 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022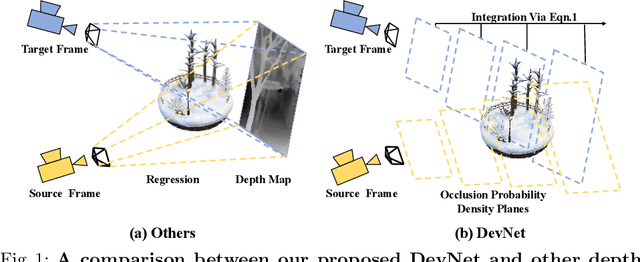
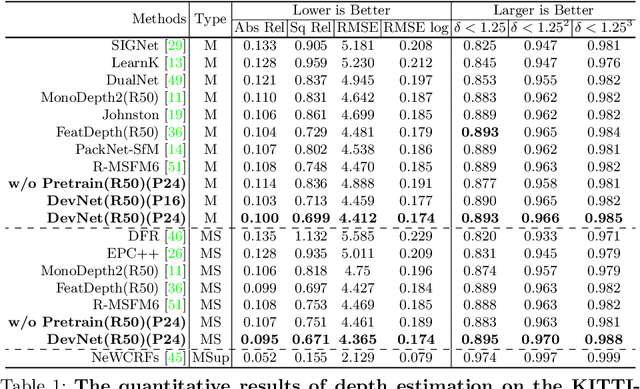
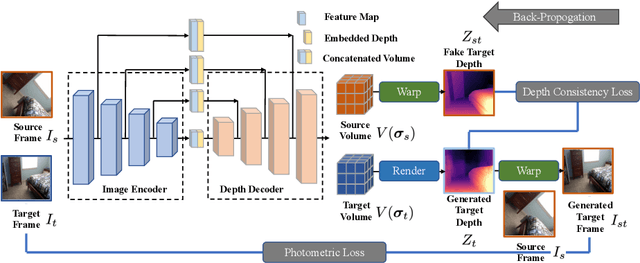

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
4DAC: Learning Attribute Compression for Dynamic Point Clouds
Apr 25, 2022
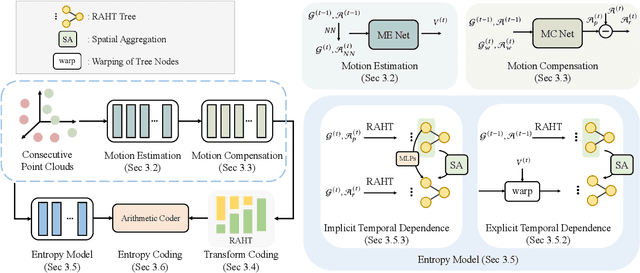
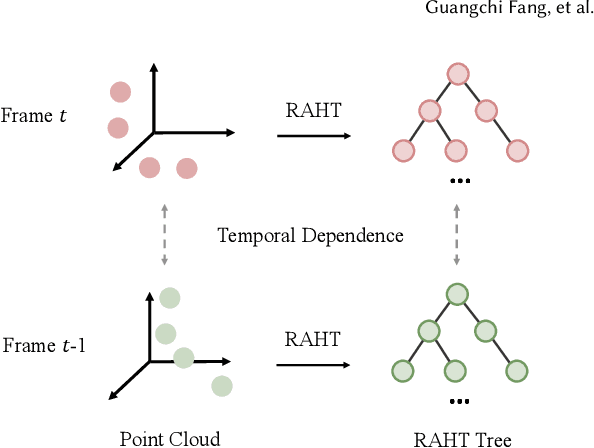
With the development of the 3D data acquisition facilities, the increasing scale of acquired 3D point clouds poses a challenge to the existing data compression techniques. Although promising performance has been achieved in static point cloud compression, it remains under-explored and challenging to leverage temporal correlations within a point cloud sequence for effective dynamic point cloud compression. In this paper, we study the attribute (e.g., color) compression of dynamic point clouds and present a learning-based framework, termed 4DAC. To reduce temporal redundancy within data, we first build the 3D motion estimation and motion compensation modules with deep neural networks. Then, the attribute residuals produced by the motion compensation component are encoded by the region adaptive hierarchical transform into residual coefficients. In addition, we also propose a deep conditional entropy model to estimate the probability distribution of the transformed coefficients, by incorporating temporal context from consecutive point clouds and the motion estimation/compensation modules. Finally, the data stream is losslessly entropy coded with the predicted distribution. Extensive experiments on several public datasets demonstrate the superior compression performance of the proposed approach.
Meta-Sampler: Almost-Universal yet Task-Oriented Sampling for Point Clouds
Mar 30, 2022Sampling is a key operation in point-cloud task and acts to increase computational efficiency and tractability by discarding redundant points. Universal sampling algorithms (e.g., Farthest Point Sampling) work without modification across different tasks, models, and datasets, but by their very nature are agnostic about the downstream task/model. As such, they have no implicit knowledge about which points would be best to keep and which to reject. Recent work has shown how task-specific point cloud sampling (e.g., SampleNet) can be used to outperform traditional sampling approaches by learning which points are more informative. However, these learnable samplers face two inherent issues: i) overfitting to a model rather than a task, and \ii) requiring training of the sampling network from scratch, in addition to the task network, somewhat countering the original objective of down-sampling to increase efficiency. In this work, we propose an almost-universal sampler, in our quest for a sampler that can learn to preserve the most useful points for a particular task, yet be inexpensive to adapt to different tasks, models, or datasets. We first demonstrate how training over multiple models for the same task (e.g., shape reconstruction) significantly outperforms the vanilla SampleNet in terms of accuracy by not overfitting the sample network to a particular task network. Second, we show how we can train an almost-universal meta-sampler across multiple tasks. This meta-sampler can then be rapidly fine-tuned when applied to different datasets, networks, or even different tasks, thus amortizing the initial cost of training.
No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces
Mar 23, 2022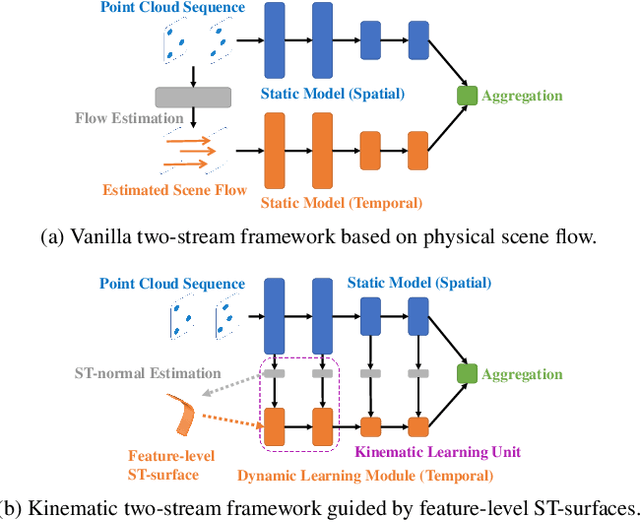
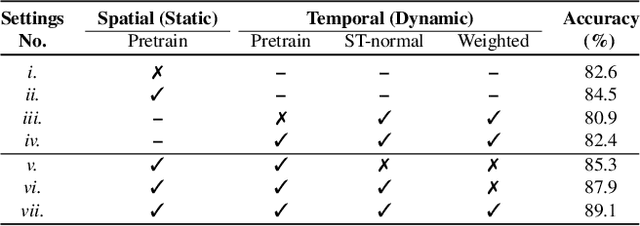
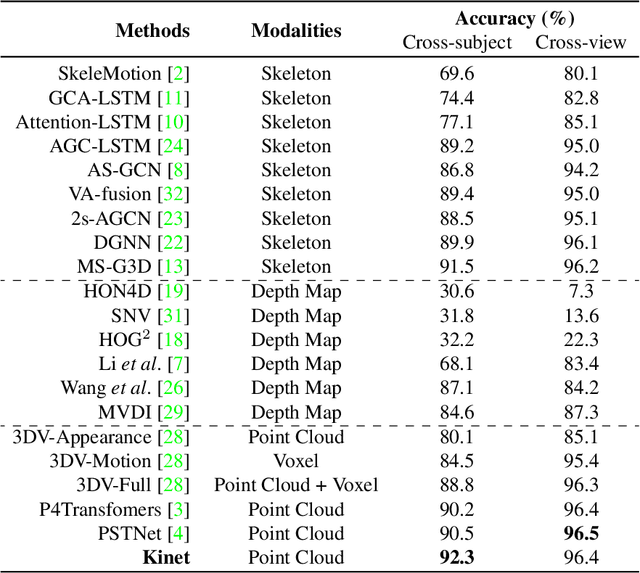
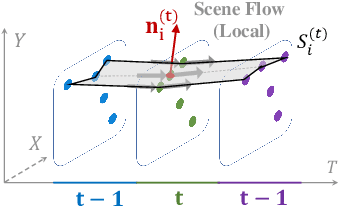
Scene flow is a powerful tool for capturing the motion field of 3D point clouds. However, it is difficult to directly apply flow-based models to dynamic point cloud classification since the unstructured points make it hard or even impossible to efficiently and effectively trace point-wise correspondences. To capture 3D motions without explicitly tracking correspondences, we propose a kinematics-inspired neural network (Kinet) by generalizing the kinematic concept of ST-surfaces to the feature space. By unrolling the normal solver of ST-surfaces in the feature space, Kinet implicitly encodes feature-level dynamics and gains advantages from the use of mature backbones for static point cloud processing. With only minor changes in network structures and low computing overhead, it is painless to jointly train and deploy our framework with a given static model. Experiments on NvGesture, SHREC'17, MSRAction-3D, and NTU-RGBD demonstrate its efficacy in performance, efficiency in both the number of parameters and computational complexity, as well as its versatility to various static backbones. Noticeably, Kinet achieves the accuracy of 93.27% on MSRAction-3D with only 3.20M parameters and 10.35G FLOPS.
Not All Points Are Equal: Learning Highly Efficient Point-based Detectors for 3D LiDAR Point Clouds
Mar 21, 2022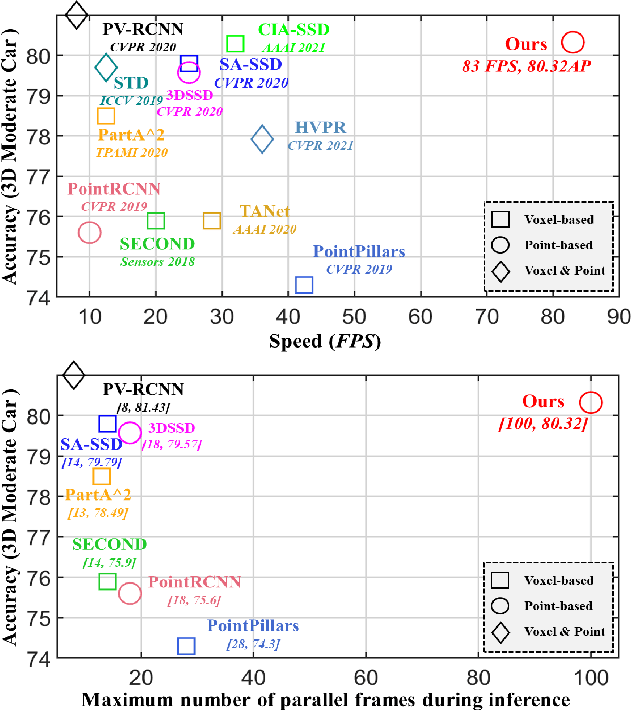

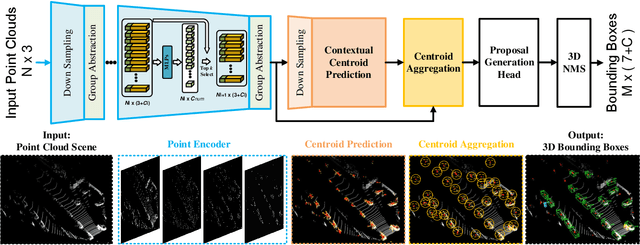
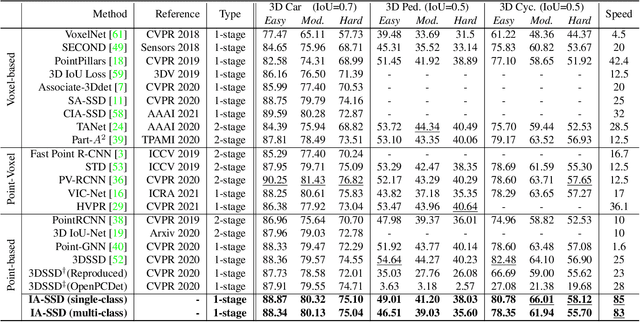
We study the problem of efficient object detection of 3D LiDAR point clouds. To reduce the memory and computational cost, existing point-based pipelines usually adopt task-agnostic random sampling or farthest point sampling to progressively downsample input point clouds, despite the fact that not all points are equally important to the task of object detection. In particular, the foreground points are inherently more important than background points for object detectors. Motivated by this, we propose a highly-efficient single-stage point-based 3D detector in this paper, termed IA-SSD. The key of our approach is to exploit two learnable, task-oriented, instance-aware downsampling strategies to hierarchically select the foreground points belonging to objects of interest. Additionally, we also introduce a contextual centroid perception module to further estimate precise instance centers. Finally, we build our IA-SSD following the encoder-only architecture for efficiency. Extensive experiments conducted on several large-scale detection benchmarks demonstrate the competitive performance of our IA-SSD. Thanks to the low memory footprint and a high degree of parallelism, it achieves a superior speed of 80+ frames-per-second on the KITTI dataset with a single RTX2080Ti GPU. The code is available at \url{https://github.com/yifanzhang713/IA-SSD}.
3DAC: Learning Attribute Compression for Point Clouds
Mar 17, 2022
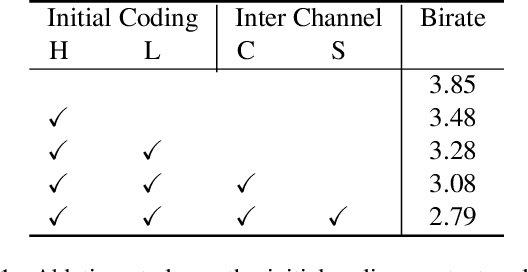
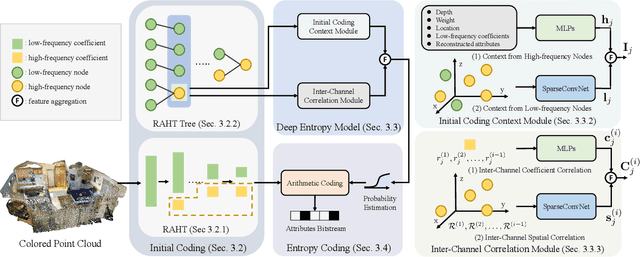
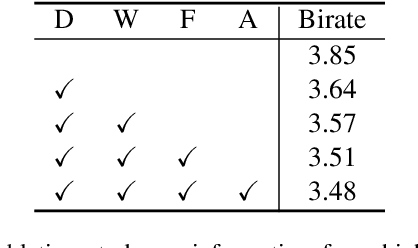
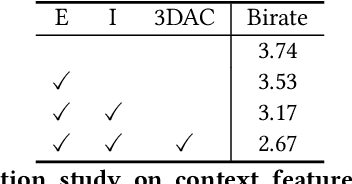
We study the problem of attribute compression for large-scale unstructured 3D point clouds. Through an in-depth exploration of the relationships between different encoding steps and different attribute channels, we introduce a deep compression network, termed 3DAC, to explicitly compress the attributes of 3D point clouds and reduce storage usage in this paper. Specifically, the point cloud attributes such as color and reflectance are firstly converted to transform coefficients. We then propose a deep entropy model to model the probabilities of these coefficients by considering information hidden in attribute transforms and previous encoded attributes. Finally, the estimated probabilities are used to further compress these transform coefficients to a final attributes bitstream. Extensive experiments conducted on both indoor and outdoor large-scale open point cloud datasets, including ScanNet and SemanticKITTI, demonstrated the superior compression rates and reconstruction quality of the proposed 3DAC.
STPLS3D: A Large-Scale Synthetic and Real Aerial Photogrammetry 3D Point Cloud Dataset
Mar 17, 2022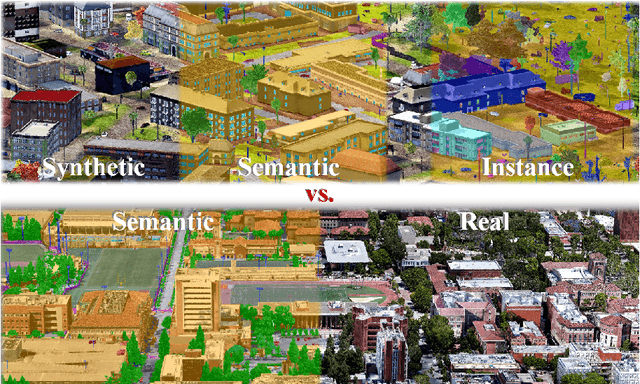

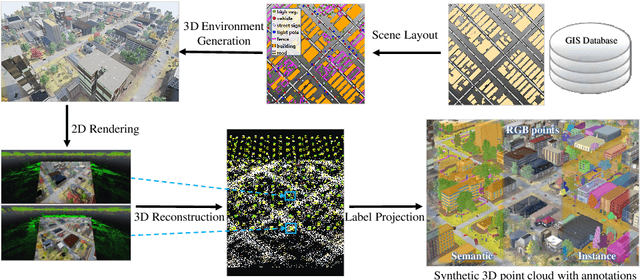

Although various 3D datasets with different functions and scales have been proposed recently, it remains challenging for individuals to complete the whole pipeline of large-scale data collection, sanitization, and annotation. Moreover, the created datasets usually suffer from extremely imbalanced class distribution or partial low-quality data samples. Motivated by this, we explore the procedurally synthetic 3D data generation paradigm to equip individuals with the full capability of creating large-scale annotated photogrammetry point clouds. Specifically, we introduce a synthetic aerial photogrammetry point clouds generation pipeline that takes full advantage of open geospatial data sources and off-the-shelf commercial packages. Unlike generating synthetic data in virtual games, where the simulated data usually have limited gaming environments created by artists, the proposed pipeline simulates the reconstruction process of the real environment by following the same UAV flight pattern on different synthetic terrain shapes and building densities, which ensure similar quality, noise pattern, and diversity with real data. In addition, the precise semantic and instance annotations can be generated fully automatically, avoiding the expensive and time-consuming manual annotation. Based on the proposed pipeline, we present a richly-annotated synthetic 3D aerial photogrammetry point cloud dataset, termed STPLS3D, with more than 16 $km^2$ of landscapes and up to 18 fine-grained semantic categories. For verification purposes, we also provide a parallel dataset collected from four areas in the real environment. Extensive experiments conducted on our datasets demonstrate the effectiveness and quality of the proposed synthetic dataset.
SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Jan 12, 2022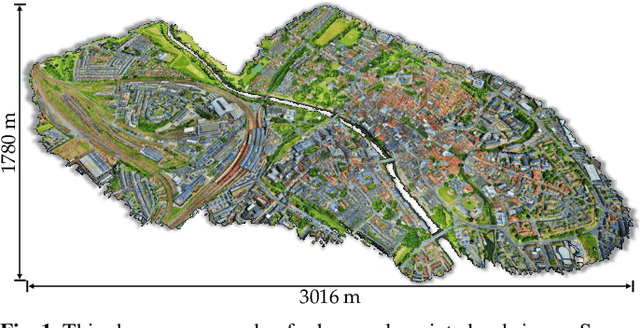
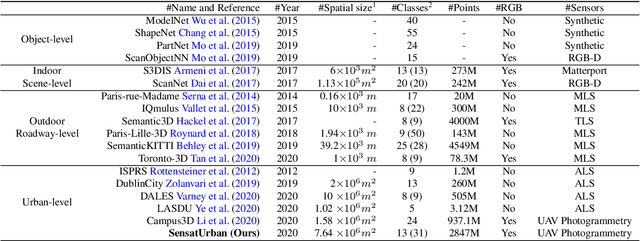

With the recent availability and affordability of commercial depth sensors and 3D scanners, an increasing number of 3D (i.e., RGBD, point cloud) datasets have been publicized to facilitate research in 3D computer vision. However, existing datasets either cover relatively small areas or have limited semantic annotations. Fine-grained understanding of urban-scale 3D scenes is still in its infancy. In this paper, we introduce SensatUrban, an urban-scale UAV photogrammetry point cloud dataset consisting of nearly three billion points collected from three UK cities, covering 7.6 km^2. Each point in the dataset has been labelled with fine-grained semantic annotations, resulting in a dataset that is three times the size of the previous existing largest photogrammetric point cloud dataset. In addition to the more commonly encountered categories such as road and vegetation, urban-level categories including rail, bridge, and river are also included in our dataset. Based on this dataset, we further build a benchmark to evaluate the performance of state-of-the-art segmentation algorithms. In particular, we provide a comprehensive analysis and identify several key challenges limiting urban-scale point cloud understanding. The dataset is available at http://point-cloud-analysis.cs.ox.ac.uk.
Box2Seg: Learning Semantics of 3D Point Clouds with Box-Level Supervision
Jan 09, 2022
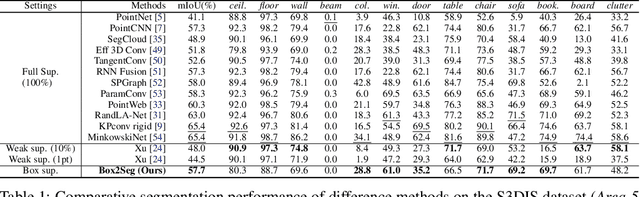
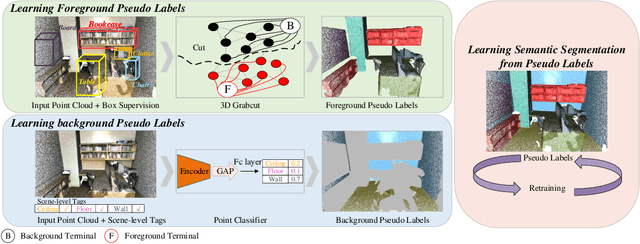
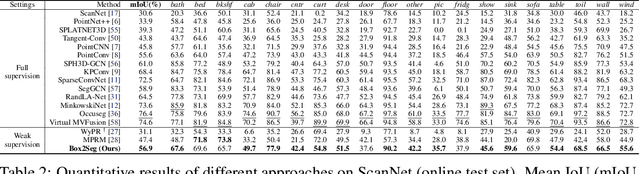
Learning dense point-wise semantics from unstructured 3D point clouds with fewer labels, although a realistic problem, has been under-explored in literature. While existing weakly supervised methods can effectively learn semantics with only a small fraction of point-level annotations, we find that the vanilla bounding box-level annotation is also informative for semantic segmentation of large-scale 3D point clouds. In this paper, we introduce a neural architecture, termed Box2Seg, to learn point-level semantics of 3D point clouds with bounding box-level supervision. The key to our approach is to generate accurate pseudo labels by exploring the geometric and topological structure inside and outside each bounding box. Specifically, an attention-based self-training (AST) technique and Point Class Activation Mapping (PCAM) are utilized to estimate pseudo-labels. The network is further trained and refined with pseudo labels. Experiments on two large-scale benchmarks including S3DIS and ScanNet demonstrate the competitive performance of the proposed method. In particular, the proposed network can be trained with cheap, or even off-the-shelf bounding box-level annotations and subcloud-level tags.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021
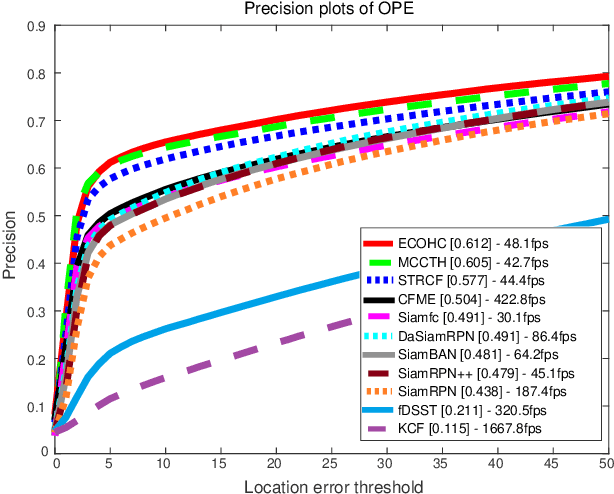
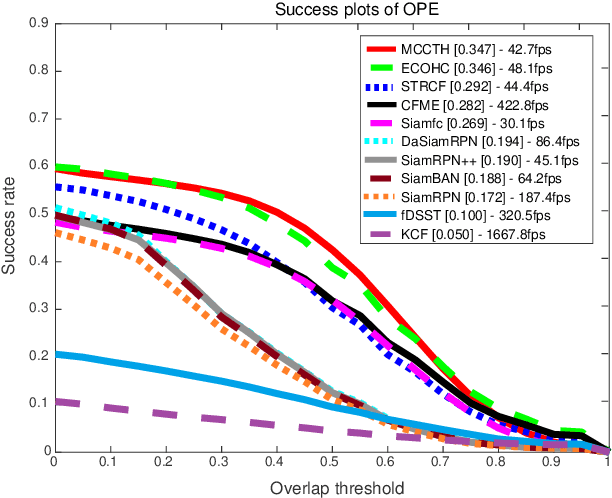

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.