 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Task-Agnostic BERT Distillation with Layer Mapping Search
Paper and Code
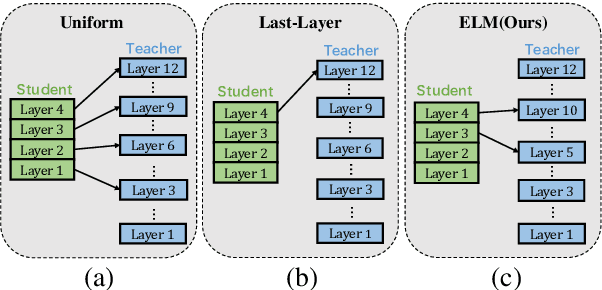

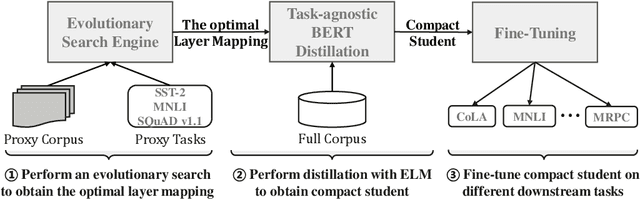
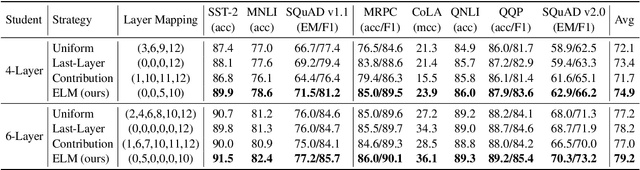
Knowledge distillation (KD) which transfers the knowledge from a large teacher model to a small student model, has been widely used to compress the BERT model recently. Besides the supervision in the output in the original KD, recent works show that layer-level supervision is crucial to the performance of the student BERT model. However, previous works designed the layer mapping strategy heuristically (e.g., uniform or last-layer), which can lead to inferior performance. In this paper, we propose to use the genetic algorithm (GA) to search for the optimal layer mapping automatically. To accelerate the search process, we further propose a proxy setting where a small portion of the training corpus are sampled for distillation, and three representative tasks are chosen for evaluation. After obtaining the optimal layer mapping, we perform the task-agnostic BERT distillation with it on the whole corpus to build a compact student model, which can be directly fine-tuned on downstream tasks. Comprehensive experiments on the evaluation benchmarks demonstrate that 1) layer mapping strategy has a significant effect on task-agnostic BERT distillation and different layer mappings can result in quite different performances; 2) the optimal layer mapping strategy from the proposed search process consistently outperforms the other heuristic ones; 3) with the optimal layer mapping, our student model achieves state-of-the-art performance on the GLUE tasks.