 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Step: Faster and Better Alignment for Flow Matching Models via Step-aware Advantages
Feb 02, 2026Recent advances in flow matching models, particularly with reinforcement learning (RL), have significantly enhanced human preference alignment in few step text to image generators. However, existing RL based approaches for flow matching models typically rely on numerous denoising steps, while suffering from sparse and imprecise reward signals that often lead to suboptimal alignment. To address these limitations, we propose Temperature Annealed Few step Sampling with Group Relative Policy Optimization (TAFS GRPO), a novel framework for training flow matching text to image models into efficient few step generators well aligned with human preferences. Our method iteratively injects adaptive temporal noise onto the results of one step samples. By repeatedly annealing the model's sampled outputs, it introduces stochasticity into the sampling process while preserving the semantic integrity of each generated image. Moreover, its step aware advantage integration mechanism combines the GRPO to avoid the need for the differentiable of reward function and provide dense and step specific rewards for stable policy optimization. Extensive experiments demonstrate that TAFS GRPO achieves strong performance in few step text to image generation and significantly improves the alignment of generated images with human preferences. The code and models of this work will be available to facilitate further research.
E-CGL: An Efficient Continual Graph Learner
Aug 18, 2024Continual learning has emerged as a crucial paradigm for learning from sequential data while preserving previous knowledge. In the realm of continual graph learning, where graphs continuously evolve based on streaming graph data, continual graph learning presents unique challenges that require adaptive and efficient graph learning methods in addition to the problem of catastrophic forgetting. The first challenge arises from the interdependencies between different graph data, where previous graphs can influence new data distributions. The second challenge lies in the efficiency concern when dealing with large graphs. To addresses these two problems, we produce an Efficient Continual Graph Learner (E-CGL) in this paper. We tackle the interdependencies issue by demonstrating the effectiveness of replay strategies and introducing a combined sampling strategy that considers both node importance and diversity. To overcome the limitation of efficiency, E-CGL leverages a simple yet effective MLP model that shares weights with a GCN during training, achieving acceleration by circumventing the computationally expensive message passing process. Our method comprehensively surpasses nine baselines on four graph continual learning datasets under two settings, meanwhile E-CGL largely reduces the catastrophic forgetting problem down to an average of -1.1%. Additionally, E-CGL achieves an average of 15.83x training time acceleration and 4.89x inference time acceleration across the four datasets. These results indicate that E-CGL not only effectively manages the correlation between different graph data during continual training but also enhances the efficiency of continual learning on large graphs. The code is publicly available at https://github.com/aubreygjh/E-CGL.
Degeneration-Tuning: Using Scrambled Grid shield Unwanted Concepts from Stable Diffusion
Aug 08, 2023



Owing to the unrestricted nature of the content in the training data, large text-to-image diffusion models, such as Stable Diffusion (SD), are capable of generating images with potentially copyrighted or dangerous content based on corresponding textual concepts information. This includes specific intellectual property (IP), human faces, and various artistic styles. However, Negative Prompt, a widely used method for content removal, frequently fails to conceal this content due to inherent limitations in its inference logic. In this work, we propose a novel strategy named \textbf{Degeneration-Tuning (DT)} to shield contents of unwanted concepts from SD weights. By utilizing Scrambled Grid to reconstruct the correlation between undesired concepts and their corresponding image domain, we guide SD to generate meaningless content when such textual concepts are provided as input. As this adaptation occurs at the level of the model's weights, the SD, after DT, can be grafted onto other conditional diffusion frameworks like ControlNet to shield unwanted concepts. In addition to qualitatively showcasing the effectiveness of our DT method in protecting various types of concepts, a quantitative comparison of the SD before and after DT indicates that the DT method does not significantly impact the generative quality of other contents. The FID and IS scores of the model on COCO-30K exhibit only minor changes after DT, shifting from 12.61 and 39.20 to 13.04 and 38.25, respectively, which clearly outperforms the previous methods.
Continual Vision-Language Representation Learning with Off-Diagonal Information
May 17, 2023



Large-scale multi-modal contrastive learning frameworks like CLIP typically require a large amount of image-text samples for training. However, these samples are always collected continuously in real scenarios. This paper discusses the feasibility of continual CLIP training using streaming data. Unlike continual learning based on self-supervised learning methods for pure images, which is empirically robust against catastrophic forgetting, CLIP's performance degeneration in the continual setting is significant and non-neglectable. By analyzing the changes in the model's representation space during continual CLIP training from a spatial geometry perspective, we explore and summarize these spatial variations as Spatial Disorder (SD), which can be divided into Intra-modal Rotation and Inter-modal Deviation. Moreover, we empirically and theoretically demonstrate how SD leads to a performance decline for CLIP on cross-modal retrieval tasks. To alleviate SD, we propose a new continual vision-language representation learning framework Mod-X: Maintain off-diagonal information-matriX. By selectively aligning the off-diagonal information distribution of contrastive matrices, the Mod-X improves the capability of the multi-modal model by maintaining the multi-modal representation space alignment on the old data domain during continuously fitting the new training data domain. Experiments on commonly used datasets with different scales and scopes have demonstrated the effectiveness of our method.
Self-Supervised Class Incremental Learning
Nov 18, 2021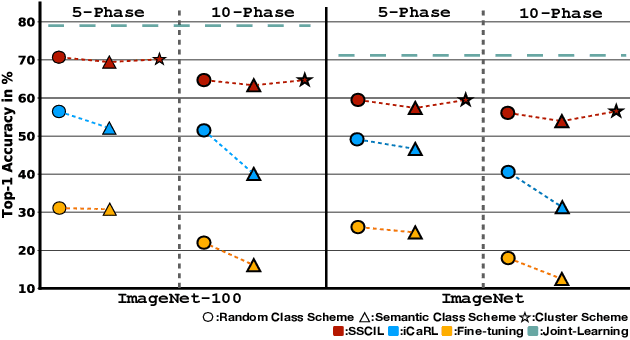
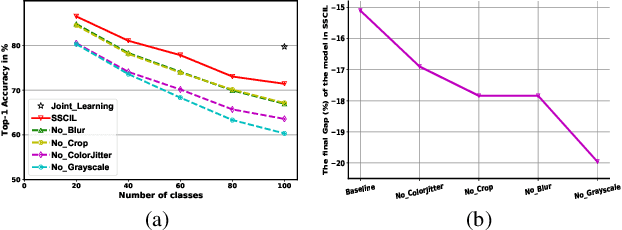
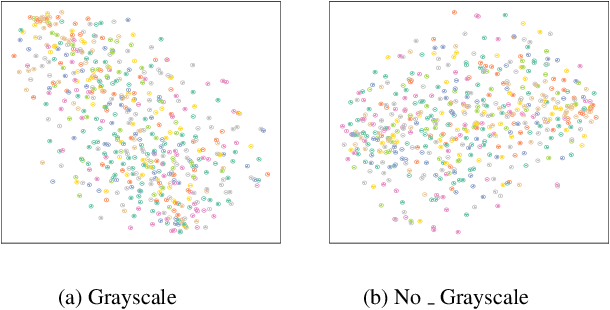
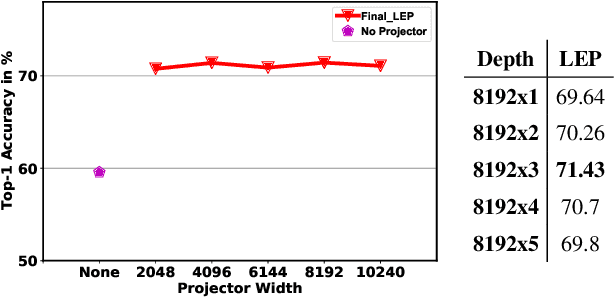
Existing Class Incremental Learning (CIL) methods are based on a supervised classification framework sensitive to data labels. When updating them based on the new class data, they suffer from catastrophic forgetting: the model cannot discern old class data clearly from the new. In this paper, we explore the performance of Self-Supervised representation learning in Class Incremental Learning (SSCIL) for the first time, which discards data labels and the model's classifiers. To comprehensively discuss the difference in performance between supervised and self-supervised methods in CIL, we set up three different class incremental schemes: Random Class Scheme, Semantic Class Scheme, and Cluster Scheme, to simulate various class incremental learning scenarios. Besides, we propose Linear Evaluation Protocol (LEP) and Generalization Evaluation Protocol (GEP) to metric the model's representation classification ability and generalization in CIL. Our experiments (on ImageNet-100 and ImageNet) show that SSCIL has better anti-forgetting ability and robustness than supervised strategies in CIL. To understand what alleviates the catastrophic forgetting in SSCIL, we study the major components of SSCIL and conclude that (1) the composition of different data augmentation improves the quality of the model's representation and the \textit{Grayscale} operation reduces the system noise of data augmentation in SSCIL. (2) the projector, like a buffer, reduces unnecessary parameter updates of the model in SSCIL and increases the robustness of the model. Although the performance of SSCIL is significantly higher than supervised methods in CIL, there is still an apparent gap with joint learning. Our exploration gives a baseline of self-supervised class incremental learning on large-scale datasets and contributes some forward strategies for mitigating the catastrophic forgetting in CIL.
Alleviate Representation Overlapping in Class Incremental Learning by Contrastive Class Concentration
Jul 30, 2021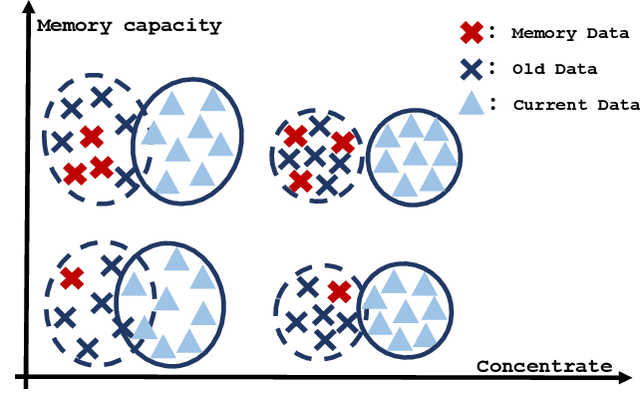
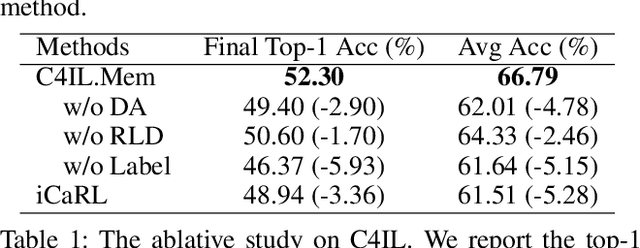
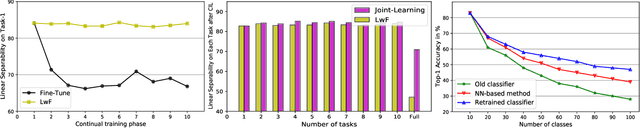
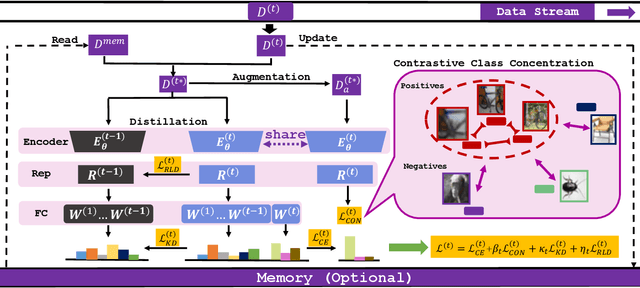
The challenge of the Class Incremental Learning~(CIL) lies in difficulty for a learner to discern the old classes' data from the new as no previous classes' data is preserved. In this paper, we reveal three causes for catastrophic forgetting at the representational level, namely, representation forgetting, representation overlapping, and classifier deviation. Based on the observation above, we propose a new CIL framework, Contrastive Class Concentration for CIL (C4IL) to alleviate the phenomenon of representation overlapping that works in both memory-based and memory-free methods. Our framework leverages the class concentration effect of contrastive representation learning, therefore yielding a representation distribution with better intra-class compatibility and inter-class separability. Quantitative experiments showcase the effectiveness of our framework: it outperforms the baseline methods by 5% in terms of the average and top-1 accuracy in 10-phase and 20-phase CIL. Qualitative results also demonstrate that our method generates a more compact representation distribution that alleviates the overlapping problem.