 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiViT: Hierarchical Vision Transformer Meets Masked Image Modeling
May 30, 2022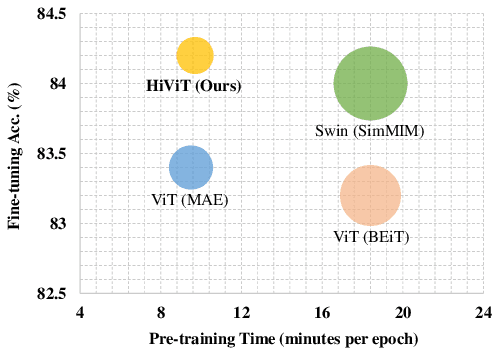

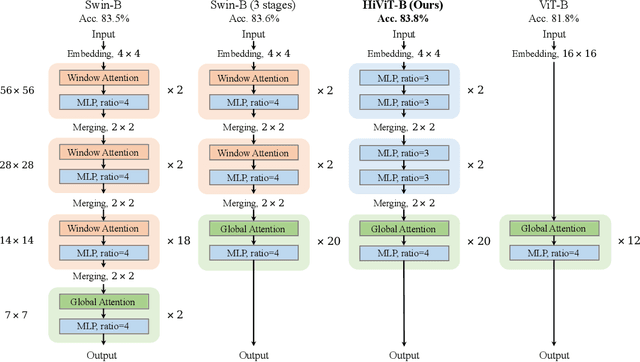
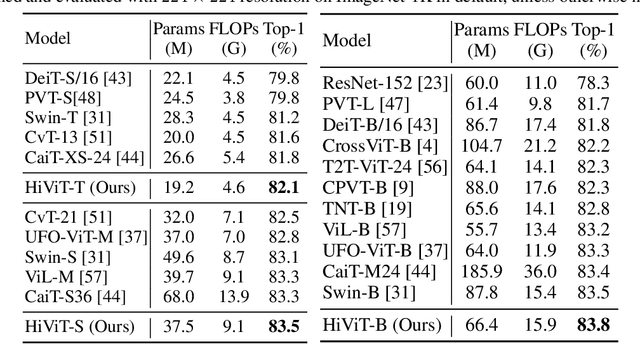
Recently, masked image modeling (MIM) has offered a new methodology of self-supervised pre-training of vision transformers. A key idea of efficient implementation is to discard the masked image patches (or tokens) throughout the target network (encoder), which requires the encoder to be a plain vision transformer (e.g., ViT), albeit hierarchical vision transformers (e.g., Swin Transformer) have potentially better properties in formulating vision inputs. In this paper, we offer a new design of hierarchical vision transformers named HiViT (short for Hierarchical ViT) that enjoys both high efficiency and good performance in MIM. The key is to remove the unnecessary "local inter-unit operations", deriving structurally simple hierarchical vision transformers in which mask-units can be serialized like plain vision transformers. For this purpose, we start with Swin Transformer and (i) set the masking unit size to be the token size in the main stage of Swin Transformer, (ii) switch off inter-unit self-attentions before the main stage, and (iii) eliminate all operations after the main stage. Empirical studies demonstrate the advantageous performance of HiViT in terms of fully-supervised, self-supervised, and transfer learning. In particular, in running MAE on ImageNet-1K, HiViT-B reports a +0.6% accuracy gain over ViT-B and a 1.9$\times$ speed-up over Swin-B, and the performance gain generalizes to downstream tasks of detection and segmentation. Code will be made publicly available.
GraphQ IR: Unifying Semantic Parsing of Graph Query Language with Intermediate Representation
May 24, 2022
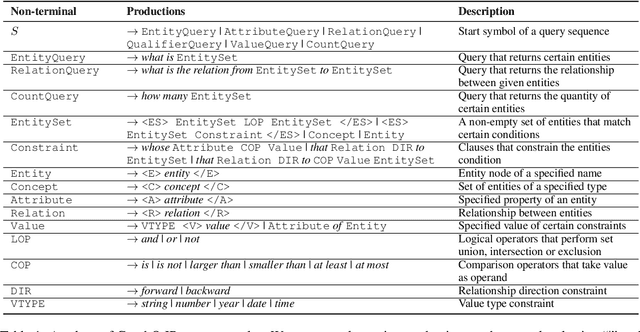
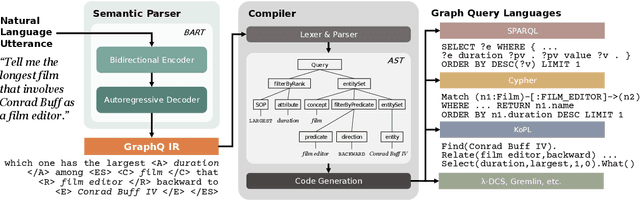
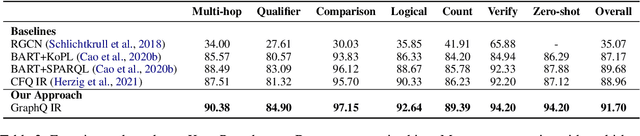
Subject to the semantic gap lying between natural and formal language, neural semantic parsing is typically bottlenecked by the paucity and imbalance of data. In this paper, we propose a unified intermediate representation (IR) for graph query languages, namely GraphQ IR. With the IR's natural-language-like representation that bridges the semantic gap and its formally defined syntax that maintains the graph structure, neural semantic parser can more effectively convert user queries into our GraphQ IR, which can be later automatically compiled into different downstream graph query languages. Extensive experiments show that our approach can consistently achieve state-of-the-art performance on benchmarks KQA Pro, Overnight and MetaQA. Evaluations under compositional generalization and few-shot learning settings also validate the promising generalization ability of GraphQ IR with at most 11% accuracy improvement.
Domain-Agnostic Prior for Transfer Semantic Segmentation
Apr 20, 2022
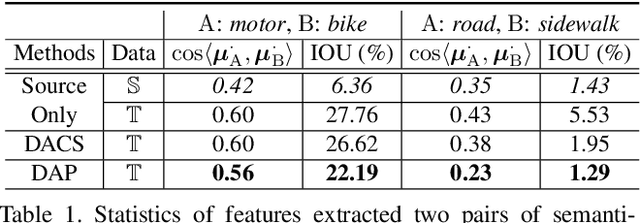
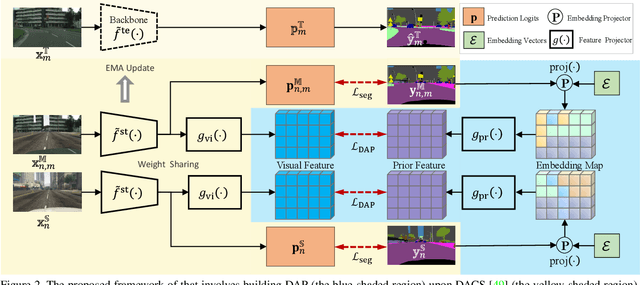
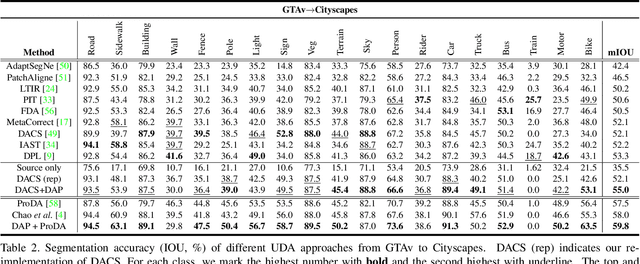
Unsupervised domain adaptation (UDA) is an important topic in the computer vision community. The key difficulty lies in defining a common property between the source and target domains so that the source-domain features can align with the target-domain semantics. In this paper, we present a simple and effective mechanism that regularizes cross-domain representation learning with a domain-agnostic prior (DAP) that constrains the features extracted from source and target domains to align with a domain-agnostic space. In practice, this is easily implemented as an extra loss term that requires a little extra costs. In the standard evaluation protocol of transferring synthesized data to real data, we validate the effectiveness of different types of DAP, especially that borrowed from a text embedding model that shows favorable performance beyond the state-of-the-art UDA approaches in terms of segmentation accuracy. Our research reveals that UDA benefits much from better proxies, possibly from other data modalities.
CenterNet++ for Object Detection
Apr 18, 2022

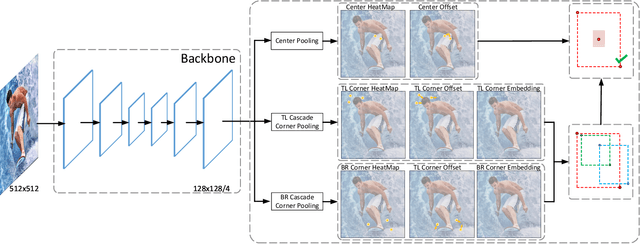
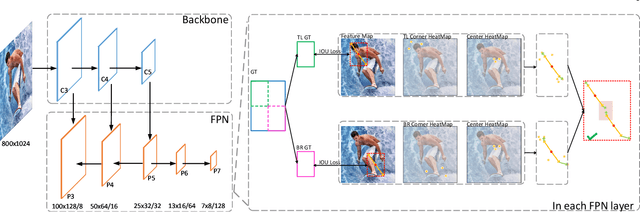
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
HyperDet3D: Learning a Scene-conditioned 3D Object Detector
Apr 12, 2022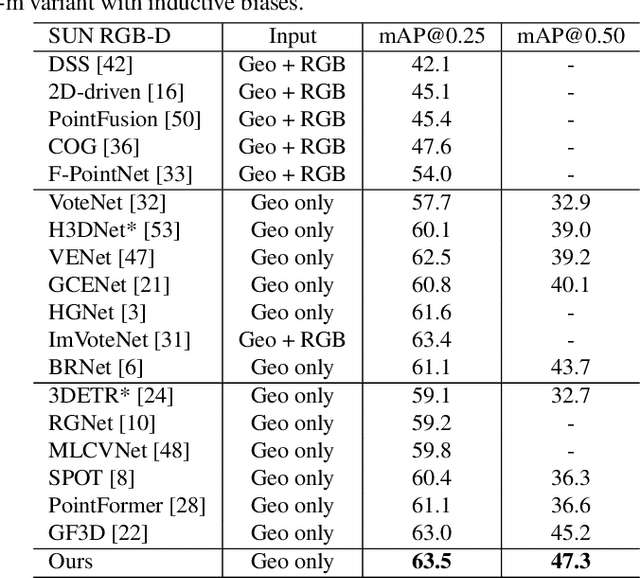
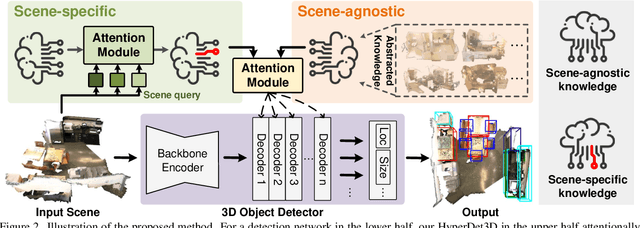

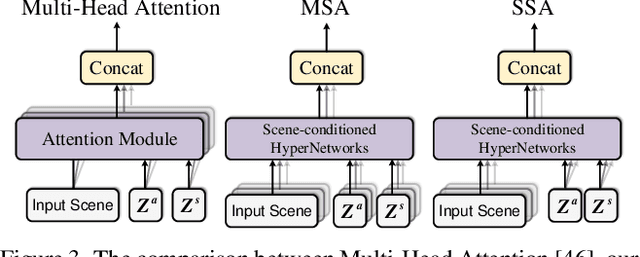
A bathtub in a library, a sink in an office, a bed in a laundry room -- the counter-intuition suggests that scene provides important prior knowledge for 3D object detection, which instructs to eliminate the ambiguous detection of similar objects. In this paper, we propose HyperDet3D to explore scene-conditioned prior knowledge for 3D object detection. Existing methods strive for better representation of local elements and their relations without scene-conditioned knowledge, which may cause ambiguity merely based on the understanding of individual points and object candidates. Instead, HyperDet3D simultaneously learns scene-agnostic embeddings and scene-specific knowledge through scene-conditioned hypernetworks. More specifically, our HyperDet3D not only explores the sharable abstracts from various 3D scenes, but also adapts the detector to the given scene at test time. We propose a discriminative Multi-head Scene-specific Attention (MSA) module to dynamically control the layer parameters of the detector conditioned on the fusion of scene-conditioned knowledge. Our HyperDet3D achieves state-of-the-art results on the 3D object detection benchmark of the ScanNet and SUN RGB-D datasets. Moreover, through cross-dataset evaluation, we show the acquired scene-conditioned prior knowledge still takes effect when facing 3D scenes with domain gap.
Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
Mar 27, 2022


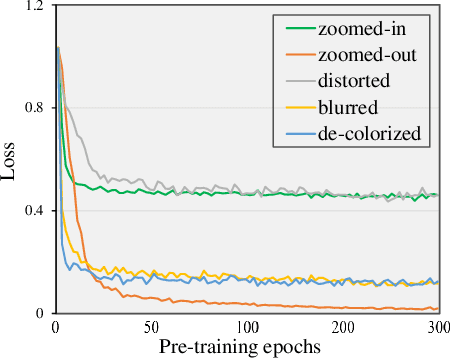
The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.
DATA: Domain-Aware and Task-Aware Self-supervised Learning
Mar 25, 2022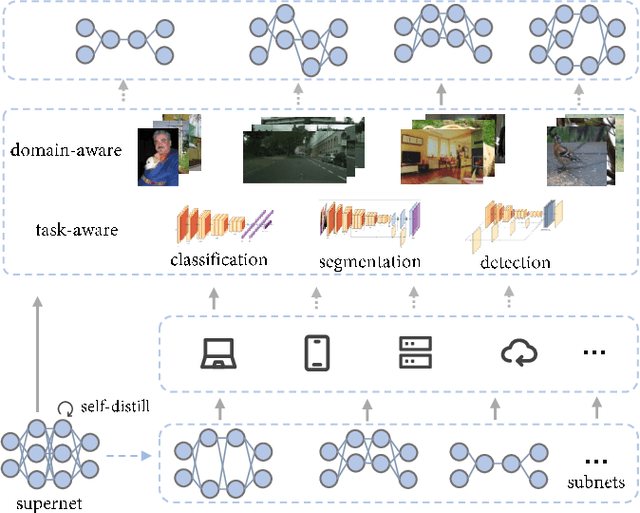
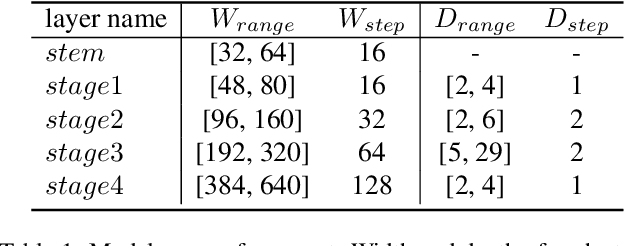
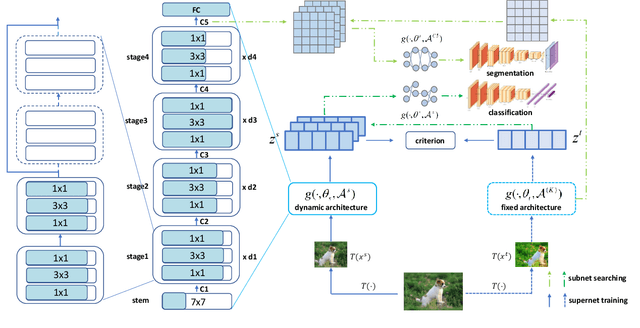
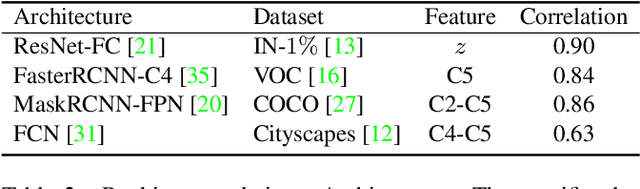
The paradigm of training models on massive data without label through self-supervised learning (SSL) and finetuning on many downstream tasks has become a trend recently. However, due to the high training costs and the unconsciousness of downstream usages, most self-supervised learning methods lack the capability to correspond to the diversities of downstream scenarios, as there are various data domains, different vision tasks and latency constraints on models. Neural architecture search (NAS) is one universally acknowledged fashion to conquer the issues above, but applying NAS on SSL seems impossible as there is no label or metric provided for judging model selection. In this paper, we present DATA, a simple yet effective NAS approach specialized for SSL that provides Domain-Aware and Task-Aware pre-training. Specifically, we (i) train a supernet which could be deemed as a set of millions of networks covering a wide range of model scales without any label, (ii) propose a flexible searching mechanism compatible with SSL that enables finding networks of different computation costs, for various downstream vision tasks and data domains without explicit metric provided. Instantiated With MoCo v2, our method achieves promising results across a wide range of computation costs on downstream tasks, including image classification, object detection and semantic segmentation. DATA is orthogonal to most existing SSL methods and endows them the ability of customization on downstream needs. Extensive experiments on other SSL methods demonstrate the generalizability of the proposed method. Code is released at https://github.com/GAIA-vision/GAIA-ssl
TAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022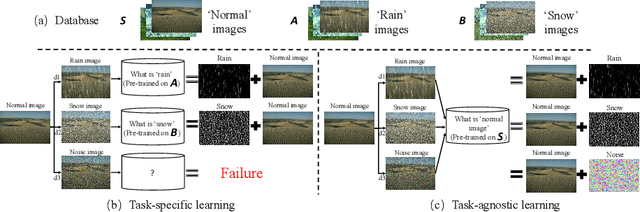

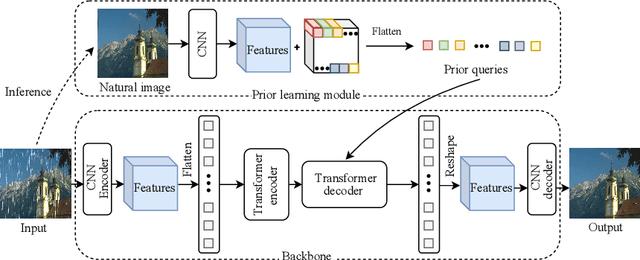

Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
Deep Class Incremental Learning from Decentralized Data
Mar 11, 2022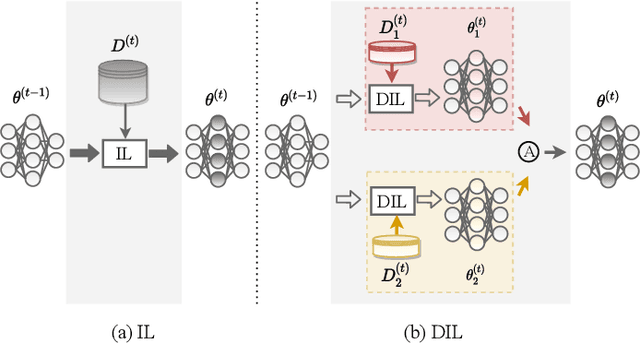

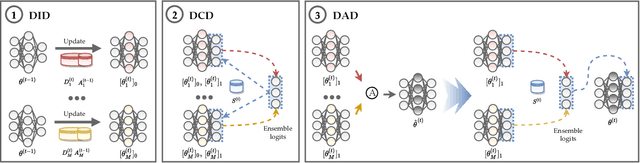
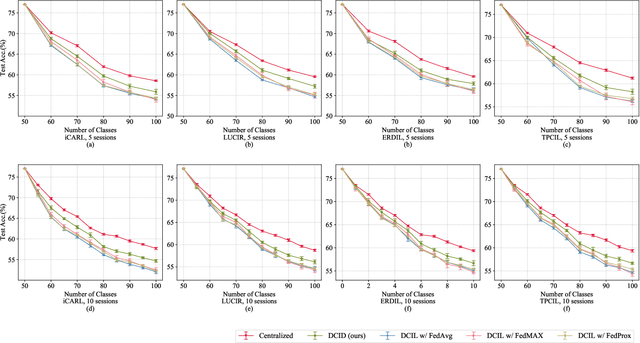
In this paper, we focus on a new and challenging decentralized machine learning paradigm in which there are continuous inflows of data to be addressed and the data are stored in multiple repositories. We initiate the study of data decentralized class-incremental learning (DCIL) by making the following contributions. Firstly, we formulate the DCIL problem and develop the experimental protocol. Secondly, we introduce a paradigm to create a basic decentralized counterpart of typical (centralized) class-incremental learning approaches, and as a result, establish a benchmark for the DCIL study. Thirdly, we further propose a Decentralized Composite knowledge Incremental Distillation framework (DCID) to transfer knowledge from historical models and multiple local sites to the general model continually. DCID consists of three main components namely local class-incremental learning, collaborated knowledge distillation among local models, and aggregated knowledge distillation from local models to the general one. We comprehensively investigate our DCID framework by using different implementations of the three components. Extensive experimental results demonstrate the effectiveness of our DCID framework. The codes of the baseline methods and the proposed DCIL will be released at https://github.com/zxxxxh/DCIL.
MVP: Multimodality-guided Visual Pre-training
Mar 10, 2022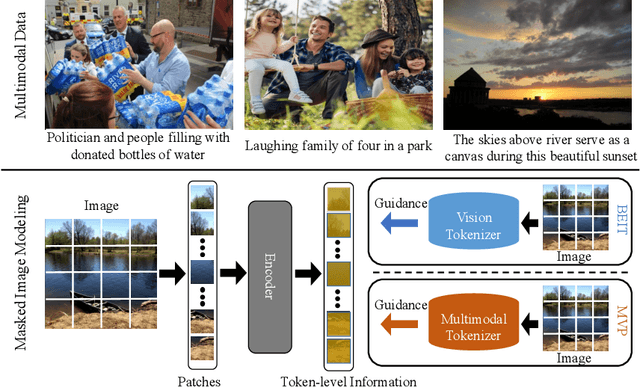
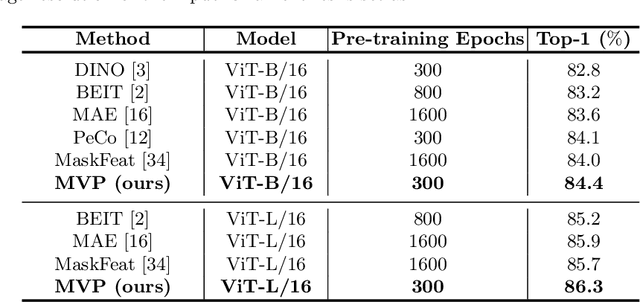
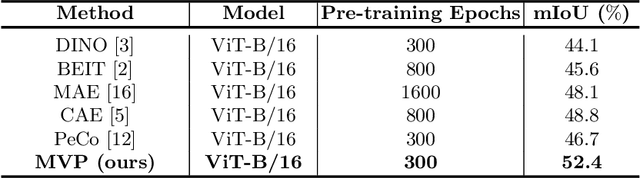
Recently, masked image modeling (MIM) has become a promising direction for visual pre-training. In the context of vision transformers, MIM learns effective visual representation by aligning the token-level features with a pre-defined space (e.g., BEIT used a d-VAE trained on a large image corpus as the tokenizer). In this paper, we go one step further by introducing guidance from other modalities and validating that such additional knowledge leads to impressive gains for visual pre-training. The proposed approach is named Multimodality-guided Visual Pre-training (MVP), in which we replace the tokenizer with the vision branch of CLIP, a vision-language model pre-trained on 400 million image-text pairs. We demonstrate the effectiveness of MVP by performing standard experiments, i.e., pre-training the ViT models on ImageNet and fine-tuning them on a series of downstream visual recognition tasks. In particular, pre-training ViT-Base/16 for 300 epochs, MVP reports a 52.4% mIoU on ADE20K, surpassing BEIT (the baseline and previous state-of-the-art) with an impressive margin of 6.8%.