 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftChannel: Algorithm-Hardware Co-Design for Deep Learning-Based 5G Channel Estimation
May 03, 2026Channel estimation is crucial in 5G communication networks for optimizing transmission parameters and ensuring reliable, high-speed communication. However, the use of multiple-input and multiple-output (MIMO) and millimeter-wave (mmWave) in 5G networks presents challenges in achieving accurate estimation under strict latency requirements on resource-limited hardware platforms. To address these challenges, we propose SwiftChannel, an algorithm-hardware co-design framework that integrates a hardware-friendly deep learning-based channel estimator with a dedicated accelerator. Our approach employs a convolutional neural network enhanced with a parameter-free attention mechanism, which effectively reconstructs full-resolution spatial-frequency domain channel matrices from low-resolution least squares (LS) estimates. We further develop a multi-stage model compression pipeline combining knowledge distillation, convolution re-parameterization, and quantization-aware training, resulting in substantial model size reduction with negligible accuracy loss. The hardware accelerator, implementing the compressed model and the LS estimator on FPGA platforms using High-level Synthesis (HLS), features a fine-grained pipeline architecture and optimized dataflow strategies. Tested on a Zynq UltraScale+ RFSoC, the accelerator achieves sub-millisecond latency, providing up to 24x speed-up and over 33x improvement in energy efficiency compared to GPU-based solutions. Extensive evaluations demonstrate that the proposed design generalizes not only across various noise levels and user mobilities, but also to a variety of unseen channel profiles, outperforming state-of-the-art baselines. By unifying algorithmic innovation with hardware-aware design, our work presents a future-proof channel estimation solution for 5G MIMO systems.
Habitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
Apr 14, 2026Training embodied AI agents depends critically on the visual fidelity of simulation environments and the ability to model dynamic humans. Current simulators rely on mesh-based rasterization with limited visual realism, and their support for dynamic human avatars, where available, is constrained to mesh representations, hindering agent generalization to human-populated real-world scenarios. We present Habitat-GS, a navigation-centric embodied AI simulator extended from Habitat-Sim that integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem. Our system implements a 3DGS renderer for real-time photorealistic rendering and supports scalable 3DGS asset import from diverse sources. For dynamic human modeling, we introduce a gaussian avatar module that enables each avatar to simultaneously serve as a photorealistic visual entity and an effective navigation obstacle, allowing agents to learn human-aware behaviors in realistic settings. Experiments on point-goal navigation demonstrate that agents trained on 3DGS scenes achieve stronger cross-domain generalization, with mixed-domain training being the most effective strategy. Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation. Finally, performance benchmarks validate the system's scalability across varying scene complexity and avatar counts.
Efficient and Adaptable Detection of Malicious LLM Prompts via Bootstrap Aggregation
Feb 08, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and generation. However, these systems remain susceptible to malicious prompts that induce unsafe or policy-violating behavior through harmful requests, jailbreak techniques, and prompt injection attacks. Existing defenses face fundamental limitations: black-box moderation APIs offer limited transparency and adapt poorly to evolving threats, while white-box approaches using large LLM judges impose prohibitive computational costs and require expensive retraining for new attacks. Current systems force designers to choose between performance, efficiency, and adaptability. To address these challenges, we present BAGEL (Bootstrap AGgregated Ensemble Layer), a modular, lightweight, and incrementally updatable framework for malicious prompt detection. BAGEL employs a bootstrap aggregation and mixture of expert inspired ensemble of fine-tuned models, each specialized on a different attack dataset. At inference, BAGEL uses a random forest router to identify the most suitable ensemble member, then applies stochastic selection to sample additional members for prediction aggregation. When new attacks emerge, BAGEL updates incrementally by fine-tuning a small prompt-safety classifier (86M parameters) and adding the resulting model to the ensemble. BAGEL achieves an F1 score of 0.92 by selecting just 5 ensemble members (430M parameters), outperforming OpenAI Moderation API and ShieldGemma which require billions of parameters. Performance remains robust after nine incremental updates, and BAGEL provides interpretability through its router's structural features. Our results show ensembles of small finetuned classifiers can match or exceed billion-parameter guardrails while offering the adaptability and efficiency required for production systems.
RoPETR: Improving Temporal Camera-Only 3D Detection by Integrating Enhanced Rotary Position Embedding
Apr 18, 2025This technical report introduces a targeted improvement to the StreamPETR framework, specifically aimed at enhancing velocity estimation, a critical factor influencing the overall NuScenes Detection Score. While StreamPETR exhibits strong 3D bounding box detection performance as reflected by its high mean Average Precision our analysis identified velocity estimation as a substantial bottleneck when evaluated on the NuScenes dataset. To overcome this limitation, we propose a customized positional embedding strategy tailored to enhance temporal modeling capabilities. Experimental evaluations conducted on the NuScenes test set demonstrate that our improved approach achieves a state-of-the-art NDS of 70.86% using the ViT-L backbone, setting a new benchmark for camera-only 3D object detection.
A Survey on Backdoor Threats in Large Language Models (LLMs): Attacks, Defenses, and Evaluations
Feb 06, 2025



Large Language Models (LLMs) have achieved significantly advanced capabilities in understanding and generating human language text, which have gained increasing popularity over recent years. Apart from their state-of-the-art natural language processing (NLP) performance, considering their widespread usage in many industries, including medicine, finance, education, etc., security concerns over their usage grow simultaneously. In recent years, the evolution of backdoor attacks has progressed with the advancement of defense mechanisms against them and more well-developed features in the LLMs. In this paper, we adapt the general taxonomy for classifying machine learning attacks on one of the subdivisions - training-time white-box backdoor attacks. Besides systematically classifying attack methods, we also consider the corresponding defense methods against backdoor attacks. By providing an extensive summary of existing works, we hope this survey can serve as a guideline for inspiring future research that further extends the attack scenarios and creates a stronger defense against them for more robust LLMs.
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised
Sep 10, 2024Road segmentation is a critical task for autonomous driving systems, requiring accurate and robust methods to classify road surfaces from various environmental data. Our work introduces an innovative approach that integrates LiDAR point cloud data, visual image, and relative depth maps derived from images. The integration of multiple data sources in road segmentation presents both opportunities and challenges. One of the primary challenges is the scarcity of large-scale, accurately labeled datasets that are necessary for training robust deep learning models. To address this, we have developed the [UdeerLID+] framework under a semi-supervised learning paradigm. Experiments results on KITTI datasets validate the superior performance.
Explore BiLSTM-CRF-Based Models for Open Relation Extraction
Apr 26, 2021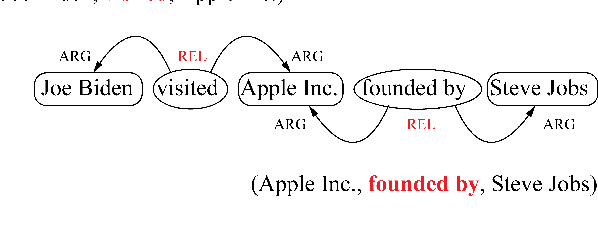
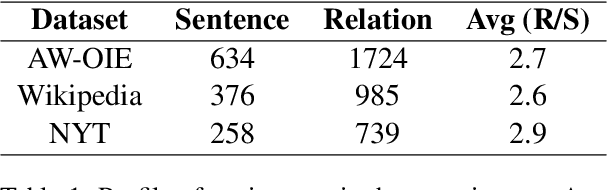
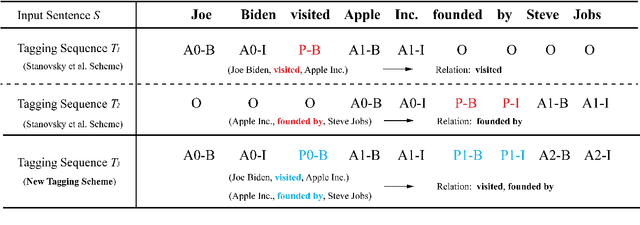

Extracting multiple relations from text sentences is still a challenge for current Open Relation Extraction (Open RE) tasks. In this paper, we develop several Open RE models based on the bidirectional LSTM-CRF (BiLSTM-CRF) neural network and different contextualized word embedding methods. We also propose a new tagging scheme to solve overlapping problems and enhance models' performance. From the evaluation results and comparisons between models, we select the best combination of tagging scheme, word embedder, and BiLSTM-CRF network to achieve an Open RE model with a remarkable extracting ability on multiple-relation sentences.