 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025



Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

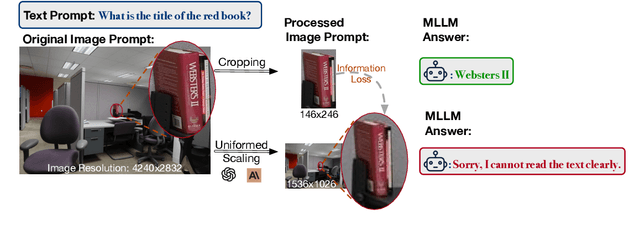
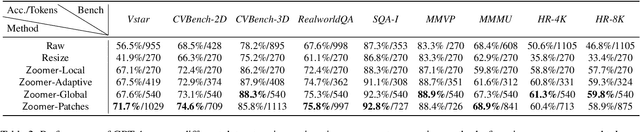
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
Effective Length Extrapolation via Dimension-Wise Positional Embeddings Manipulation
Apr 26, 2025Large Language Models (LLMs) often struggle to process and generate coherent context when the number of input tokens exceeds the pre-trained length. Recent advancements in long-context extension have significantly expanded the context window of LLMs but require expensive overhead to train the large-scale models with longer context. In this work, we propose Dimension-Wise Positional Embeddings Manipulation (DPE), a training-free framework to extrapolate the context window of LLMs by diving into RoPE's different hidden dimensions. Instead of manipulating all dimensions equally, DPE detects the effective length for every dimension and finds the key dimensions for context extension. We reuse the original position indices with their embeddings from the pre-trained model and manipulate the key dimensions' position indices to their most effective lengths. In this way, DPE adjusts the pre-trained models with minimal modifications while ensuring that each dimension reaches its optimal state for extrapolation. DPE significantly surpasses well-known baselines such as YaRN and Self-Extend. DPE enables Llama3-8k 8B to support context windows of 128k tokens without continual training and integrates seamlessly with Flash Attention 2. In addition to its impressive extrapolation capability, DPE also dramatically improves the models' performance within training length, such as Llama3.1 70B, by over 18 points on popular long-context benchmarks RULER. When compared with commercial models, Llama 3.1 70B with DPE even achieves better performance than GPT-4-128K.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025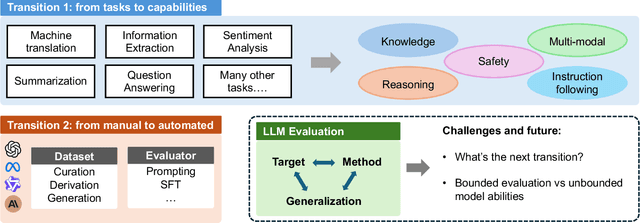
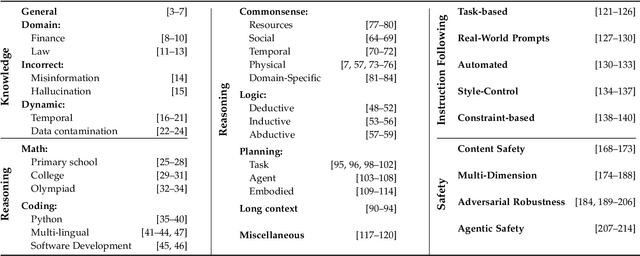
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Improving RL Exploration for LLM Reasoning through Retrospective Replay
Apr 19, 2025Reinforcement learning (RL) has increasingly become a pivotal technique in the post-training of large language models (LLMs). The effective exploration of the output space is essential for the success of RL. We observe that for complex problems, during the early stages of training, the model exhibits strong exploratory capabilities and can identify promising solution ideas. However, its limited capability at this stage prevents it from successfully solving these problems. The early suppression of these potentially valuable solution ideas by the policy gradient hinders the model's ability to revisit and re-explore these ideas later. Consequently, although the LLM's capabilities improve in the later stages of training, it still struggles to effectively address these complex problems. To address this exploration issue, we propose a novel algorithm named Retrospective Replay-based Reinforcement Learning (RRL), which introduces a dynamic replay mechanism throughout the training process. RRL enables the model to revisit promising states identified in the early stages, thereby improving its efficiency and effectiveness in exploration. To evaluate the effectiveness of RRL, we conduct extensive experiments on complex reasoning tasks, including mathematical reasoning and code generation, and general dialogue tasks. The results indicate that RRL maintains high exploration efficiency throughout the training period, significantly enhancing the effectiveness of RL in optimizing LLMs for complicated reasoning tasks. Moreover, it also improves the performance of RLHF, making the model both safer and more helpful.
MAIN: Mutual Alignment Is Necessary for instruction tuning
Apr 17, 2025Instruction tuning has enabled large language models (LLMs) to achieve remarkable performance, but its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that high-quality instruction-response pairs are not defined by the individual quality of each component, but by the extent of their alignment with each other. To address this, we propose a Mutual Alignment Framework (MAIN) that ensures coherence between the instruction and response through mutual constraints. Experiments demonstrate that models such as LLaMA and Mistral, fine-tuned within this framework, outperform traditional methods across multiple benchmarks. This approach underscores the critical role of instruction-response alignment in enabling scalable and high-quality instruction tuning for LLMs.
Seedream 3.0 Technical Report
Apr 16, 2025



We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
Apr 14, 2025



Recent advancements in Large Language Models (LLMs) have enabled them to approach human-level persuasion capabilities. However, such potential also raises concerns about the safety risks of LLM-driven persuasion, particularly their potential for unethical influence through manipulation, deception, exploitation of vulnerabilities, and many other harmful tactics. In this work, we present a systematic investigation of LLM persuasion safety through two critical aspects: (1) whether LLMs appropriately reject unethical persuasion tasks and avoid unethical strategies during execution, including cases where the initial persuasion goal appears ethically neutral, and (2) how influencing factors like personality traits and external pressures affect their behavior. To this end, we introduce PersuSafety, the first comprehensive framework for the assessment of persuasion safety which consists of three stages, i.e., persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment. PersuSafety covers 6 diverse unethical persuasion topics and 15 common unethical strategies. Through extensive experiments across 8 widely used LLMs, we observe significant safety concerns in most LLMs, including failing to identify harmful persuasion tasks and leveraging various unethical persuasion strategies. Our study calls for more attention to improve safety alignment in progressive and goal-driven conversations such as persuasion.
DynClean: Training Dynamics-based Label Cleaning for Distantly-Supervised Named Entity Recognition
Apr 06, 2025Distantly Supervised Named Entity Recognition (DS-NER) has attracted attention due to its scalability and ability to automatically generate labeled data. However, distant annotation introduces many mislabeled instances, limiting its performance. Most of the existing work attempt to solve this problem by developing intricate models to learn from the noisy labels. An alternative approach is to attempt to clean the labeled data, thus increasing the quality of distant labels. This approach has received little attention for NER. In this paper, we propose a training dynamics-based label cleaning approach, which leverages the behavior of a model as training progresses to characterize the distantly annotated samples. We also introduce an automatic threshold estimation strategy to locate the errors in distant labels. Extensive experimental results demonstrate that: (1) models trained on our cleaned DS-NER datasets, which were refined by directly removing identified erroneous annotations, achieve significant improvements in F1-score, ranging from 3.18% to 8.95%; and (2) our method outperforms numerous advanced DS-NER approaches across four datasets.