 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Vision-Language Representation Learning with Off-Diagonal Information
May 17, 2023



Large-scale multi-modal contrastive learning frameworks like CLIP typically require a large amount of image-text samples for training. However, these samples are always collected continuously in real scenarios. This paper discusses the feasibility of continual CLIP training using streaming data. Unlike continual learning based on self-supervised learning methods for pure images, which is empirically robust against catastrophic forgetting, CLIP's performance degeneration in the continual setting is significant and non-neglectable. By analyzing the changes in the model's representation space during continual CLIP training from a spatial geometry perspective, we explore and summarize these spatial variations as Spatial Disorder (SD), which can be divided into Intra-modal Rotation and Inter-modal Deviation. Moreover, we empirically and theoretically demonstrate how SD leads to a performance decline for CLIP on cross-modal retrieval tasks. To alleviate SD, we propose a new continual vision-language representation learning framework Mod-X: Maintain off-diagonal information-matriX. By selectively aligning the off-diagonal information distribution of contrastive matrices, the Mod-X improves the capability of the multi-modal model by maintaining the multi-modal representation space alignment on the old data domain during continuously fitting the new training data domain. Experiments on commonly used datasets with different scales and scopes have demonstrated the effectiveness of our method.
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Segment Anything in 3D with NeRFs
Apr 26, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
Pipeline MoE: A Flexible MoE Implementation with Pipeline Parallelism
Apr 22, 2023



The Mixture of Experts (MoE) model becomes an important choice of large language models nowadays because of its scalability with sublinear computational complexity for training and inference. However, existing MoE models suffer from two critical drawbacks, 1) tremendous inner-node and inter-node communication overhead introduced by all-to-all dispatching and gathering, and 2) limited scalability for the backbone because of the bound data parallel and expert parallel to scale in the expert dimension. In this paper, we systematically analyze these drawbacks in terms of training efficiency in the parallel framework view and propose a novel MoE architecture called Pipeline MoE (PPMoE) to tackle them. PPMoE builds expert parallel incorporating with tensor parallel and replaces communication-intensive all-to-all dispatching and gathering with a simple tensor index slicing and inner-node all-reduce. Besides, it is convenient for PPMoE to integrate pipeline parallel to further scale the backbone due to its flexible parallel architecture. Extensive experiments show that PPMoE not only achieves a more than $1.75\times$ speed up compared to existing MoE architectures but also reaches $90\%$ throughput of its corresponding backbone model that is $20\times$ smaller.
SAILER: Structure-aware Pre-trained Language Model for Legal Case Retrieval
Apr 22, 2023


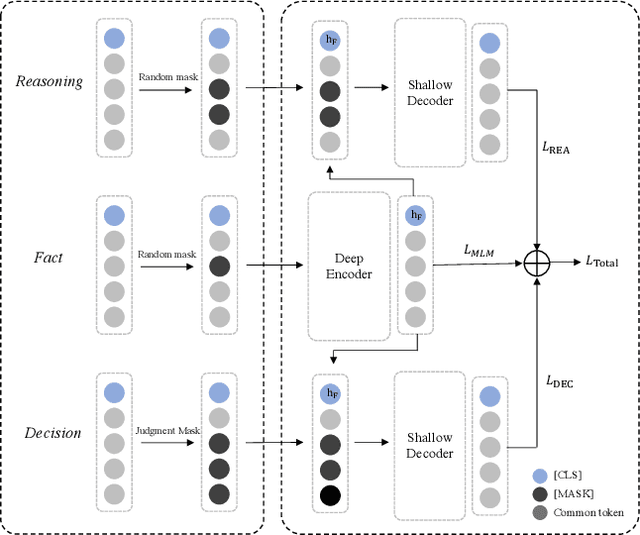
Legal case retrieval, which aims to find relevant cases for a query case, plays a core role in the intelligent legal system. Despite the success that pre-training has achieved in ad-hoc retrieval tasks, effective pre-training strategies for legal case retrieval remain to be explored. Compared with general documents, legal case documents are typically long text sequences with intrinsic logical structures. However, most existing language models have difficulty understanding the long-distance dependencies between different structures. Moreover, in contrast to the general retrieval, the relevance in the legal domain is sensitive to key legal elements. Even subtle differences in key legal elements can significantly affect the judgement of relevance. However, existing pre-trained language models designed for general purposes have not been equipped to handle legal elements. To address these issues, in this paper, we propose SAILER, a new Structure-Aware pre-traIned language model for LEgal case Retrieval. It is highlighted in the following three aspects: (1) SAILER fully utilizes the structural information contained in legal case documents and pays more attention to key legal elements, similar to how legal experts browse legal case documents. (2) SAILER employs an asymmetric encoder-decoder architecture to integrate several different pre-training objectives. In this way, rich semantic information across tasks is encoded into dense vectors. (3) SAILER has powerful discriminative ability, even without any legal annotation data. It can distinguish legal cases with different charges accurately. Extensive experiments over publicly available legal benchmarks demonstrate that our approach can significantly outperform previous state-of-the-art methods in legal case retrieval.
* 10 pages, accepted by SIGIR 2023
Learning Transferable Pedestrian Representation from Multimodal Information Supervision
Apr 12, 2023



Recent researches on unsupervised person re-identification~(reID) have demonstrated that pre-training on unlabeled person images achieves superior performance on downstream reID tasks than pre-training on ImageNet. However, those pre-trained methods are specifically designed for reID and suffer flexible adaption to other pedestrian analysis tasks. In this paper, we propose VAL-PAT, a novel framework that learns transferable representations to enhance various pedestrian analysis tasks with multimodal information. To train our framework, we introduce three learning objectives, \emph{i.e.,} self-supervised contrastive learning, image-text contrastive learning and multi-attribute classification. The self-supervised contrastive learning facilitates the learning of the intrinsic pedestrian properties, while the image-text contrastive learning guides the model to focus on the appearance information of pedestrians.Meanwhile, multi-attribute classification encourages the model to recognize attributes to excavate fine-grained pedestrian information. We first perform pre-training on LUPerson-TA dataset, where each image contains text and attribute annotations, and then transfer the learned representations to various downstream tasks, including person reID, person attribute recognition and text-based person search. Extensive experiments demonstrate that our framework facilitates the learning of general pedestrian representations and thus leads to promising results on various pedestrian analysis tasks.
PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift
Apr 07, 2023Vision Transformer (ViT) has shown great potential for various visual tasks due to its ability to model long-range dependency. However, ViT requires a large amount of computing resource to compute the global self-attention. In this work, we propose a ladder self-attention block with multiple branches and a progressive shift mechanism to develop a light-weight transformer backbone that requires less computing resources (e.g. a relatively small number of parameters and FLOPs), termed Progressive Shift Ladder Transformer (PSLT). First, the ladder self-attention block reduces the computational cost by modelling local self-attention in each branch. In the meanwhile, the progressive shift mechanism is proposed to enlarge the receptive field in the ladder self-attention block by modelling diverse local self-attention for each branch and interacting among these branches. Second, the input feature of the ladder self-attention block is split equally along the channel dimension for each branch, which considerably reduces the computational cost in the ladder self-attention block (with nearly 1/3 the amount of parameters and FLOPs), and the outputs of these branches are then collaborated by a pixel-adaptive fusion. Therefore, the ladder self-attention block with a relatively small number of parameters and FLOPs is capable of modelling long-range interactions. Based on the ladder self-attention block, PSLT performs well on several vision tasks, including image classification, objection detection and person re-identification. On the ImageNet-1k dataset, PSLT achieves a top-1 accuracy of 79.9% with 9.2M parameters and 1.9G FLOPs, which is comparable to several existing models with more than 20M parameters and 4G FLOPs. Code is available at https://isee-ai.cn/wugaojie/PSLT.html.
* Accepted to IEEE Transaction on Pattern Analysis and Machine Intelligence, 2023 (Submission date: 08-Jul-202)
Multi-modal Prompting for Low-Shot Temporal Action Localization
Mar 21, 2023



In this paper, we consider the problem of temporal action localization under low-shot (zero-shot & few-shot) scenario, with the goal of detecting and classifying the action instances from arbitrary categories within some untrimmed videos, even not seen at training time. We adopt a Transformer-based two-stage action localization architecture with class-agnostic action proposal, followed by open-vocabulary classification. We make the following contributions. First, to compensate image-text foundation models with temporal motions, we improve category-agnostic action proposal by explicitly aligning embeddings of optical flows, RGB and texts, which has largely been ignored in existing low-shot methods. Second, to improve open-vocabulary action classification, we construct classifiers with strong discriminative power, i.e., avoid lexical ambiguities. To be specific, we propose to prompt the pre-trained CLIP text encoder either with detailed action descriptions (acquired from large-scale language models), or visually-conditioned instance-specific prompt vectors. Third, we conduct thorough experiments and ablation studies on THUMOS14 and ActivityNet1.3, demonstrating the superior performance of our proposed model, outperforming existing state-of-the-art approaches by one significant margin.
LION: Implicit Vision Prompt Tuning
Mar 17, 2023



Despite recent competitive performance across a range of vision tasks, vision Transformers still have an issue of heavy computational costs. Recently, vision prompt learning has provided an economic solution to this problem without fine-tuning the whole large-scale models. However, the efficiency of existing models are still far from satisfactory due to insertion of extensive prompts blocks and trick prompt designs. In this paper, we propose an efficient vision model named impLicit vIsion prOmpt tuNing (LION), which is motivated by deep implicit models with stable memory costs for various complex tasks. In particular, we merely insect two equilibrium implicit layers in two ends of the pre-trained main backbone with parameters in the backbone frozen. Moreover, we prune the parameters in these two layers according to lottery hypothesis. The performance obtained by our LION are promising on a wide range of datasets. In particular, our LION reduces up to 11.5% of training parameter numbers while obtaining higher performance compared with the state-of-the-art baseline VPT, especially under challenging scenes. Furthermore, we find that our proposed LION had a good generalization performance, making it an easy way to boost transfer learning in the future.
Focus on Your Target: A Dual Teacher-Student Framework for Domain-adaptive Semantic Segmentation
Mar 16, 2023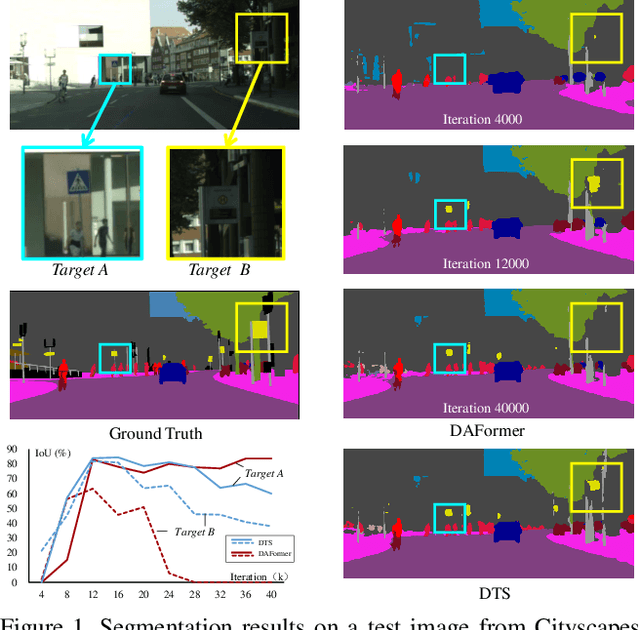
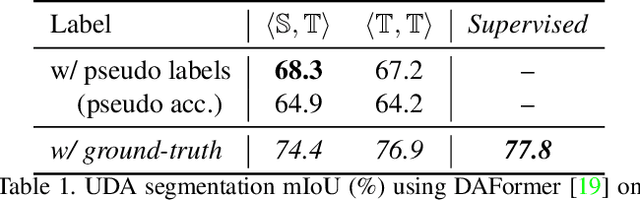
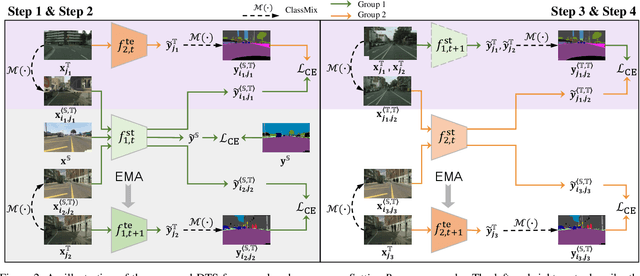
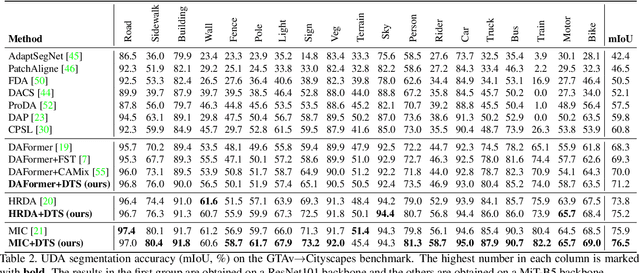
We study unsupervised domain adaptation (UDA) for semantic segmentation. Currently, a popular UDA framework lies in self-training which endows the model with two-fold abilities: (i) learning reliable semantics from the labeled images in the source domain, and (ii) adapting to the target domain via generating pseudo labels on the unlabeled images. We find that, by decreasing/increasing the proportion of training samples from the target domain, the 'learning ability' is strengthened/weakened while the 'adapting ability' goes in the opposite direction, implying a conflict between these two abilities, especially for a single model. To alleviate the issue, we propose a novel dual teacher-student (DTS) framework and equip it with a bidirectional learning strategy. By increasing the proportion of target-domain data, the second teacher-student model learns to 'Focus on Your Target' while the first model is not affected. DTS is easily plugged into existing self-training approaches. In a standard UDA scenario (training on synthetic, labeled data and real, unlabeled data), DTS shows consistent gains over the baselines and sets new state-of-the-art results of 76.5\% and 75.1\% mIoUs on GTAv$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes, respectively.