 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022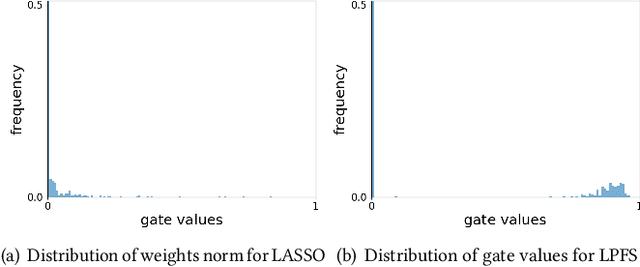
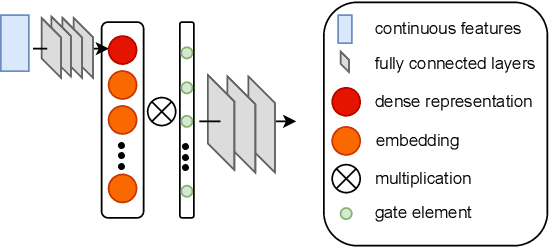

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Continual Learning and Private Unlearning
Mar 24, 2022
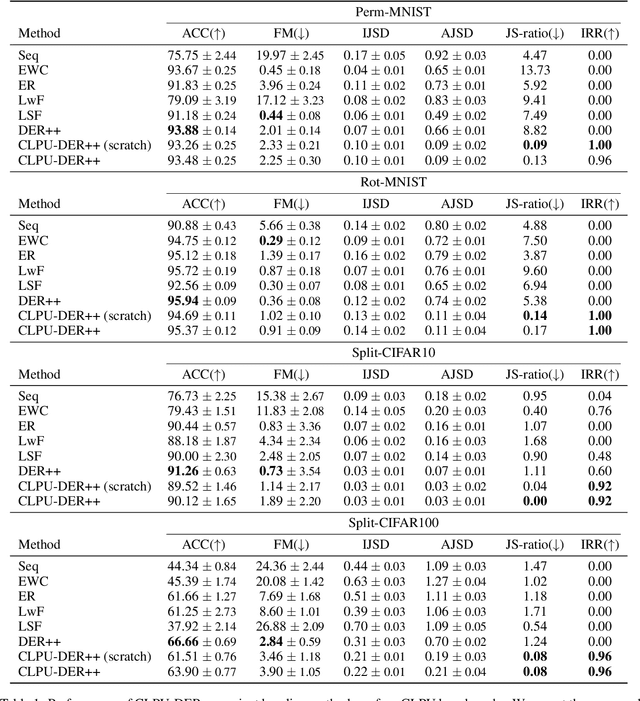
As intelligent agents become autonomous over longer periods of time, they may eventually become lifelong counterparts to specific people. If so, it may be common for a user to want the agent to master a task temporarily but later on to forget the task due to privacy concerns. However enabling an agent to \emph{forget privately} what the user specified without degrading the rest of the learned knowledge is a challenging problem. With the aim of addressing this challenge, this paper formalizes this continual learning and private unlearning (CLPU) problem. The paper further introduces a straightforward but exactly private solution, CLPU-DER++, as the first step towards solving the CLPU problem, along with a set of carefully designed benchmark problems to evaluate the effectiveness of the proposed solution.
WCL-BBCD: A Contrastive Learning and Knowledge Graph Approach to Named Entity Recognition
Mar 14, 2022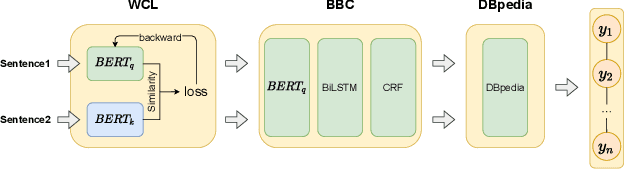
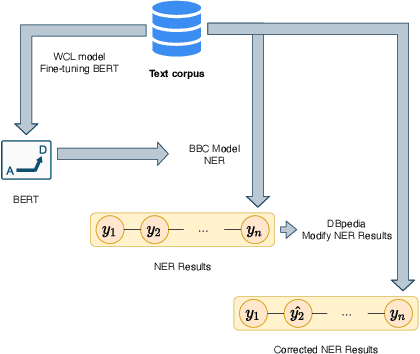
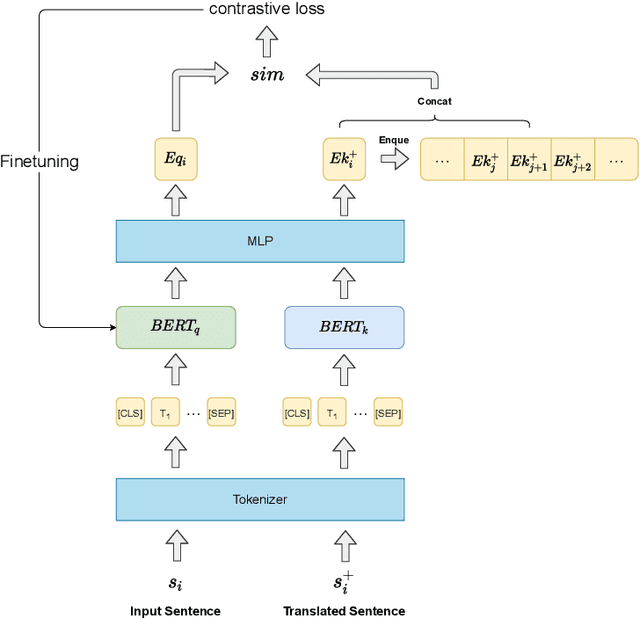
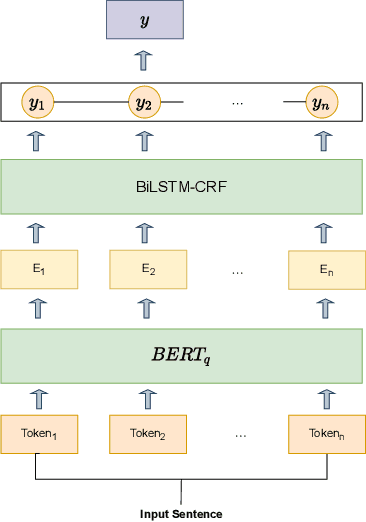
Named Entity Recognition task is one of the core tasks of information extraction.Word ambiguity and word abbreviation are important reasons for the low recognition rate of named entities. In this paper, we propose a novel named entity recognition model WCL-BBCD (Word Contrastive Learning with BERT-BiLSTM-CRF-DBpedia) incorporating the idea of contrastive learning. The model first trains the sentence pairs in the text, calculate similarity between words in sentence pairs by cosine similarity, and fine-tunes the BERT model used for the named entity recognition task through the similarity, so as to alleviate word ambiguity. Then, the fine-tuned BERT model is combined with the BiLSTM-CRF model to perform the named entity recognition task. Finally, the recognition results are corrected in combination with prior knowledge such as knowledge graphs, so as to alleviate the recognition caused by word abbreviations low-rate problem. Experimental results show that our model outperforms other similar model methods on the CoNLL-2003 English dataset and OntoNotes V5 English dataset.
A Survey on Deep Graph Generation: Methods and Applications
Mar 13, 2022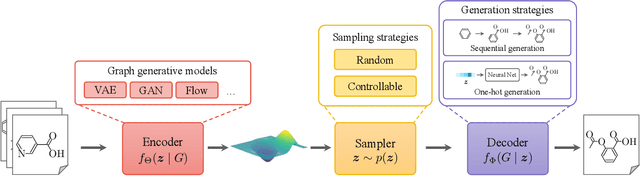

Graphs are ubiquitous in encoding relational information of real-world objects in many domains. Graph generation, whose purpose is to generate new graphs from a distribution similar to the observed graphs, has received increasing attention thanks to the recent advances of deep learning models. In this paper, we conduct a comprehensive review on the existing literature of graph generation from a variety of emerging methods to its wide application areas. Specifically, we first formulate the problem of deep graph generation and discuss its difference with several related graph learning tasks. Secondly, we divide the state-of-the-art methods into three categories based on model architectures and summarize their generation strategies. Thirdly, we introduce three key application areas of deep graph generation. Lastly, we highlight challenges and opportunities in the future study of deep graph generation.
A Dual Neighborhood Hypergraph Neural Network for Change Detection in VHR Remote Sensing Images
Feb 27, 2022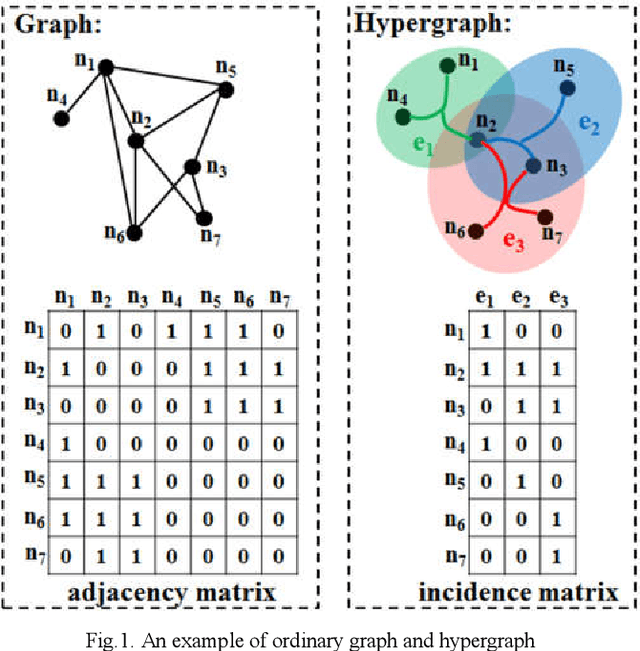
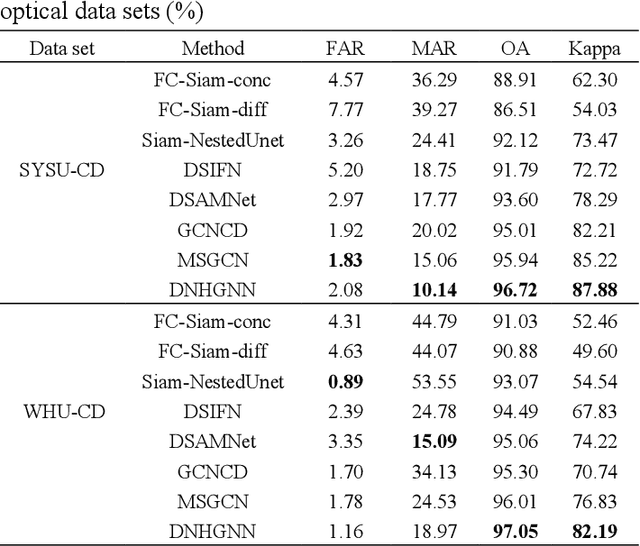
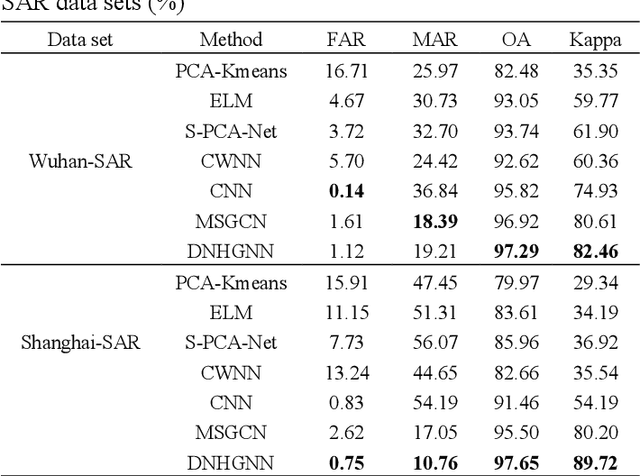
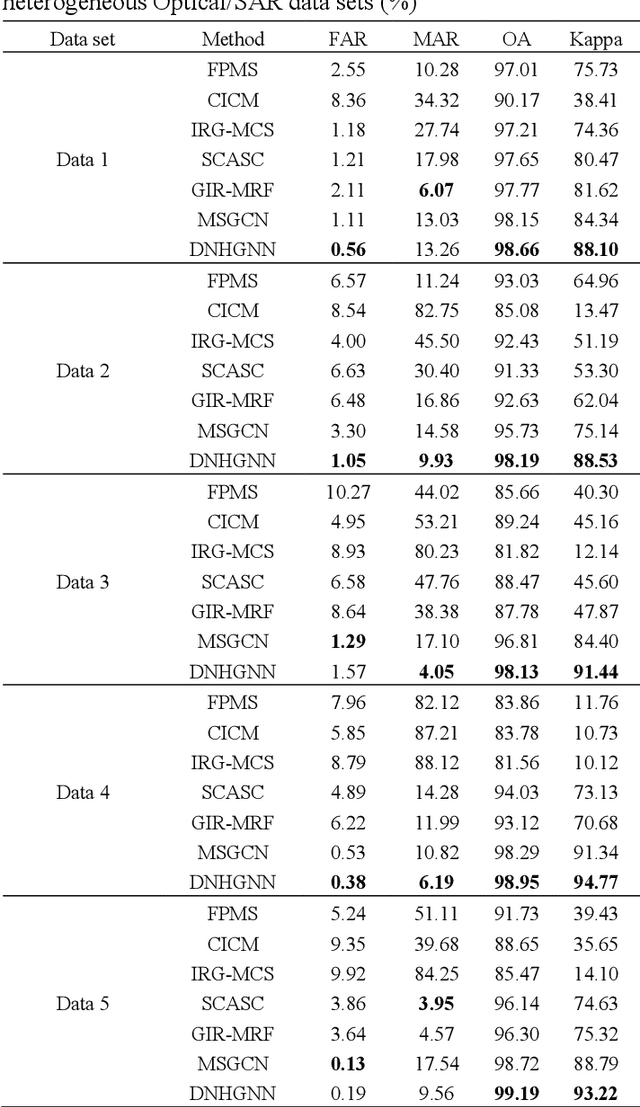
The very high spatial resolution (VHR) remote sensing images have been an extremely valuable source for monitoring changes occurred on the earth surface. However, precisely detecting relevant changes in VHR images still remains a challenge, due to the complexity of the relationships among ground objects. To address this limitation, a dual neighborhood hypergraph neural network is proposed in this article, which combines the multiscale superpixel segmentation and hypergraph convolution to model and exploit the complex relationships. First, the bi-temporal image pairs are segmented under two scales and fed to a pre-trained U-net to obtain node features by treating each object under the fine scale as a node. The dual neighborhood is then defined using the father-child and adjacent relationships of the segmented objects to construct the hypergraph, which permits models to represent the higher-order structured information far more complex than just pairwise relationships. The hypergraph convolutions are conducted on the constructed hypergraph to propagate the label information from a small amount of labeled nodes to the other unlabeled ones by the node-edge-node transform. Moreover, to alleviate the problem of imbalanced sample, the focal loss function is adopted to train the hypergraph neural network. The experimental results on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method comprises better effectiveness and robustness compared to many state-of-the-art methods.
How to Fill the Optimum Set? Population Gradient Descent with Harmless Diversity
Feb 16, 2022
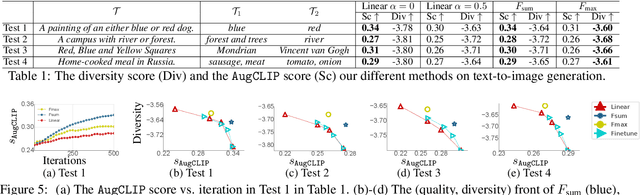
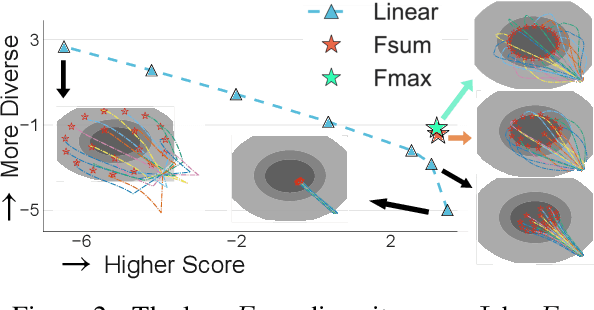

Although traditional optimization methods focus on finding a single optimal solution, most objective functions in modern machine learning problems, especially those in deep learning, often have multiple or infinite numbers of optima. Therefore, it is useful to consider the problem of finding a set of diverse points in the optimum set of an objective function. In this work, we frame this problem as a bi-level optimization problem of maximizing a diversity score inside the optimum set of the main loss function, and solve it with a simple population gradient descent framework that iteratively updates the points to maximize the diversity score in a fashion that does not hurt the optimization of the main loss. We demonstrate that our method can efficiently generate diverse solutions on a variety of applications, including text-to-image generation, text-to-mesh generation, molecular conformation generation and ensemble neural network training.
Evidence-aware Fake News Detection with Graph Neural Networks
Feb 08, 2022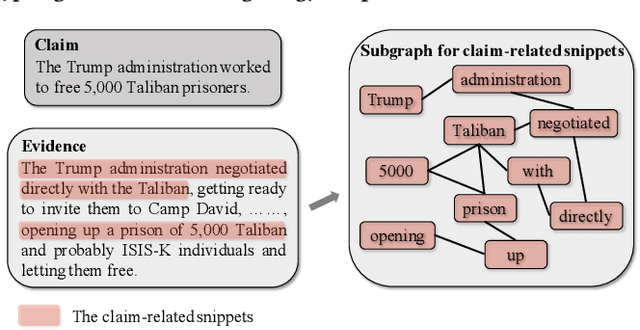
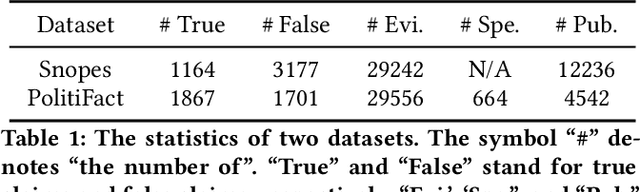
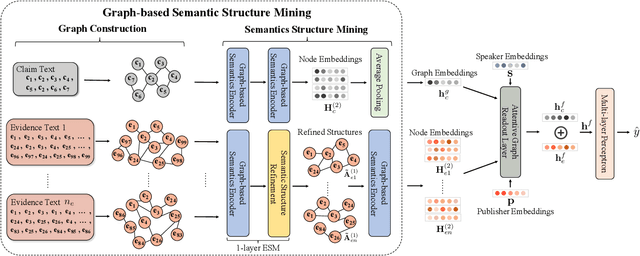
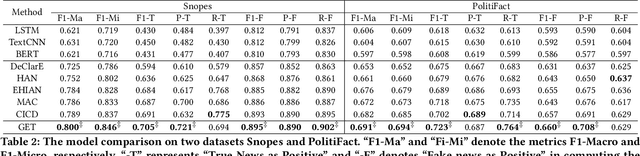
The prevalence and perniciousness of fake news has been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on the evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on different attention mechanisms. Despite their effectiveness, they still suffer from two main weaknesses. Firstly, due to the inherent drawbacks of sequential models, they fail to integrate the relevant information that is scattered far apart in evidences for veracity checking. Secondly, they neglect much redundant information contained in evidences that may be useless or even harmful. To solve these problems, we propose a unified Graph-based sEmantic sTructure mining framework, namely GET in short. Specifically, different from the existing work that treats claims and evidences as sequences, we model them as graph-structured data and capture the long-distance semantic dependency among dispersed relevant snippets via neighborhood propagation. After obtaining contextual semantic information, our model reduces information redundancy by performing graph structure learning. Finally, the fine-grained semantic representations are fed into the downstream claim-evidence interaction module for predictions. Comprehensive experiments have demonstrated the superiority of GET over the state-of-the-arts.
EdgeMap: CrowdSourcing High Definition Map in Automotive Edge Computing
Jan 20, 2022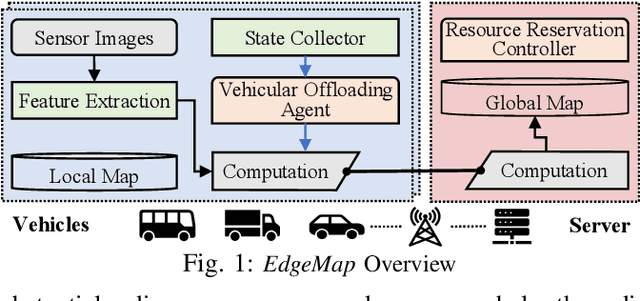
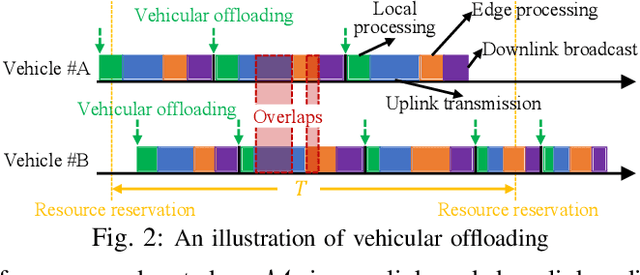
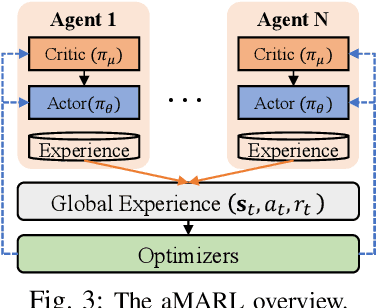
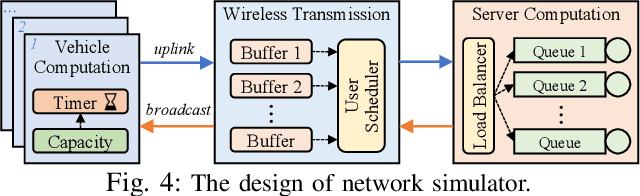
High definition (HD) map needs to be updated frequently to capture road changes, which is constrained by limited specialized collection vehicles. To maintain an up-to-date map, we explore crowdsourcing data from connected vehicles. Updating the map collaboratively is, however, challenging under constrained transmission and computation resources in dynamic networks. In this paper, we propose EdgeMap, a crowdsourcing HD map to minimize the usage of network resources while maintaining the latency requirements. We design a DATE algorithm to adaptively offload vehicular data on a small time scale and reserve network resources on a large time scale, by leveraging the multi-agent deep reinforcement learning and Gaussian process regression. We evaluate the performance of EdgeMap with extensive network simulations in a time-driven end-to-end simulator. The results show that EdgeMap reduces more than 30% resource usage as compared to state-of-the-art solutions.
Operator Deep Q-Learning: Zero-Shot Reward Transferring in Reinforcement Learning
Jan 01, 2022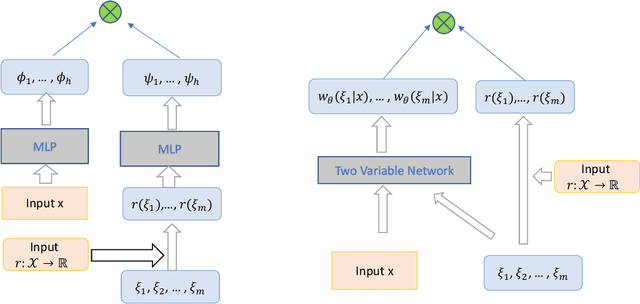

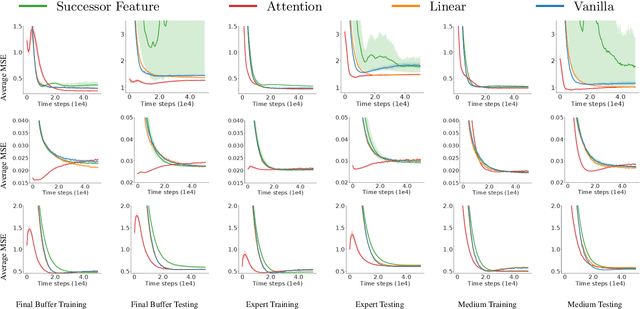

Reinforcement learning (RL) has drawn increasing interests in recent years due to its tremendous success in various applications. However, standard RL algorithms can only be applied for single reward function, and cannot adapt to an unseen reward function quickly. In this paper, we advocate a general operator view of reinforcement learning, which enables us to directly approximate the operator that maps from reward function to value function. The benefit of learning the operator is that we can incorporate any new reward function as input and attain its corresponding value function in a zero-shot manner. To approximate this special type of operator, we design a number of novel operator neural network architectures based on its theoretical properties. Our design of operator networks outperform the existing methods and the standard design of general purpose operator network, and we demonstrate the benefit of our operator deep Q-learning framework in several tasks including reward transferring for offline policy evaluation (OPE) and reward transferring for offline policy optimization in a range of tasks.
Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks
Dec 30, 2021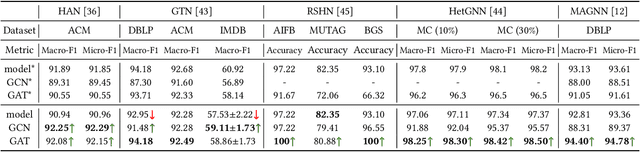

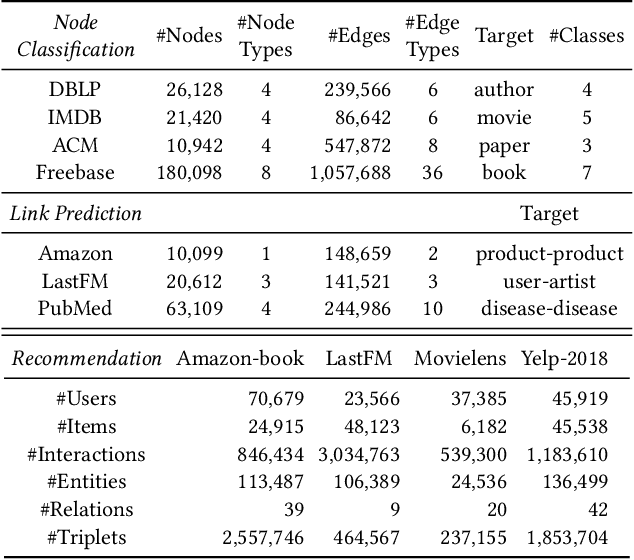
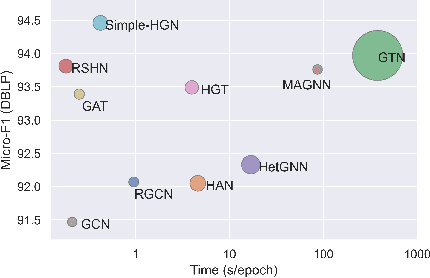
Heterogeneous graph neural networks (HGNNs) have been blossoming in recent years, but the unique data processing and evaluation setups used by each work obstruct a full understanding of their advancements. In this work, we present a systematical reproduction of 12 recent HGNNs by using their official codes, datasets, settings, and hyperparameters, revealing surprising findings about the progress of HGNNs. We find that the simple homogeneous GNNs, e.g., GCN and GAT, are largely underestimated due to improper settings. GAT with proper inputs can generally match or outperform all existing HGNNs across various scenarios. To facilitate robust and reproducible HGNN research, we construct the Heterogeneous Graph Benchmark (HGB), consisting of 11 diverse datasets with three tasks. HGB standardizes the process of heterogeneous graph data splits, feature processing, and performance evaluation. Finally, we introduce a simple but very strong baseline Simple-HGN--which significantly outperforms all previous models on HGB--to accelerate the advancement of HGNNs in the future.