 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Respiratory Effort from Nocturnal Breathing Sounds for Obstructive Sleep Apnoea Screening
Sep 18, 2025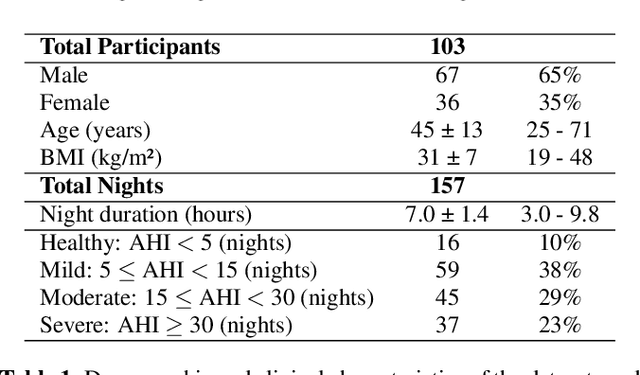
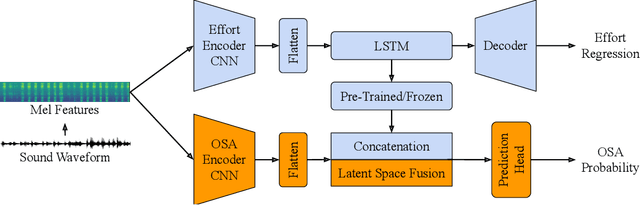

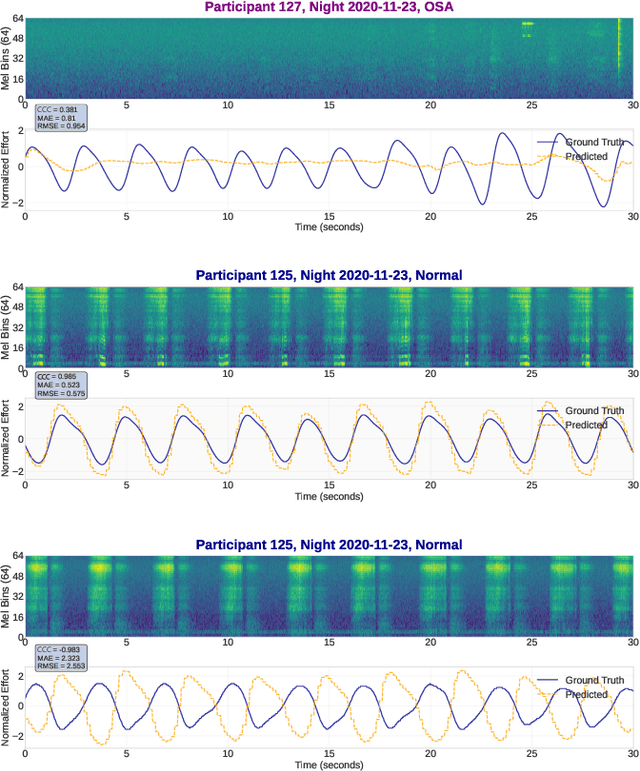
Obstructive sleep apnoea (OSA) is a prevalent condition with significant health consequences, yet many patients remain undiagnosed due to the complexity and cost of over-night polysomnography. Acoustic-based screening provides a scalable alternative, yet performance is limited by environmental noise and the lack of physiological context. Respiratory effort is a key signal used in clinical scoring of OSA events, but current approaches require additional contact sensors that reduce scalability and patient comfort. This paper presents the first study to estimate respiratory effort directly from nocturnal audio, enabling physiological context to be recovered from sound alone. We propose a latent-space fusion framework that integrates the estimated effort embeddings with acoustic features for OSA detection. Using a dataset of 157 nights from 103 participants recorded in home environments, our respiratory effort estimator achieves a concordance correlation coefficient of 0.48, capturing meaningful respiratory dynamics. Fusing effort and audio improves sensitivity and AUC over audio-only baselines, especially at low apnoea-hypopnoea index thresholds. The proposed approach requires only smartphone audio at test time, which enables sensor-free, scalable, and longitudinal OSA monitoring.
Frame-Voyager: Learning to Query Frames for Video Large Language Models
Oct 07, 2024Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by the maximum length of input tokens, making it impractical to input entire videos. Existing frame selection approaches, such as uniform frame sampling and text-frame retrieval, fail to account for the information density variations in the videos or the complex instructions in the tasks, leading to sub-optimal performance. In this paper, we propose Frame-Voyager that learns to query informative frame combinations, based on the given textual queries in the task. To train Frame-Voyager, we introduce a new data collection and labeling pipeline, by ranking frame combinations using a pre-trained Video-LLM. Given a video of M frames, we traverse its T-frame combinations, feed them into a Video-LLM, and rank them based on Video-LLM's prediction losses. Using this ranking as supervision, we train Frame-Voyager to query the frame combinations with lower losses. In experiments, we evaluate Frame-Voyager on four Video Question Answering benchmarks by plugging it into two different Video-LLMs. The experimental results demonstrate that Frame-Voyager achieves impressive results in all settings, highlighting its potential as a plug-and-play solution for Video-LLMs.
Deep learning-based framework for cardiac function assessment in embryonic zebrafish from heart beating videos
Feb 24, 2021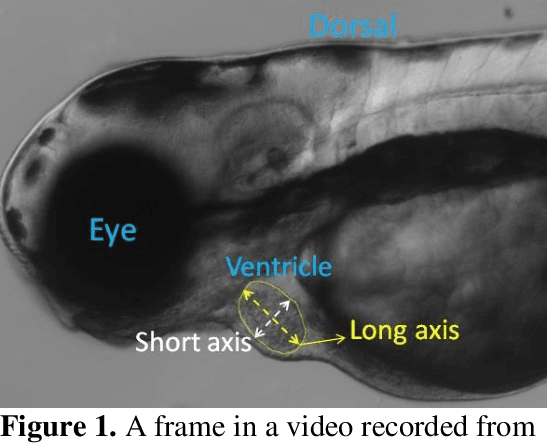
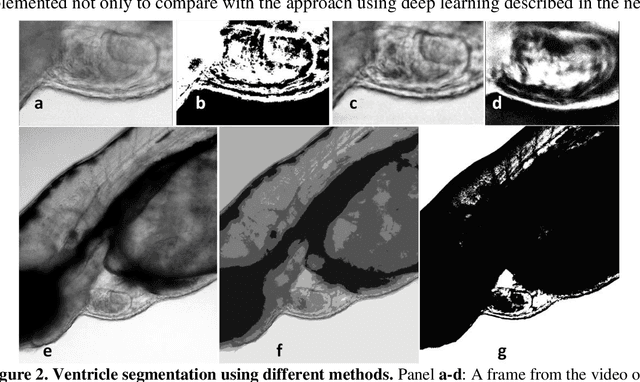
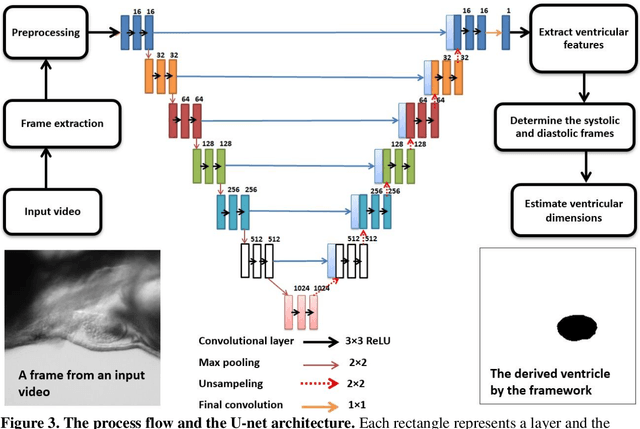
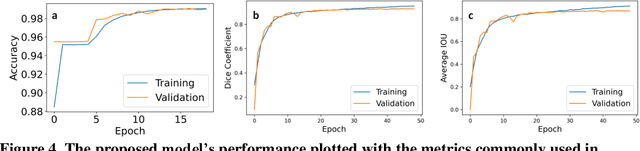
Zebrafish is a powerful and widely-used model system for a host of biological investigations including cardiovascular studies and genetic screening. Zebrafish are readily assessable during developmental stages; however, the current methods for quantification and monitoring of cardiac functions mostly involve tedious manual work and inconsistent estimations. In this paper, we developed and validated a Zebrafish Automatic Cardiovascular Assessment Framework (ZACAF) based on a U-net deep learning model for automated assessment of cardiovascular indices, such as ejection fraction (EF) and fractional shortening (FS) from microscopic videos of wildtype and cardiomyopathy mutant zebrafish embryos. Our approach yielded favorable performance with accuracy above 90% compared with manual processing. We used only black and white regular microscopic recordings with frame rates of 5-20 frames per second (fps); thus, the framework could be widely applicable with any laboratory resources and infrastructure. Most importantly, the automatic feature holds promise to enable efficient, consistent and reliable processing and analysis capacity for large amounts of videos, which can be generated by diverse collaborating teams.