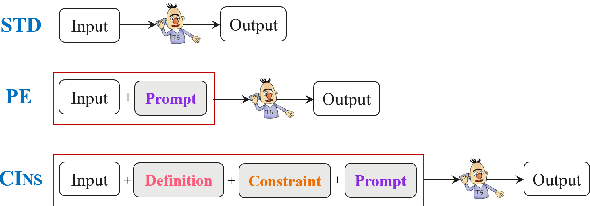
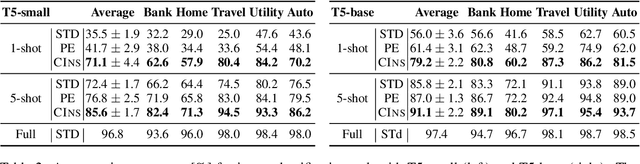
As labeling cost for different modules in task-oriented dialog (ToD) systems is high, a major challenge in practice is to learn different tasks with the least amount of labeled data. Recently, prompting methods over pre-trained language models (PLMs) have shown promising results for few-shot learning in ToD. To better utilize the power of PLMs, this paper proposes Comprehensive Instruction (CINS) that exploits PLMs with extra task-specific instructions. We design a schema (definition, constraint, prompt) of instructions and their customized realizations for three important downstream tasks in ToD, i.e. intent classification, dialog state tracking, and natural language generation. A sequence-to-sequence model (T5) is adopted to solve these three tasks in a unified framework. Extensive experiments are conducted on these ToD tasks in realistic few-shot learning scenarios with small validation data. Empirical results demonstrate that the proposed CINS approach consistently improves techniques that finetune PLMs with raw input or short prompts.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
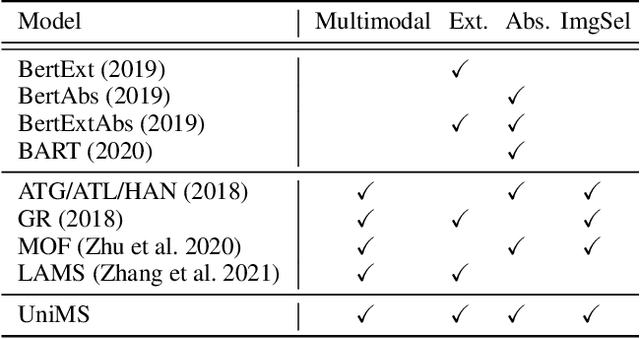
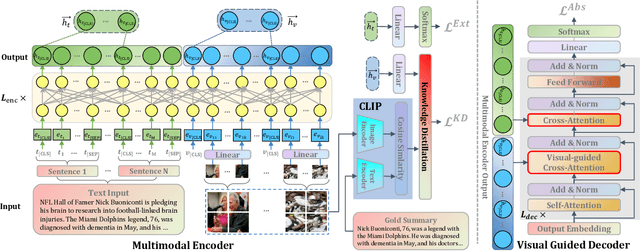
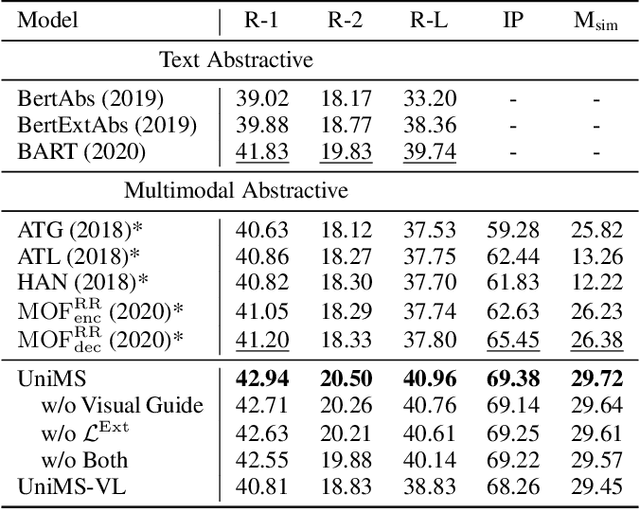
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.
KELM: Knowledge Enhanced Pre-Trained Language Representations with Message Passing on Hierarchical Relational Graphs
Sep 09, 2021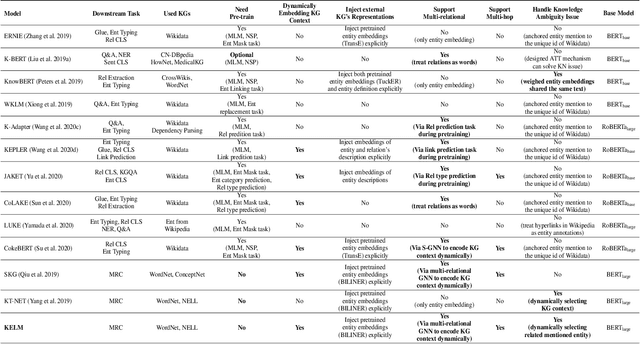
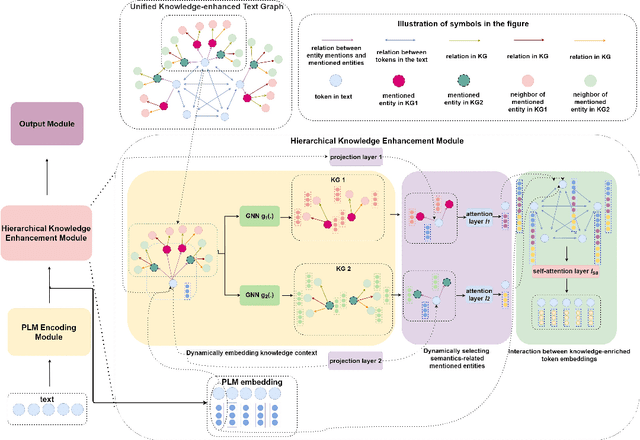
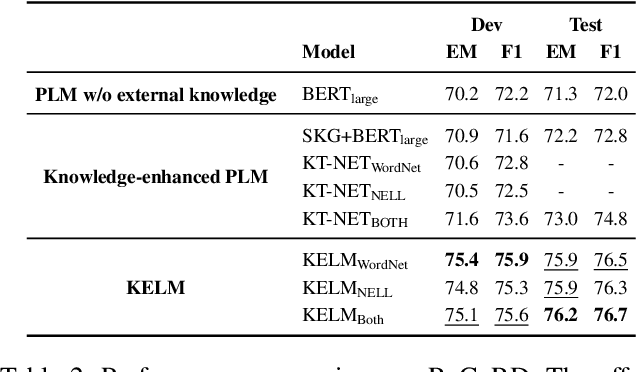
Incorporating factual knowledge into pre-trained language models (PLM) such as BERT is an emerging trend in recent NLP studies. However, most of the existing methods combine the external knowledge integration module with a modified pre-training loss and re-implement the pre-training process on the large-scale corpus. Re-pretraining these models is usually resource-consuming, and difficult to adapt to another domain with a different knowledge graph (KG). Besides, those works either cannot embed knowledge context dynamically according to textual context or struggle with the knowledge ambiguity issue. In this paper, we propose a novel knowledge-aware language model framework based on fine-tuning process, which equips PLM with a unified knowledge-enhanced text graph that contains both text and multi-relational sub-graphs extracted from KG. We design a hierarchical relational-graph-based message passing mechanism, which can allow the representations of injected KG and text to mutually update each other and can dynamically select ambiguous mentioned entities that share the same text. Our empirical results show that our model can efficiently incorporate world knowledge from KGs into existing language models such as BERT, and achieve significant improvement on the machine reading comprehension (MRC) task compared with other knowledge-enhanced models.
NumGPT: Improving Numeracy Ability of Generative Pre-trained Models
Sep 07, 2021
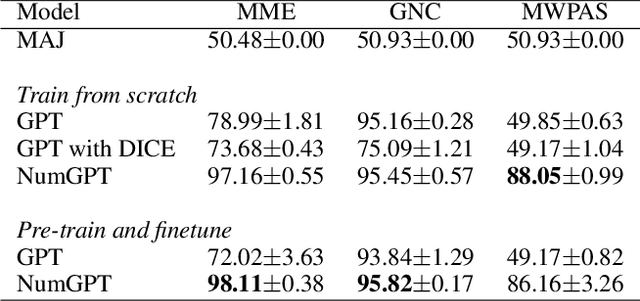
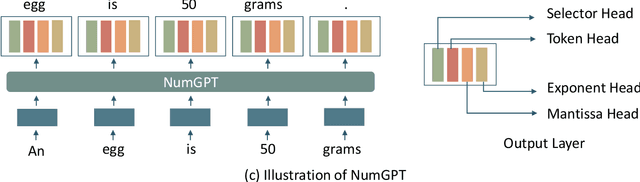
Existing generative pre-trained language models (e.g., GPT) focus on modeling the language structure and semantics of general texts. However, those models do not consider the numerical properties of numbers and cannot perform robustly on numerical reasoning tasks (e.g., math word problems and measurement estimation). In this paper, we propose NumGPT, a generative pre-trained model that explicitly models the numerical properties of numbers in texts. Specifically, it leverages a prototype-based numeral embedding to encode the mantissa of the number and an individual embedding to encode the exponent of the number. A numeral-aware loss function is designed to integrate numerals into the pre-training objective of NumGPT. We conduct extensive experiments on four different datasets to evaluate the numeracy ability of NumGPT. The experiment results show that NumGPT outperforms baseline models (e.g., GPT and GPT with DICE) on a range of numerical reasoning tasks such as measurement estimation, number comparison, math word problems, and magnitude classification. Ablation studies are also conducted to evaluate the impact of pre-training and model hyperparameters on the performance.
Generate & Rank: A Multi-task Framework for Math Word Problems
Sep 07, 2021
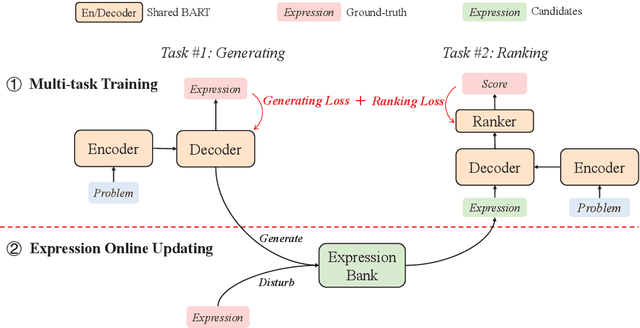
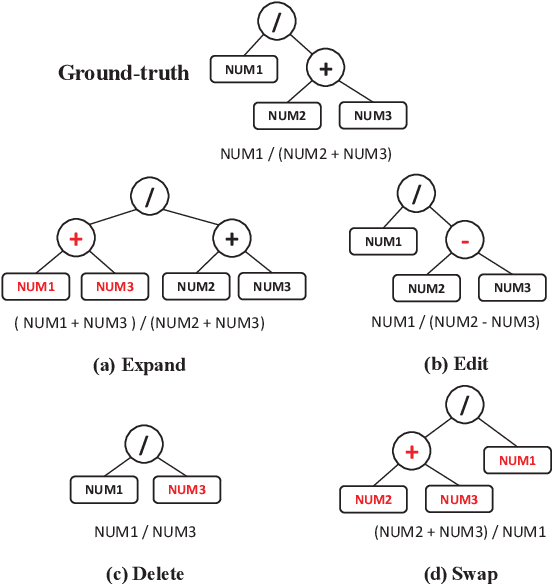
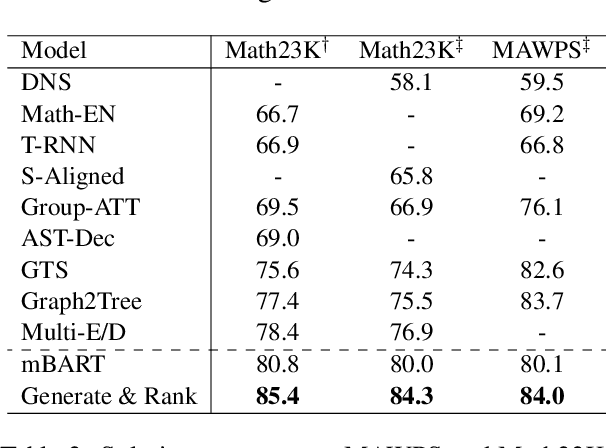
Math word problem (MWP) is a challenging and critical task in natural language processing. Many recent studies formalize MWP as a generation task and have adopted sequence-to-sequence models to transform problem descriptions to mathematical expressions. However, mathematical expressions are prone to minor mistakes while the generation objective does not explicitly handle such mistakes. To address this limitation, we devise a new ranking task for MWP and propose Generate & Rank, a multi-task framework based on a generative pre-trained language model. By joint training with generation and ranking, the model learns from its own mistakes and is able to distinguish between correct and incorrect expressions. Meanwhile, we perform tree-based disturbance specially designed for MWP and an online update to boost the ranker. We demonstrate the effectiveness of our proposed method on the benchmark and the results show that our method consistently outperforms baselines in all datasets. Particularly, in the classical Math23k, our method is 7% (78.4% $\rightarrow$ 85.4%) higher than the state-of-the-art.
Integrating Regular Expressions with Neural Networks via DFA
Sep 07, 2021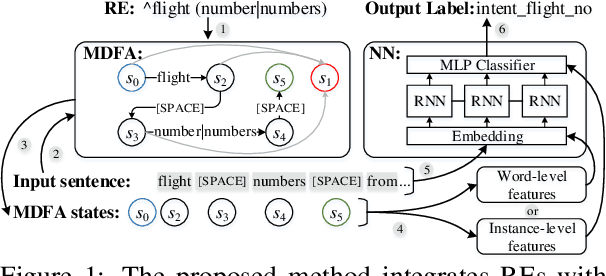
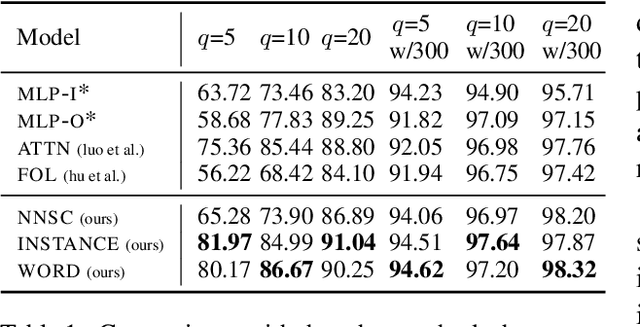
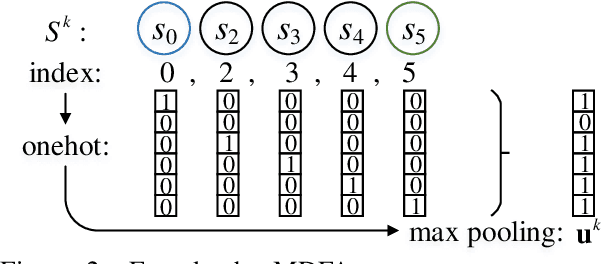
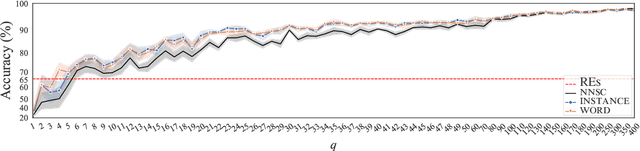
Human-designed rules are widely used to build industry applications. However, it is infeasible to maintain thousands of such hand-crafted rules. So it is very important to integrate the rule knowledge into neural networks to build a hybrid model that achieves better performance. Specifically, the human-designed rules are formulated as Regular Expressions (REs), from which the equivalent Minimal Deterministic Finite Automatons (MDFAs) are constructed. We propose to use the MDFA as an intermediate model to capture the matched RE patterns as rule-based features for each input sentence and introduce these additional features into neural networks. We evaluate the proposed method on the ATIS intent classification task. The experiment results show that the proposed method achieves the best performance compared to neural networks and four other methods that combine REs and neural networks when the training dataset is relatively small.
Uncertainty-Aware Balancing for Multilingual and Multi-Domain Neural Machine Translation Training
Sep 06, 2021
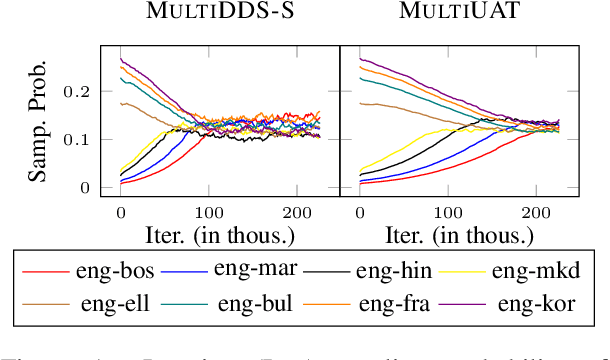
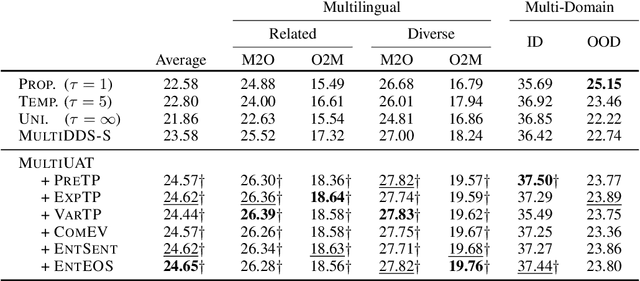
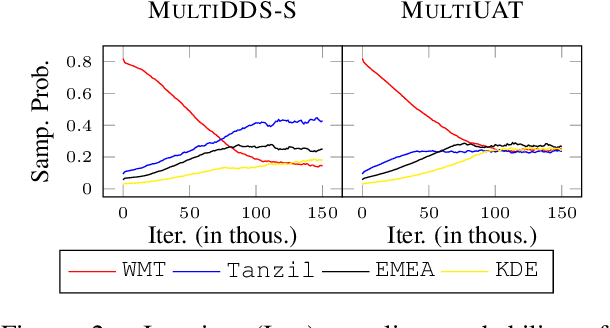
Learning multilingual and multi-domain translation model is challenging as the heterogeneous and imbalanced data make the model converge inconsistently over different corpora in real world. One common practice is to adjust the share of each corpus in the training, so that the learning process is balanced and low-resource cases can benefit from the high resource ones. However, automatic balancing methods usually depend on the intra- and inter-dataset characteristics, which is usually agnostic or requires human priors. In this work, we propose an approach, MultiUAT, that dynamically adjusts the training data usage based on the model's uncertainty on a small set of trusted clean data for multi-corpus machine translation. We experiments with two classes of uncertainty measures on multilingual (16 languages with 4 settings) and multi-domain settings (4 for in-domain and 2 for out-of-domain on English-German translation) and demonstrate our approach MultiUAT substantially outperforms its baselines, including both static and dynamic strategies. We analyze the cross-domain transfer and show the deficiency of static and similarity based methods.
AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
Jul 29, 2021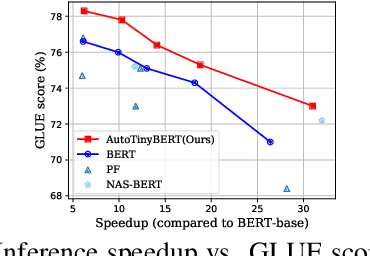
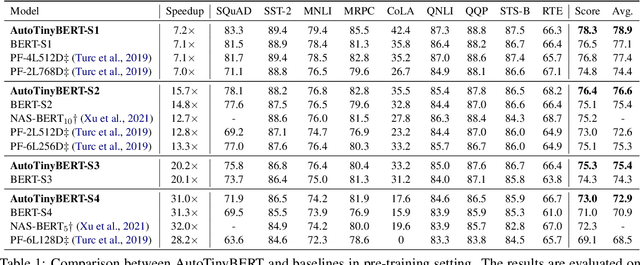
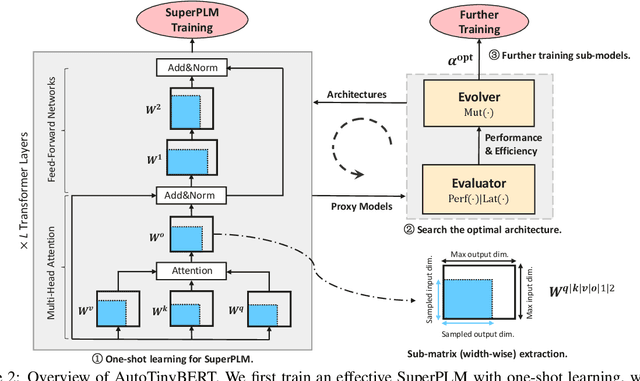
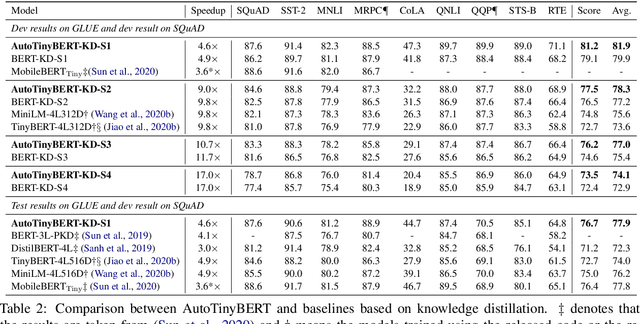
Pre-trained language models (PLMs) have achieved great success in natural language processing. Most of PLMs follow the default setting of architecture hyper-parameters (e.g., the hidden dimension is a quarter of the intermediate dimension in feed-forward sub-networks) in BERT (Devlin et al., 2019). Few studies have been conducted to explore the design of architecture hyper-parameters in BERT, especially for the more efficient PLMs with tiny sizes, which are essential for practical deployment on resource-constrained devices. In this paper, we adopt the one-shot Neural Architecture Search (NAS) to automatically search architecture hyper-parameters. Specifically, we carefully design the techniques of one-shot learning and the search space to provide an adaptive and efficient development way of tiny PLMs for various latency constraints. We name our method AutoTinyBERT and evaluate its effectiveness on the GLUE and SQuAD benchmarks. The extensive experiments show that our method outperforms both the SOTA search-based baseline (NAS-BERT) and the SOTA distillation-based methods (such as DistilBERT, TinyBERT, MiniLM and MobileBERT). In addition, based on the obtained architectures, we propose a more efficient development method that is even faster than the development of a single PLM.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 22, 2021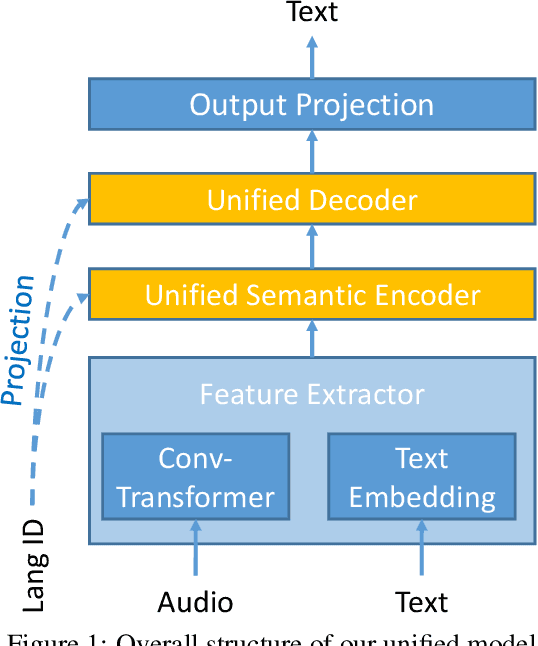
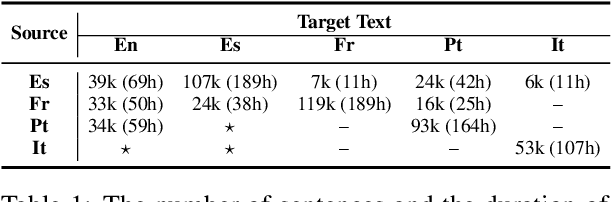
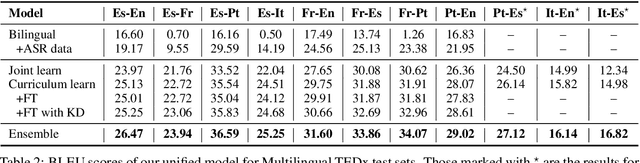
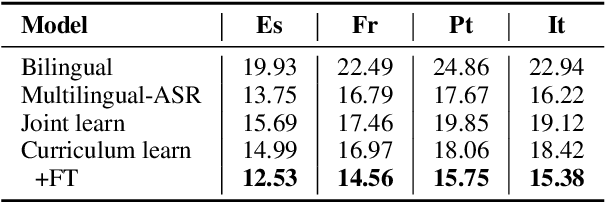
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.
A Mutual Information Maximization Approach for the Spurious Solution Problem in Weakly Supervised Question Answering
Jun 14, 2021
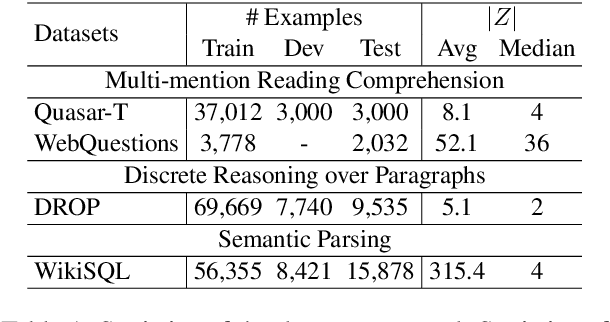
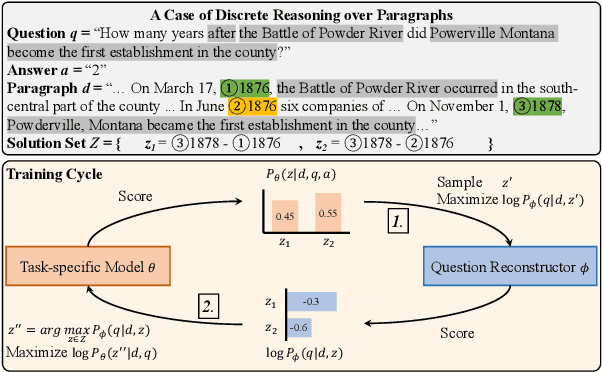
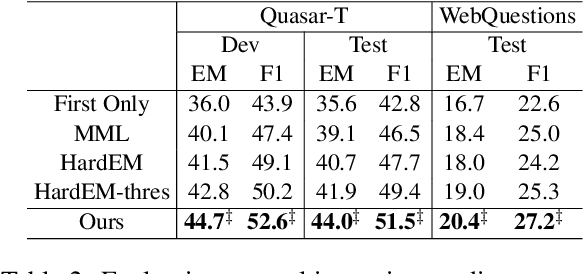
Weakly supervised question answering usually has only the final answers as supervision signals while the correct solutions to derive the answers are not provided. This setting gives rise to the spurious solution problem: there may exist many spurious solutions that coincidentally derive the correct answer, but training on such solutions can hurt model performance (e.g., producing wrong solutions or answers). For example, for discrete reasoning tasks as on DROP, there may exist many equations to derive a numeric answer, and typically only one of them is correct. Previous learning methods mostly filter out spurious solutions with heuristics or using model confidence, but do not explicitly exploit the semantic correlations between a question and its solution. In this paper, to alleviate the spurious solution problem, we propose to explicitly exploit such semantic correlations by maximizing the mutual information between question-answer pairs and predicted solutions. Extensive experiments on four question answering datasets show that our method significantly outperforms previous learning methods in terms of task performance and is more effective in training models to produce correct solutions.