 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neuro-AI Interface for Evaluating Generative Adversarial Networks
Apr 06, 2020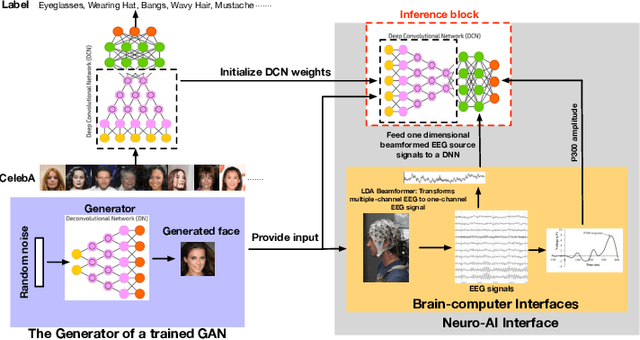
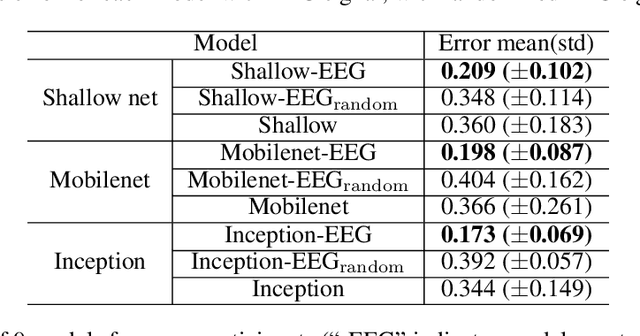
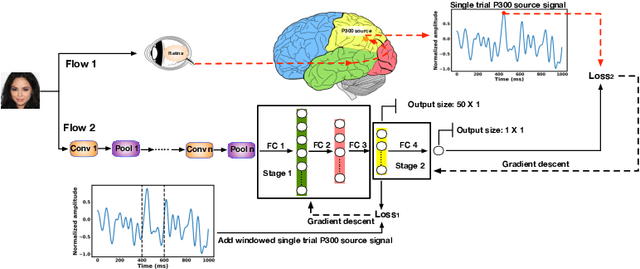
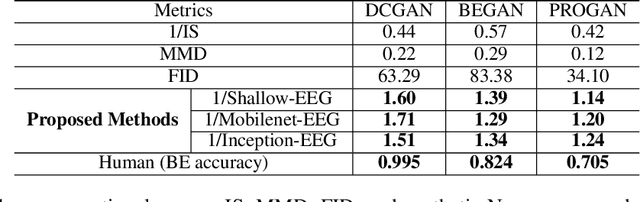
Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect human perception of image quality. In this work, we introduce an evaluation metric called Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performance to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network (CNN) based neuro-AI interface is proposed to predict Neuroscore from GAN-generated images directly without the need for neural responses. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model. Codes and data can be referred at this link: https://github.com/villawang/Neuro-AI-Interface.
A Spectral Nonlocal Block for Neural Networks
Nov 27, 2019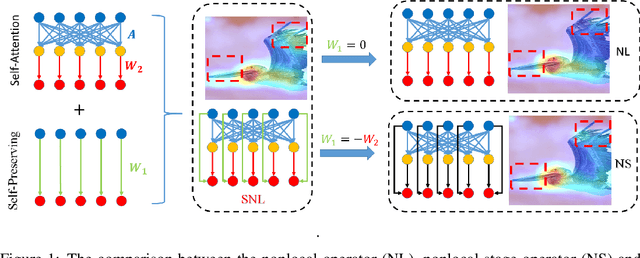
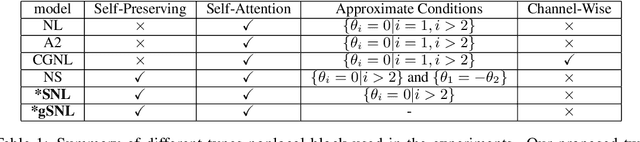
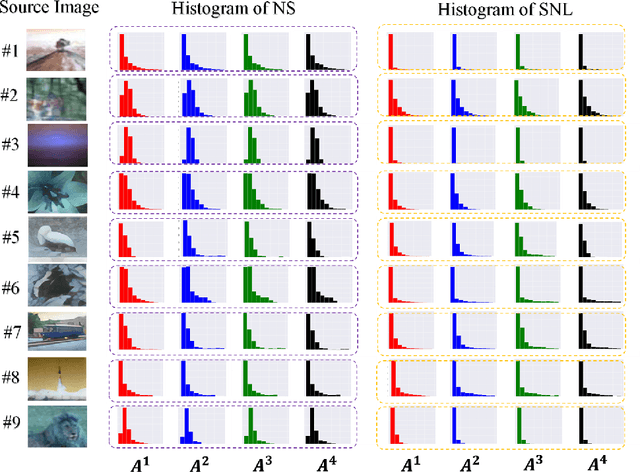
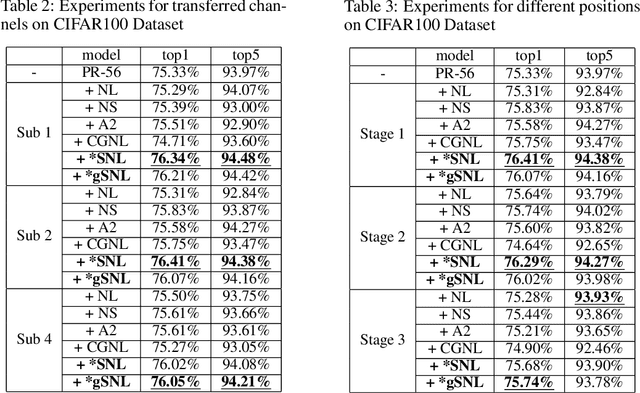
The nonlocal network is designed for capturing long-range spatial-temporal dependencies in several computer vision tasks. Although having shown excellent performances, it needs an elaborate preparation for both the number and position of the building blocks. In this paper, we propose a new formulation of the nonlocal block and interpret it from the general graph signal processing perspective, where we view it as a fully-connected graph filter approximated by Chebyshev polynomials. The proposed nonlocal block is more efficient and robust, which is a generalized form of existing nonlocal blocks (e.g. nonlocal block, nonlocal stage). Moreover, we give the stable hypothesis and show that the steady-state of the deeper nonlocal structure should meet with it. Based on the stable hypothesis, a full-order approximation of the nonlocal block is derived for consecutive connections. Experimental results illustrate the clear-cut improvement and practical applicability of the generalized nonlocal block on both image and video classification tasks.
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019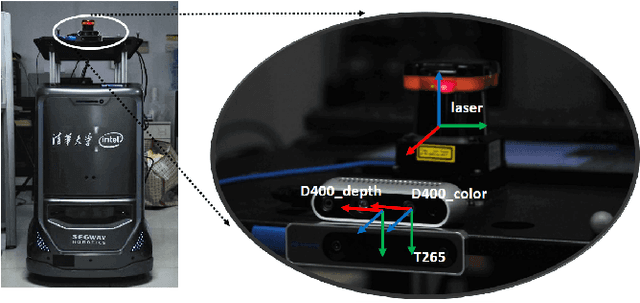


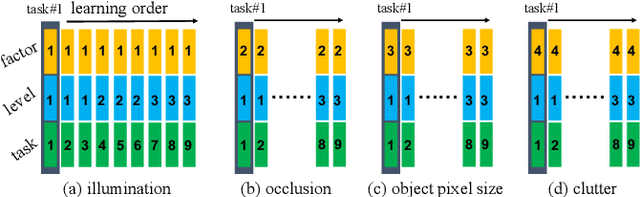
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
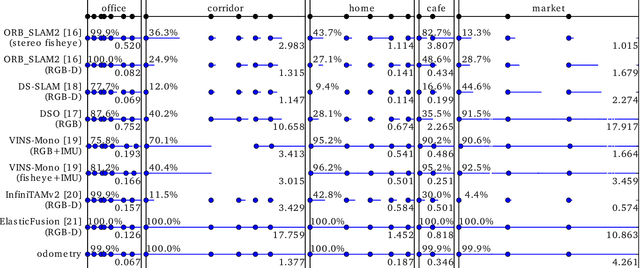
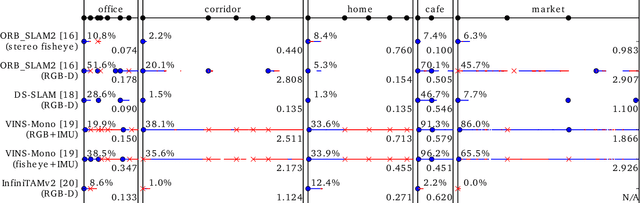
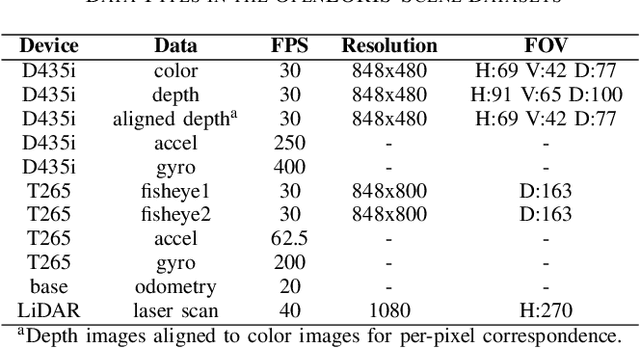
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.
Stochastic trajectory prediction with social graph network
Jul 24, 2019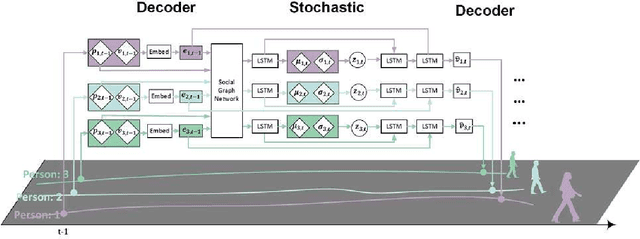
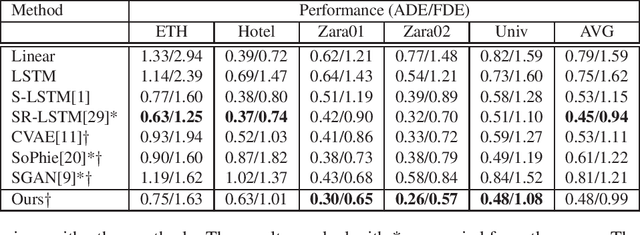
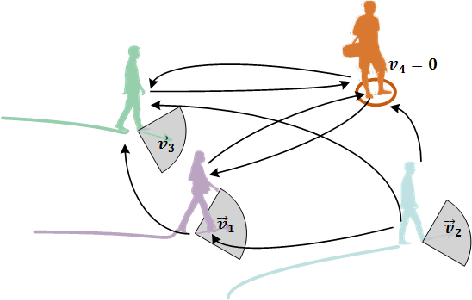
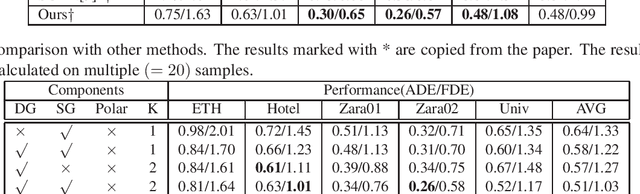
Pedestrian trajectory prediction is a challenging task because of the complexity of real-world human social behaviors and uncertainty of the future motion. For the first issue, existing methods adopt fully connected topology for modeling the social behaviors, while ignoring non-symmetric pairwise relationships. To effectively capture social behaviors of relevant pedestrians, we utilize a directed social graph which is dynamically constructed on timely location and speed direction. Based on the social graph, we further propose a network to collect social effects and accumulate with individual representation, in order to generate destination-oriented and social-aware representations. For the second issue, instead of modeling the uncertainty of the entire future as a whole, we utilize a temporal stochastic method for sequentially learning a prior model of uncertainty during social interactions. The prediction on the next step is then generated by sampling on the prior model and progressively decoding with a hierarchical LSTMs. Experimental results on two public datasets show the effectiveness of our method, especially when predicting trajectories in very crowded scenes.
Neural Dynamics Discovery via Gaussian Process Recurrent Neural Networks
Jul 01, 2019
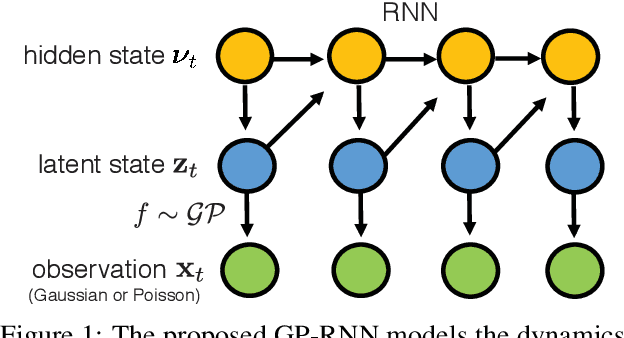
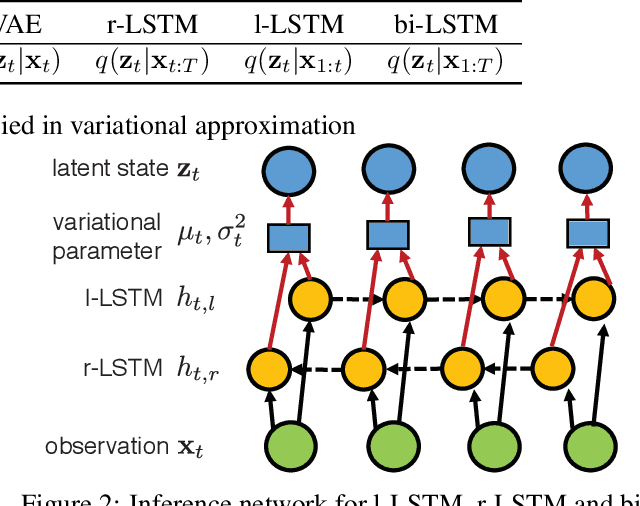

Latent dynamics discovery is challenging in extracting complex dynamics from high-dimensional noisy neural data. Many dimensionality reduction methods have been widely adopted to extract low-dimensional, smooth and time-evolving latent trajectories. However, simple state transition structures, linear embedding assumptions, or inflexible inference networks impede the accurate recovery of dynamic portraits. In this paper, we propose a novel latent dynamic model that is capable of capturing nonlinear, non-Markovian, long short-term time-dependent dynamics via recurrent neural networks and tackling complex nonlinear embedding via non-parametric Gaussian process. Due to the complexity and intractability of the model and its inference, we also provide a powerful inference network with bi-directional long short-term memory networks that encode both past and future information into posterior distributions. In the experiment, we show that our model outperforms other state-of-the-art methods in reconstructing insightful latent dynamics from both simulated and experimental neural datasets with either Gaussian or Poisson observations, especially in the low-sample scenario. Our codes and additional materials are available at https://github.com/sheqi/GP-RNN_UAI2019.
Generative Adversarial Networks: A Survey and Taxonomy
Jun 14, 2019
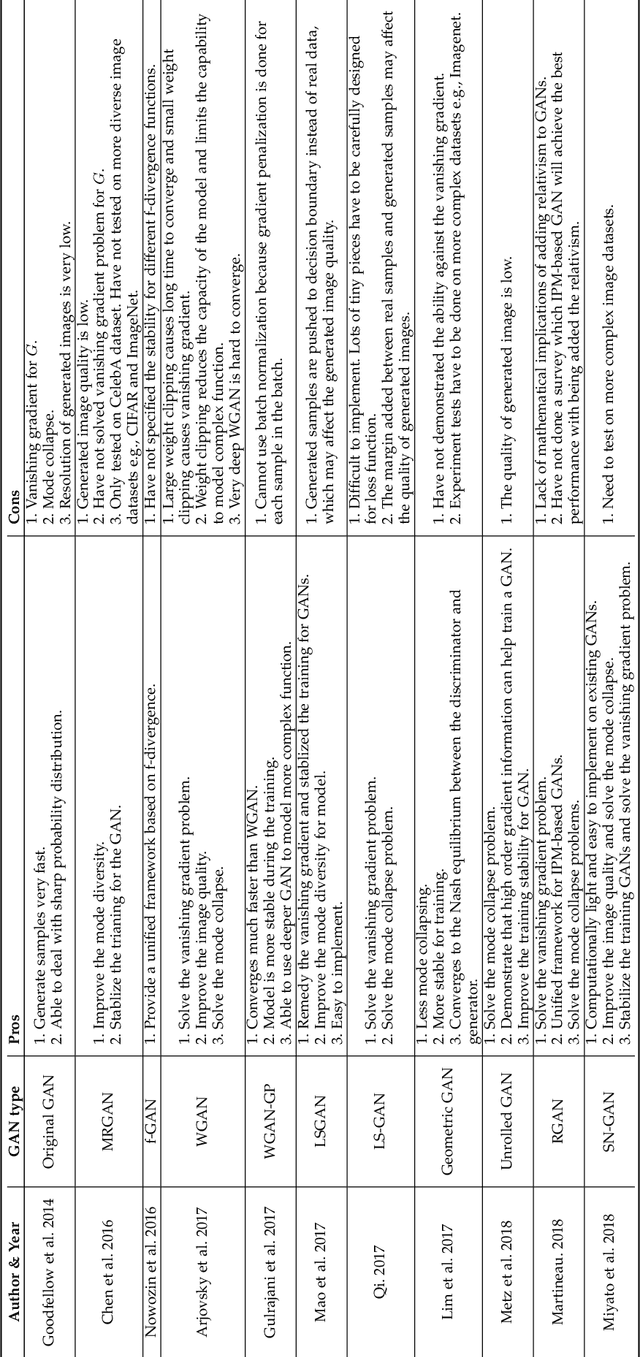
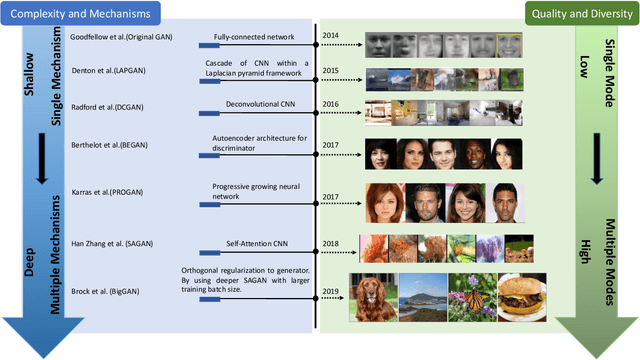
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in the computer vision field, applying GANs to real-world problems still poses significant challenges, three of which we focus on here: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Through an in-depth review of GAN-related research in the literature, we provide an account of the architecture-variants and loss-variants, which have been proposed to handle these three challenges from two perspectives. We propose loss-variants and architecture-variants for classifying the most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented to date, none have focused on the review of GAN-variants based on their handling the challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.
Neuroscore: A Brain-inspired Evaluation Metric for Generative Adversarial Networks
May 10, 2019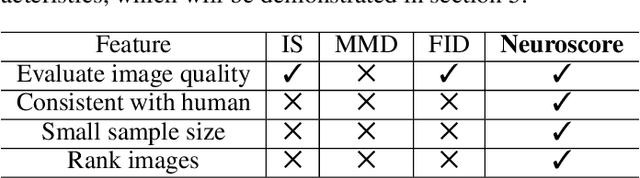
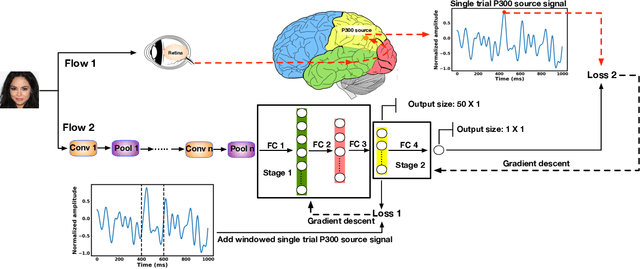
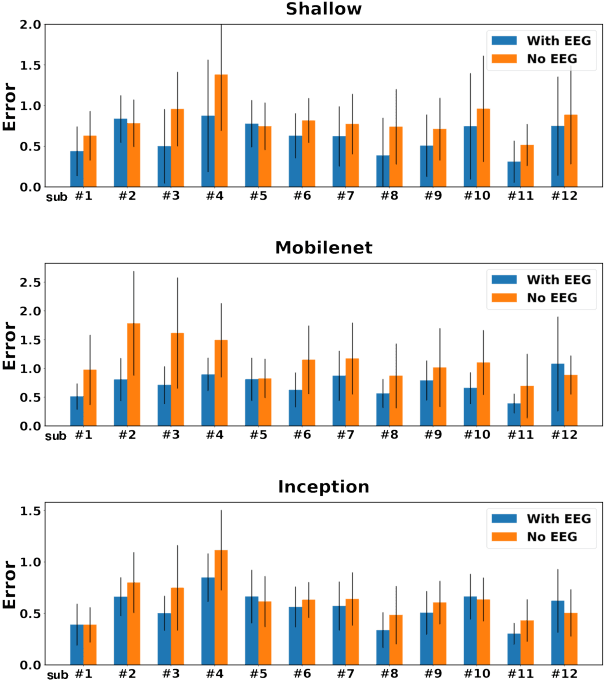

Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. Arguably the most striking results have been in the area of image synthesis. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect the human perception of the image quality. In this work, we introduce an evaluation metric we call Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performances to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network based brain-inspired framework is also proposed to predict Neuroscore from GAN-generated images. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model.
Network Modeling of Short Over-Dispersed Spike-Counts: A Hierarchical Parametric Empirical Bayes Framework
May 28, 2018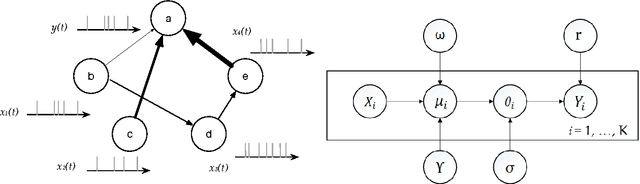

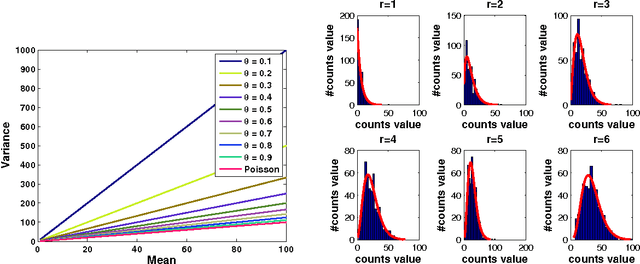
Accurate statistical models of neural spike responses can characterize the information carried by neural populations. Yet, challenges in recording at the level of individual neurons commonly results in relatively limited samples of spike counts, which can lead to model overfitting. Moreover, current models assume spike counts to be Poisson-distributed, which ignores the fact that many neurons demonstrate over-dispersed spiking behavior. The Negative Binomial Generalized Linear Model (NB-GLM) provides a powerful tool for modeling over-dispersed spike counts. However, maximum likelihood based standard NB-GLM leads to unstable and inaccurate parameter estimations. Thus, we propose a hierarchical parametric empirical Bayes method for estimating the parameters of the NB-GLM. Our method integrates Generalized Linear Models (GLMs) and empirical Bayes theory to: (1) effectively capture over-dispersion nature of spike counts from retinal ganglion neural responses; (2) significantly reduce mean square error of parameter estimations when compared to maximum likelihood based method for NB-GLMs; (3) provide an efficient alternative to fully Bayesian inference with low computational cost for hierarchical models; and (4) give insightful findings on both neural interactions and spiking behaviors of real retina cells. We apply our approach to study both simulated data and experimental neural data from the retina. The simulation results indicate the new framework can efficiently and accurately retrieve the weights of functional connections among neural populations and predict mean spike counts. The results from the retinal datasets demonstrate the proposed method outperforms both standard Poisson and Negative Binomial GLMs in terms of the predictive log-likelihood of held-out data.
NDDR-CNN: Layer-wise Feature Fusing in Multi-Task CNN by Neural Discriminative Dimensionality Reduction
Mar 13, 2018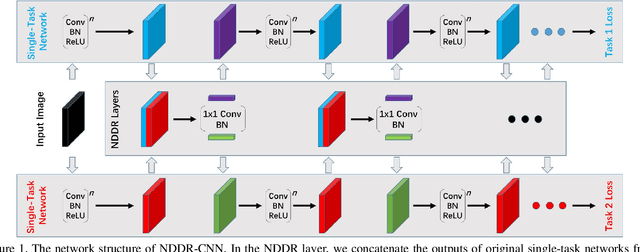
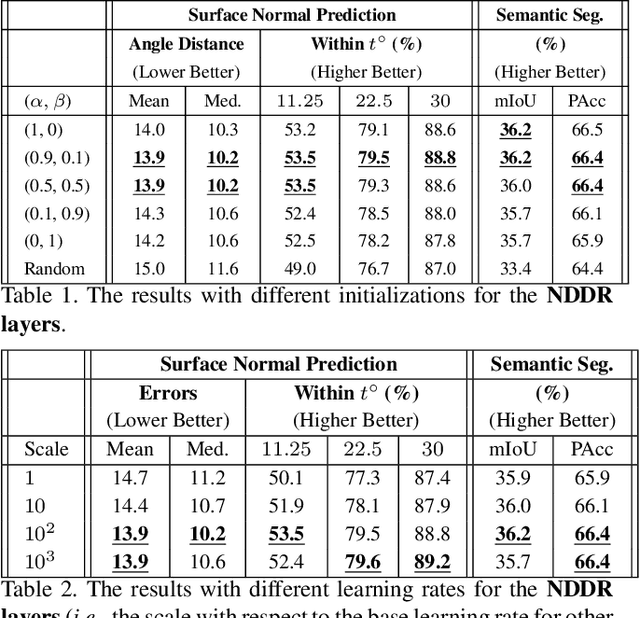
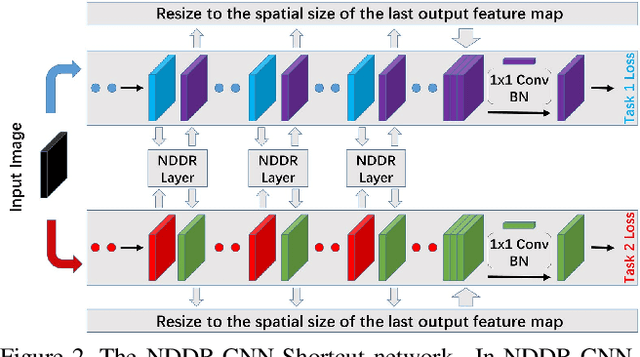
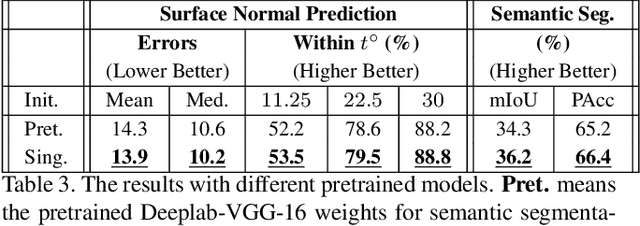
State-of-the-art Convolutional Neural Network (CNN) benefits much from multi-task learning (MTL), which learns multiple related tasks simultaneously to obtain shared or mutually related representations for different tasks. The most widely used MTL CNN structure is based on an empirical or heuristic split on a specific layer (e.g., the last convolutional layer) to minimize multiple task-specific losses. However, this heuristic sharing/splitting strategy may be harmful to the final performance of one or multiple tasks. In this paper, we propose a novel CNN structure for MTL, which enables automatic feature fusing at every layer. Specifically, we first concatenate features from different tasks according to their channel dimension, and then formulate the feature fusing problem as discriminative dimensionality reduction. We show that this discriminative dimensionality reduction can be fulfilled by 1x1 Convolution, Batch Normalization, and Weight Decay in one CNN, which we refer to as Neural Discriminative Dimensionality Reduction (NDDR). We perform detailed ablation analysis for different configurations in training the proposed NDDR-CNN network. The experiments carried out on different network structures and different task sets demonstrate the promising performance and desirable generalizability of our proposed method.