 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Q-attention with Learned Path Ranking
Apr 04, 2022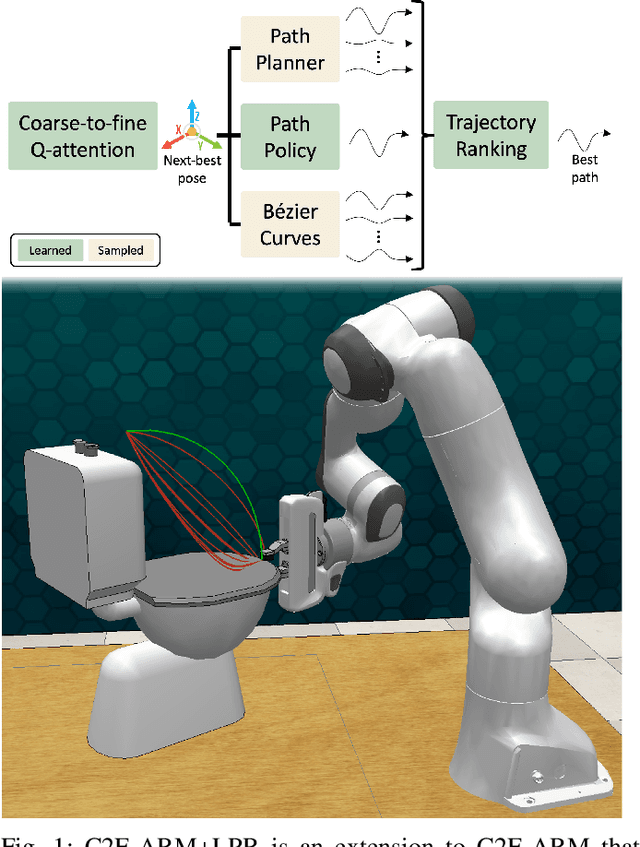

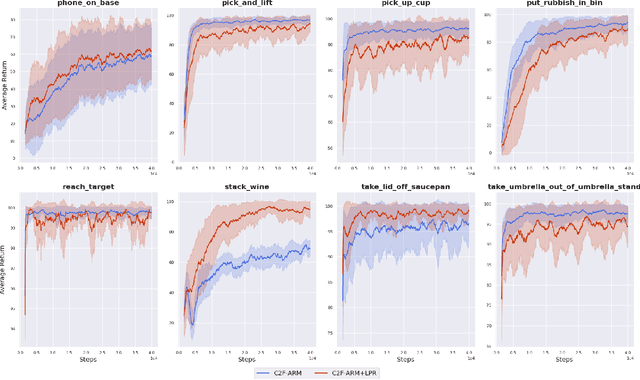
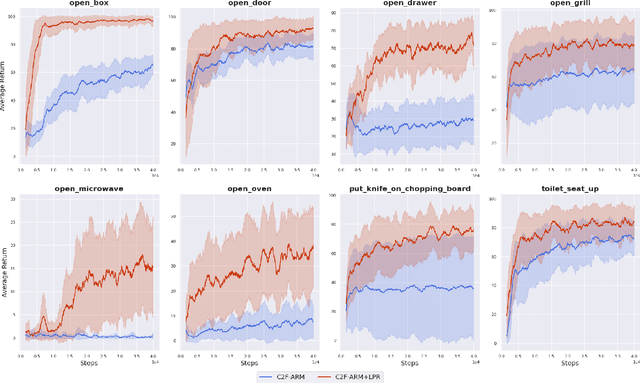
We propose Learned Path Ranking (LPR), a method that accepts an end-effector goal pose, and learns to rank a set of goal-reaching paths generated from an array of path generating methods, including: path planning, Bezier curve sampling, and a learned policy. The core idea being that each of the path generation modules will be useful in different tasks, or at different stages in a task. When LPR is added as an extension to C2F-ARM, our new system, C2F-ARM+LPR, retains the sample efficiency of its predecessor, while also being able to accomplish a larger set of tasks; in particular, tasks that require very specific motions (e.g. opening toilet seat) that need to be inferred from both demonstrations and exploration data. In addition to benchmarking our approach across 16 RLBench tasks, we also learn real-world tasks, tabula rasa, in 10-15 minutes, with only 3 demonstrations.
Pretraining Graph Neural Networks for few-shot Analog Circuit Modeling and Design
Apr 01, 2022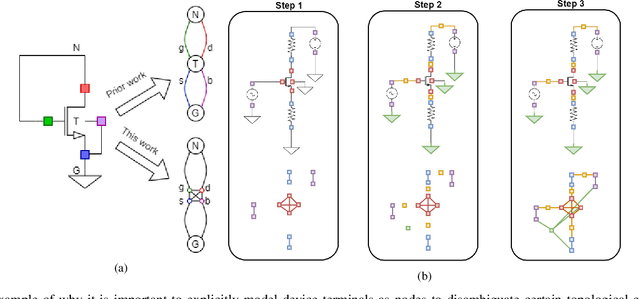
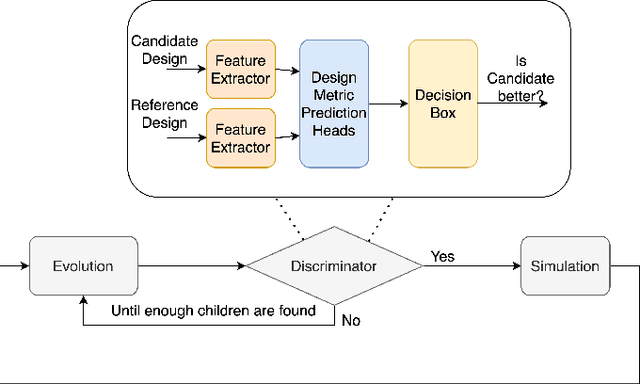
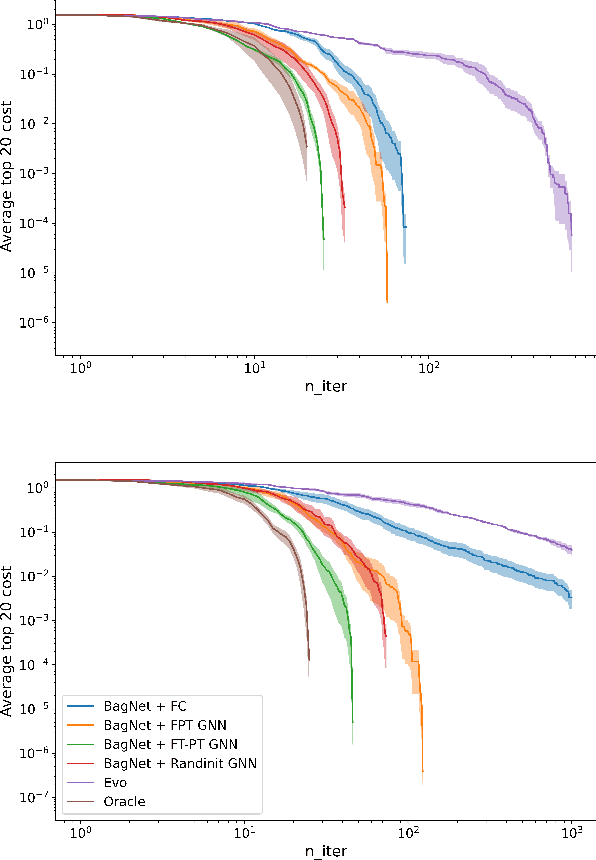

Being able to predict the performance of circuits without running expensive simulations is a desired capability that can catalyze automated design. In this paper, we present a supervised pretraining approach to learn circuit representations that can be adapted to new circuit topologies or unseen prediction tasks. We hypothesize that if we train a neural network (NN) that can predict the output DC voltages of a wide range of circuit instances it will be forced to learn generalizable knowledge about the role of each circuit element and how they interact with each other. The dataset for this supervised learning objective can be easily collected at scale since the required DC simulation to get ground truth labels is relatively cheap. This representation would then be helpful for few-shot generalization to unseen circuit metrics that require more time consuming simulations for obtaining the ground-truth labels. To cope with the variable topological structure of different circuits we describe each circuit as a graph and use graph neural networks (GNNs) to learn node embeddings. We show that pretraining GNNs on prediction of output node voltages can encourage learning representations that can be adapted to new unseen topologies or prediction of new circuit level properties with up to 10x more sample efficiency compared to a randomly initialized model. We further show that we can improve sample efficiency of prior SoTA model-based optimization methods by 2x (almost as good as using an oracle model) via fintuning pretrained GNNs as the feature extractor of the learned models.
Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions
Mar 28, 2022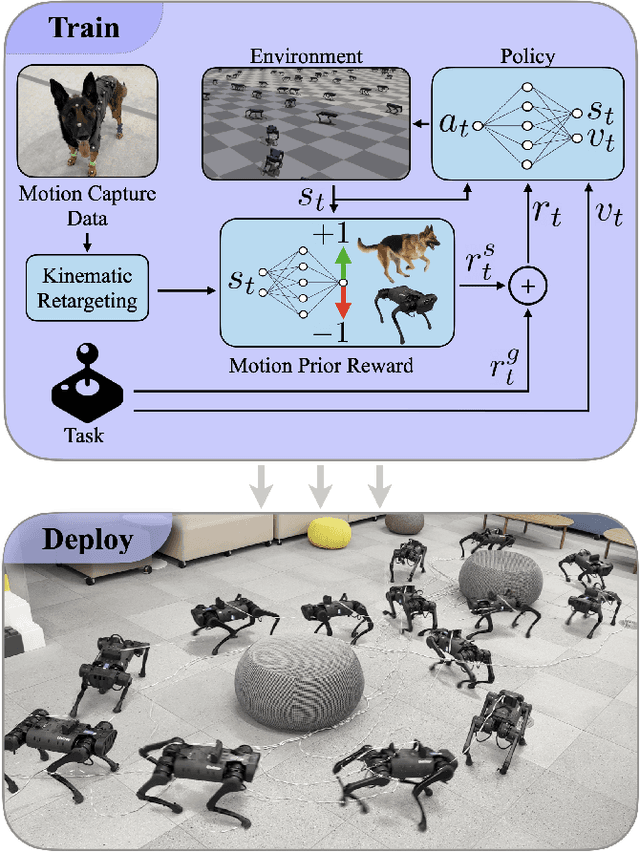
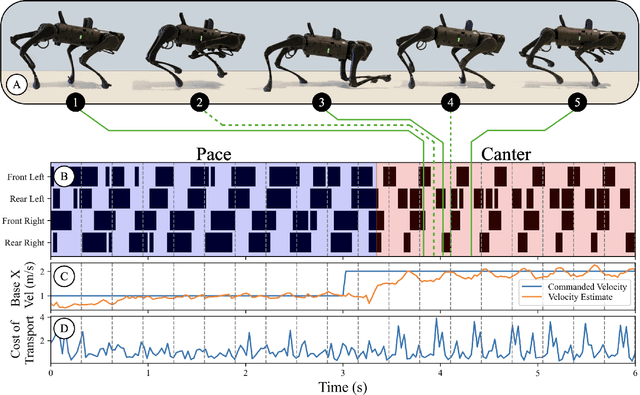


Training a high-dimensional simulated agent with an under-specified reward function often leads the agent to learn physically infeasible strategies that are ineffective when deployed in the real world. To mitigate these unnatural behaviors, reinforcement learning practitioners often utilize complex reward functions that encourage physically plausible behaviors. However, a tedious labor-intensive tuning process is often required to create hand-designed rewards which might not easily generalize across platforms and tasks. We propose substituting complex reward functions with "style rewards" learned from a dataset of motion capture demonstrations. A learned style reward can be combined with an arbitrary task reward to train policies that perform tasks using naturalistic strategies. These natural strategies can also facilitate transfer to the real world. We build upon Adversarial Motion Priors -- an approach from the computer graphics domain that encodes a style reward from a dataset of reference motions -- to demonstrate that an adversarial approach to training policies can produce behaviors that transfer to a real quadrupedal robot without requiring complex reward functions. We also demonstrate that an effective style reward can be learned from a few seconds of motion capture data gathered from a German Shepherd and leads to energy-efficient locomotion strategies with natural gait transitions.
Reinforcement Learning with Action-Free Pre-Training from Videos
Mar 25, 2022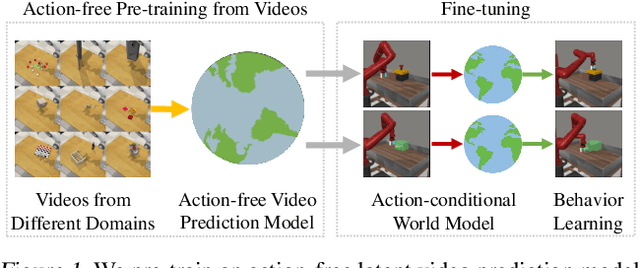
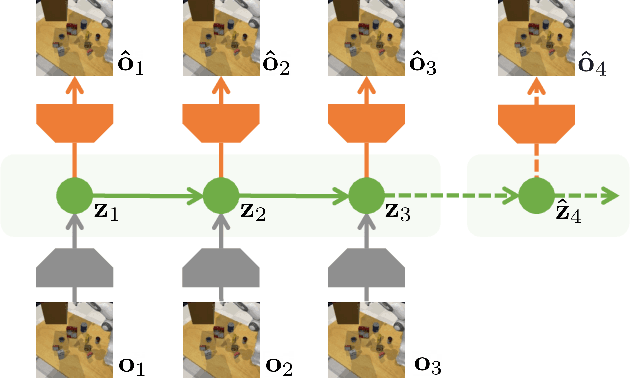
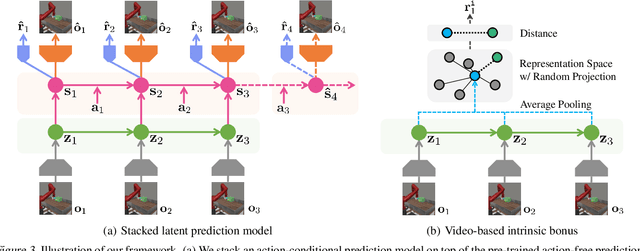
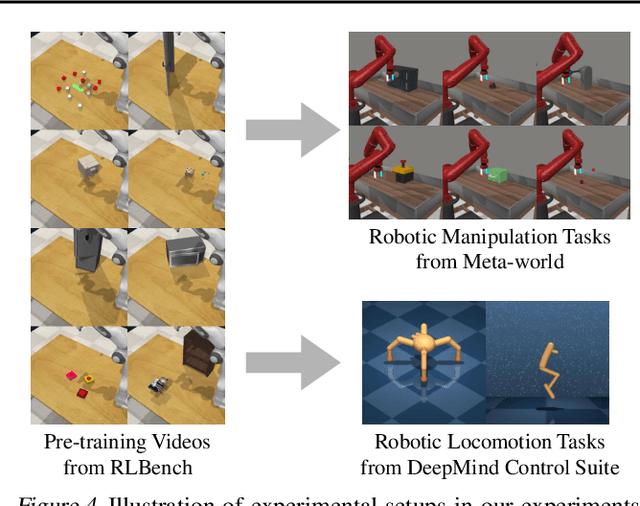
Recent unsupervised pre-training methods have shown to be effective on language and vision domains by learning useful representations for multiple downstream tasks. In this paper, we investigate if such unsupervised pre-training methods can also be effective for vision-based reinforcement learning (RL). To this end, we introduce a framework that learns representations useful for understanding the dynamics via generative pre-training on videos. Our framework consists of two phases: we pre-train an action-free latent video prediction model, and then utilize the pre-trained representations for efficiently learning action-conditional world models on unseen environments. To incorporate additional action inputs during fine-tuning, we introduce a new architecture that stacks an action-conditional latent prediction model on top of the pre-trained action-free prediction model. Moreover, for better exploration, we propose a video-based intrinsic bonus that leverages pre-trained representations. We demonstrate that our framework significantly improves both final performances and sample-efficiency of vision-based RL in a variety of manipulation and locomotion tasks. Code is available at https://github.com/younggyoseo/apv.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022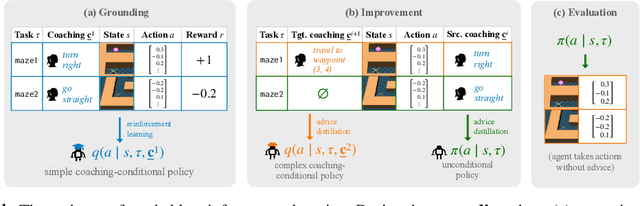
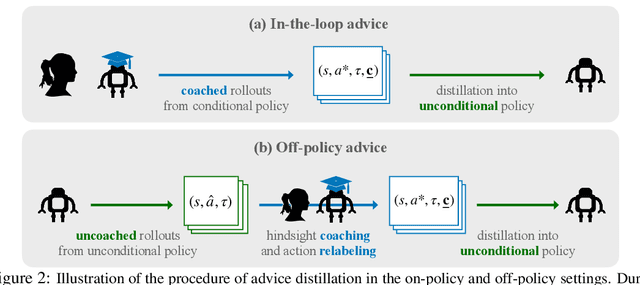
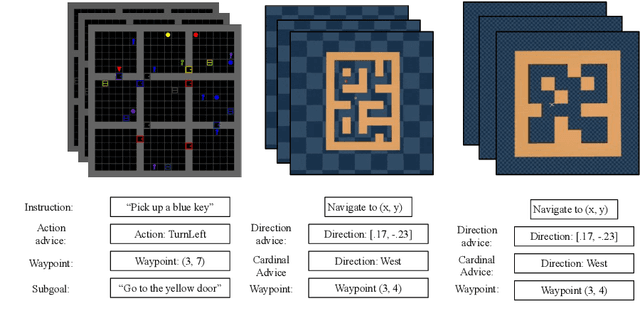
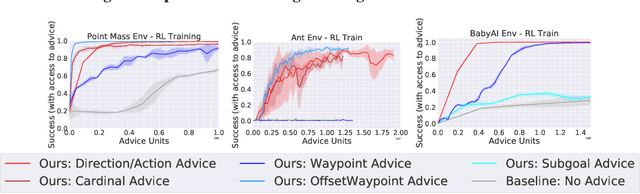
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.
SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning
Mar 18, 2022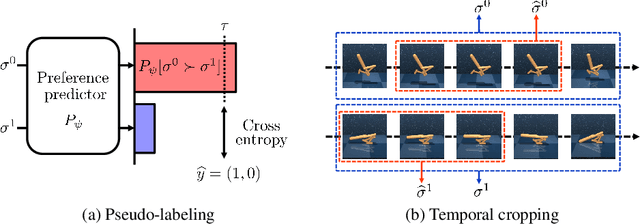

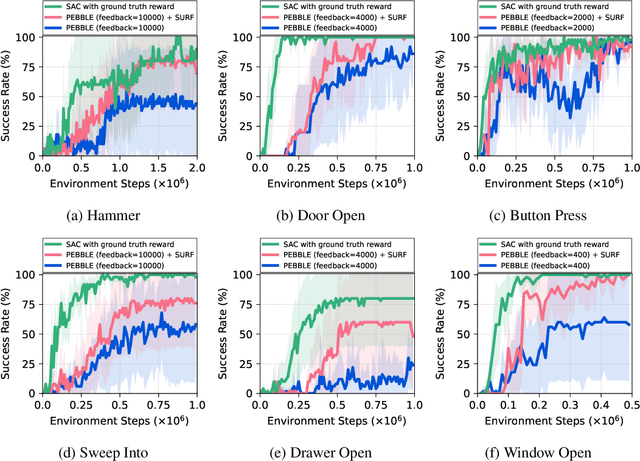

Preference-based reinforcement learning (RL) has shown potential for teaching agents to perform the target tasks without a costly, pre-defined reward function by learning the reward with a supervisor's preference between the two agent behaviors. However, preference-based learning often requires a large amount of human feedback, making it difficult to apply this approach to various applications. This data-efficiency problem, on the other hand, has been typically addressed by using unlabeled samples or data augmentation techniques in the context of supervised learning. Motivated by the recent success of these approaches, we present SURF, a semi-supervised reward learning framework that utilizes a large amount of unlabeled samples with data augmentation. In order to leverage unlabeled samples for reward learning, we infer pseudo-labels of the unlabeled samples based on the confidence of the preference predictor. To further improve the label-efficiency of reward learning, we introduce a new data augmentation that temporally crops consecutive subsequences from the original behaviors. Our experiments demonstrate that our approach significantly improves the feedback-efficiency of the state-of-the-art preference-based method on a variety of locomotion and robotic manipulation tasks.
It Takes Four to Tango: Multiagent Selfplay for Automatic Curriculum Generation
Feb 22, 2022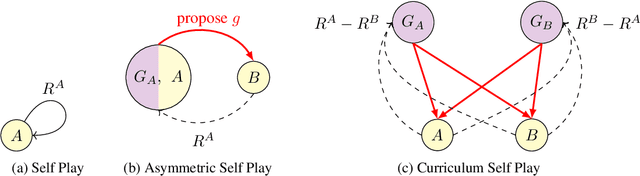
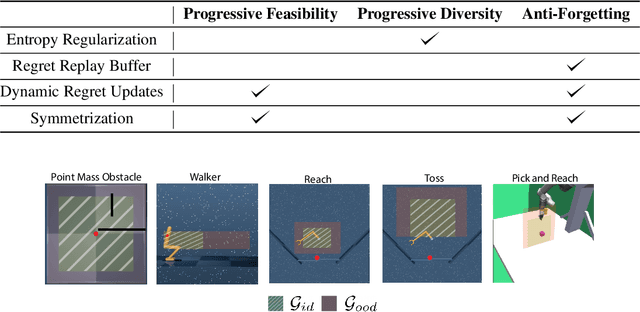
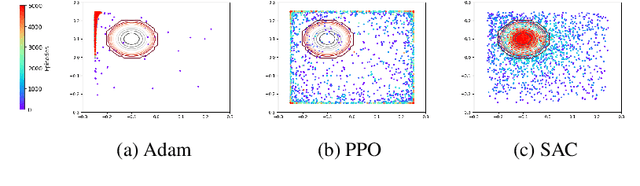

We are interested in training general-purpose reinforcement learning agents that can solve a wide variety of goals. Training such agents efficiently requires automatic generation of a goal curriculum. This is challenging as it requires (a) exploring goals of increasing difficulty, while ensuring that the agent (b) is exposed to a diverse set of goals in a sample efficient manner and (c) does not catastrophically forget previously solved goals. We propose Curriculum Self Play (CuSP), an automated goal generation framework that seeks to satisfy these desiderata by virtue of a multi-player game with four agents. We extend the asymmetric curricula learning in PAIRED (Dennis et al., 2020) to a symmetrized game that carefully balances cooperation and competition between two off-policy student learners and two regret-maximizing teachers. CuSP additionally introduces entropic goal coverage and accounts for the non-stationary nature of the students, allowing us to automatically induce a curriculum that balances progressive exploration with anti-catastrophic exploitation. We demonstrate that our method succeeds at generating an effective curricula of goals for a range of control tasks, outperforming other methods at zero-shot test-time generalization to novel out-of-distribution goals.
Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning
Feb 08, 2022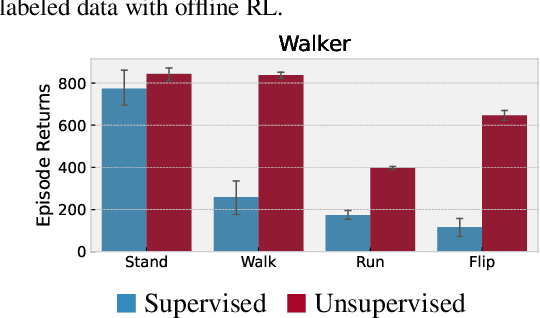
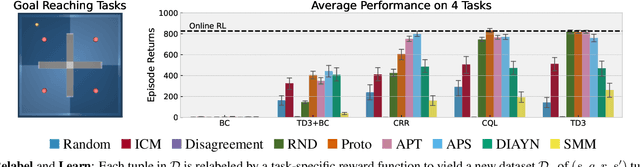
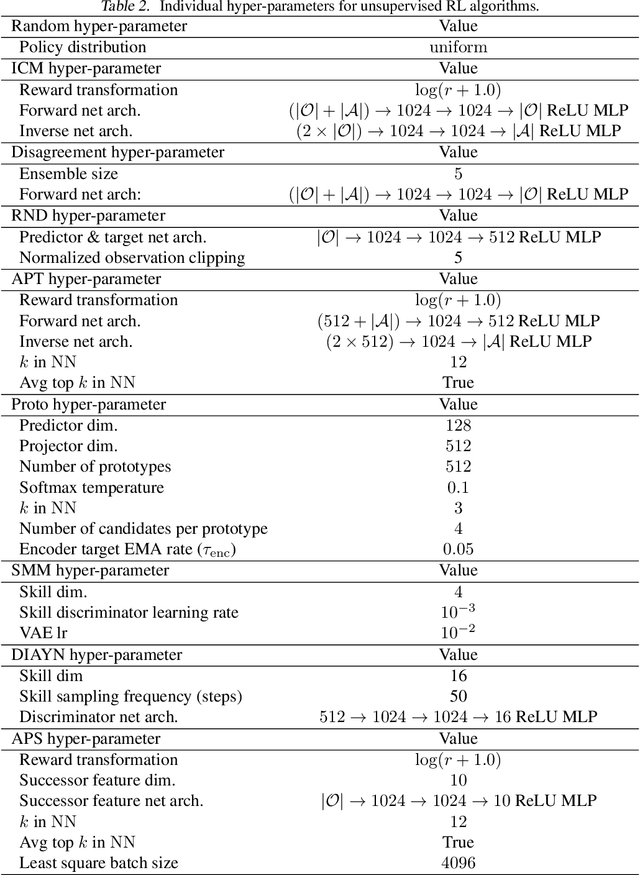
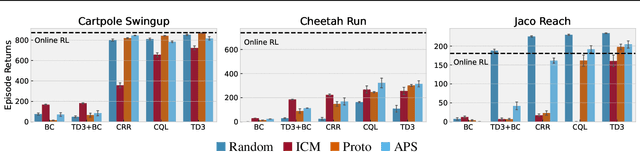
Recent progress in deep learning has relied on access to large and diverse datasets. Such data-driven progress has been less evident in offline reinforcement learning (RL), because offline RL data is usually collected to optimize specific target tasks limiting the data's diversity. In this work, we propose Exploratory data for Offline RL (ExORL), a data-centric approach to offline RL. ExORL first generates data with unsupervised reward-free exploration, then relabels this data with a downstream reward before training a policy with offline RL. We find that exploratory data allows vanilla off-policy RL algorithms, without any offline-specific modifications, to outperform or match state-of-the-art offline RL algorithms on downstream tasks. Our findings suggest that data generation is as important as algorithmic advances for offline RL and hence requires careful consideration from the community. Code and data can be found at https://github.com/denisyarats/exorl .
Bingham Policy Parameterization for 3D Rotations in Reinforcement Learning
Feb 08, 2022We propose a new policy parameterization for representing 3D rotations during reinforcement learning. Today in the continuous control reinforcement learning literature, many stochastic policy parameterizations are Gaussian. We argue that universally applying a Gaussian policy parameterization is not always desirable for all environments. One such case in particular where this is true are tasks that involve predicting a 3D rotation output, either in isolation, or coupled with translation as part of a full 6D pose output. Our proposed Bingham Policy Parameterization (BPP) models the Bingham distribution and allows for better rotation (quaternion) prediction over a Gaussian policy parameterization in a range of reinforcement learning tasks. We evaluate BPP on the rotation Wahba problem task, as well as a set of vision-based next-best pose robot manipulation tasks from RLBench. We hope that this paper encourages more research into developing other policy parameterization that are more suited for particular environments, rather than always assuming Gaussian.
CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
Feb 01, 2022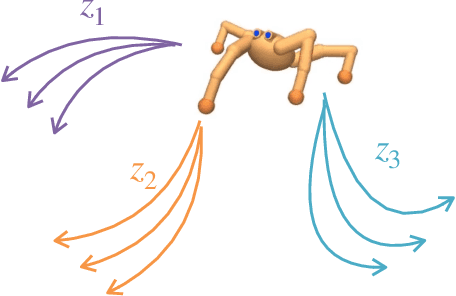
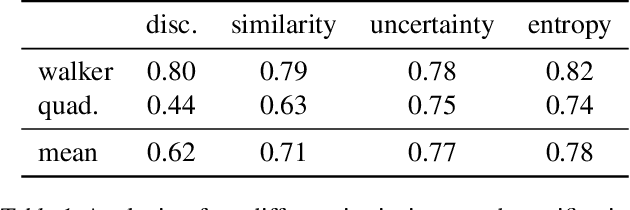
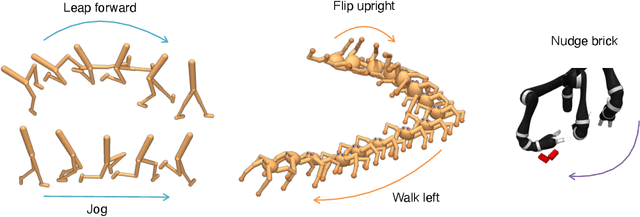

We introduce Contrastive Intrinsic Control (CIC), an algorithm for unsupervised skill discovery that maximizes the mutual information between skills and state transitions. In contrast to most prior approaches, CIC uses a decomposition of the mutual information that explicitly incentivizes diverse behaviors by maximizing state entropy. We derive a novel lower bound estimate for the mutual information which combines a particle estimator for state entropy to generate diverse behaviors and contrastive learning to distill these behaviors into distinct skills. We evaluate our algorithm on the Unsupervised Reinforcement Learning Benchmark, which consists of a long reward-free pre-training phase followed by a short adaptation phase to downstream tasks with extrinsic rewards. We find that CIC substantially improves over prior unsupervised skill discovery methods and outperforms the next leading overall exploration algorithm in terms of downstream task performance.