 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Logit Adjustment
May 05, 2022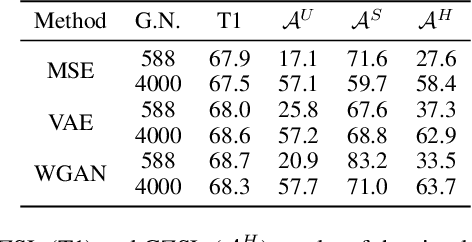
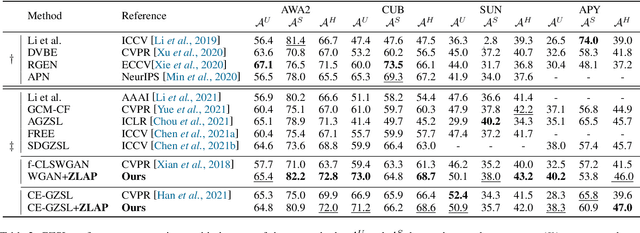
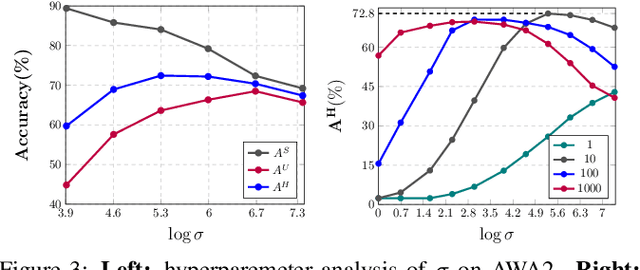
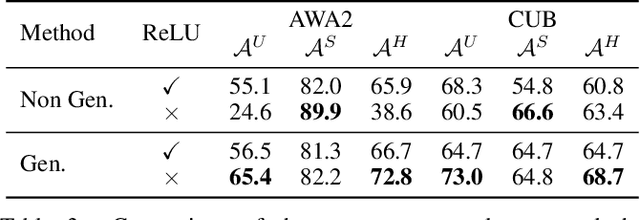
Semantic-descriptor-based Generalized Zero-Shot Learning (GZSL) poses challenges in recognizing novel classes in the test phase. The development of generative models enables current GZSL techniques to probe further into the semantic-visual link, culminating in a two-stage form that includes a generator and a classifier. However, existing generation-based methods focus on enhancing the generator's effect while neglecting the improvement of the classifier. In this paper, we first analyze of two properties of the generated pseudo unseen samples: bias and homogeneity. Then, we perform variational Bayesian inference to back-derive the evaluation metrics, which reflects the balance of the seen and unseen classes. As a consequence of our derivation, the aforementioned two properties are incorporated into the classifier training as seen-unseen priors via logit adjustment. The Zero-Shot Logit Adjustment further puts semantic-based classifiers into effect in generation-based GZSL. Our experiments demonstrate that the proposed technique achieves state-of-the-art when combined with the basic generator, and it can improve various generative Zero-Shot Learning frameworks. Our codes are available on https://github.com/cdb342/IJCAI-2022-ZLA.
Towards the Semantic Weak Generalization Problem in Generative Zero-Shot Learning: Ante-hoc and Post-hoc
Apr 24, 2022
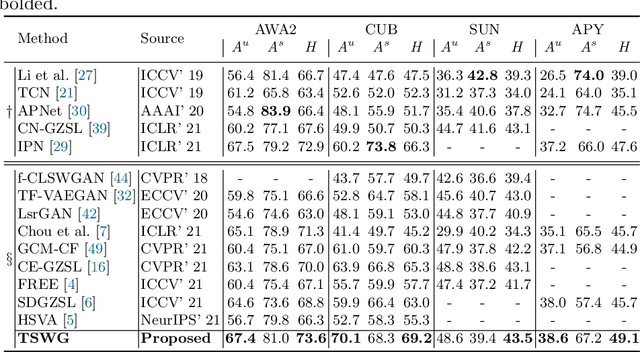
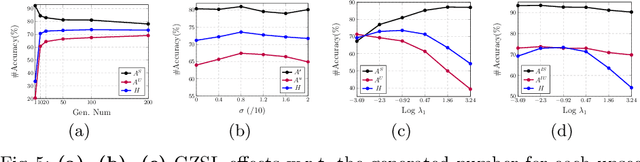
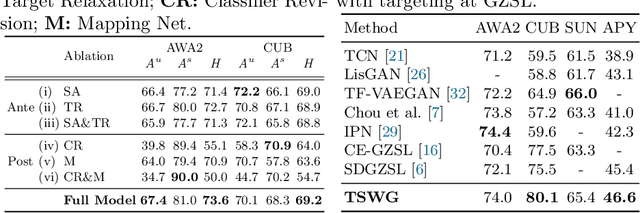
In this paper, we present a simple and effective strategy lowering the previously unexplored factors that limit the performance ceiling of generative Zero-Shot Learning (ZSL). We begin by formally defining semantic generalization, then look into approaches for reducing the semantic weak generalization problem and minimizing its negative influence on classifier training. In the ante-hoc phase, we augment the generator's semantic input, as well as relax the fitting target of the generator. In the post-hoc phase (after generating simulated unseen samples), we derive from the gradient of the loss function to minimize the gradient increment on seen classifier weights carried by biased unseen distribution, which tends to cause misleading on intra-seen class decision boundaries. Without complicated designs, our approach hit the essential problem and significantly outperform the state-of-the-art on four widely used ZSL datasets.
BNV-Fusion: Dense 3D Reconstruction using Bi-level Neural Volume Fusion
Apr 03, 2022
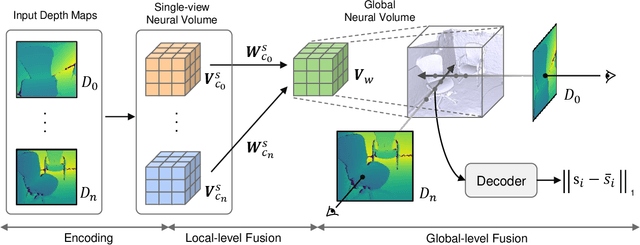

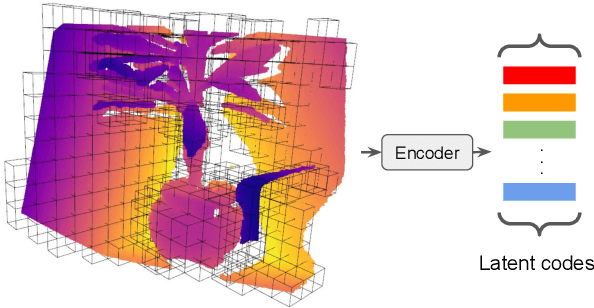
Dense 3D reconstruction from a stream of depth images is the key to many mixed reality and robotic applications. Although methods based on Truncated Signed Distance Function (TSDF) Fusion have advanced the field over the years, the TSDF volume representation is confronted with striking a balance between the robustness to noisy measurements and maintaining the level of detail. We present Bi-level Neural Volume Fusion (BNV-Fusion), which leverages recent advances in neural implicit representations and neural rendering for dense 3D reconstruction. In order to incrementally integrate new depth maps into a global neural implicit representation, we propose a novel bi-level fusion strategy that considers both efficiency and reconstruction quality by design. We evaluate the proposed method on multiple datasets quantitatively and qualitatively, demonstrating a significant improvement over existing methods.
Local and Global GANs with Semantic-Aware Upsampling for Image Generation
Feb 28, 2022
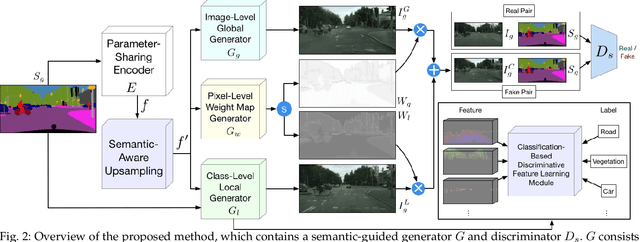
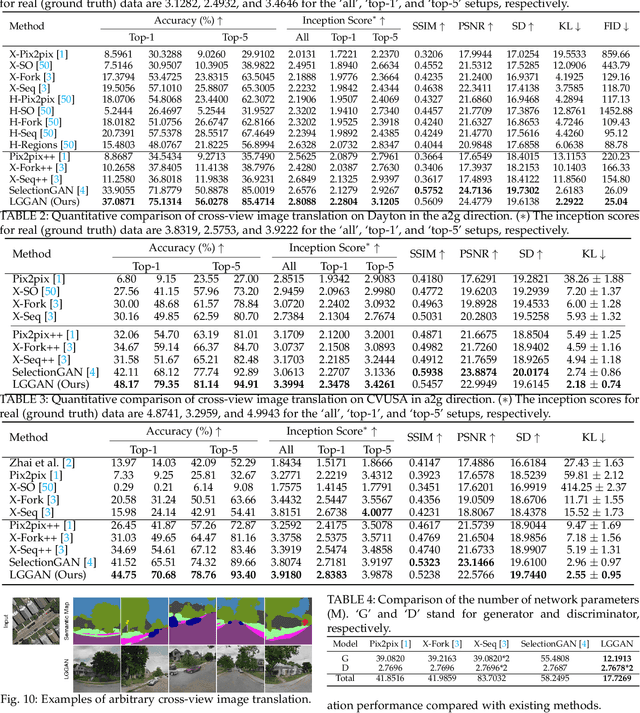
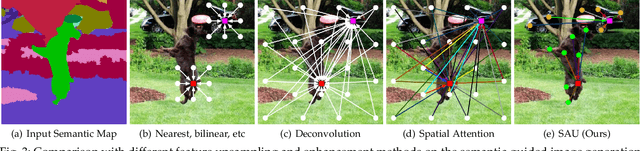
In this paper, we address the task of semantic-guided image generation. One challenge common to most existing image-level generation methods is the difficulty in generating small objects and detailed local textures. To address this, in this work we consider generating images using local context. As such, we design a local class-specific generative network using semantic maps as guidance, which separately constructs and learns subgenerators for different classes, enabling it to capture finer details. To learn more discriminative class-specific feature representations for the local generation, we also propose a novel classification module. To combine the advantages of both global image-level and local class-specific generation, a joint generation network is designed with an attention fusion module and a dual-discriminator structure embedded. Lastly, we propose a novel semantic-aware upsampling method, which has a larger receptive field and can take far-away pixels that are semantically related for feature upsampling, enabling it to better preserve semantic consistency for instances with the same semantic labels. Extensive experiments on two image generation tasks show the superior performance of the proposed method. State-of-the-art results are established by large margins on both tasks and on nine challenging public benchmarks. The source code and trained models are available at https://github.com/Ha0Tang/LGGAN.
Make Some Noise: Reliable and Efficient Single-Step Adversarial Training
Feb 02, 2022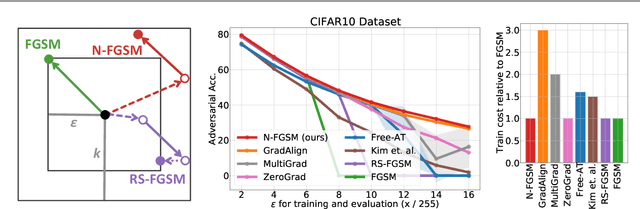
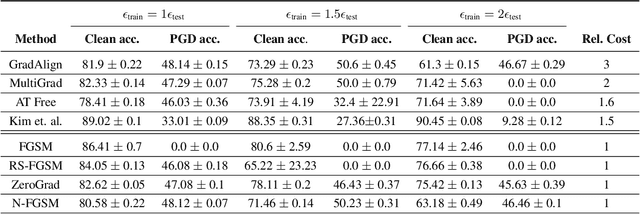
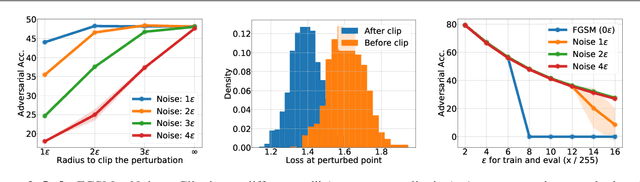
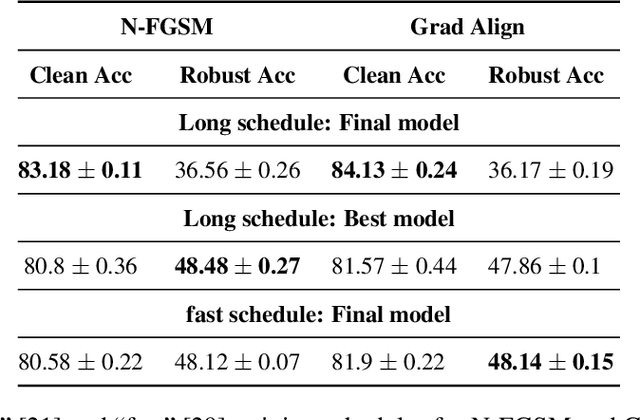
Recently, Wong et al. showed that adversarial training with single-step FGSM leads to a characteristic failure mode named catastrophic overfitting (CO), in which a model becomes suddenly vulnerable to multi-step attacks. They showed that adding a random perturbation prior to FGSM (RS-FGSM) seemed to be sufficient to prevent CO. However, Andriushchenko and Flammarion observed that RS-FGSM still leads to CO for larger perturbations, and proposed an expensive regularizer (GradAlign) to avoid CO. In this work, we methodically revisit the role of noise and clipping in single-step adversarial training. Contrary to previous intuitions, we find that using a stronger noise around the clean sample combined with not clipping is highly effective in avoiding CO for large perturbation radii. Based on these observations, we then propose Noise-FGSM (N-FGSM) that, while providing the benefits of single-step adversarial training, does not suffer from CO. Empirical analyses on a large suite of experiments show that N-FGSM is able to match or surpass the performance of previous single-step methods while achieving a 3$\times$ speed-up.
Learning to Hash Naturally Sorts
Jan 31, 2022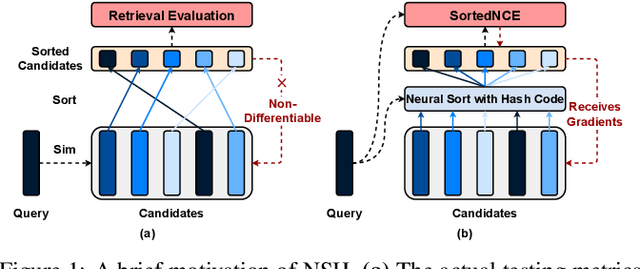
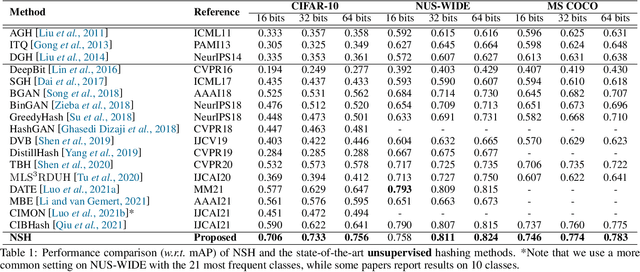
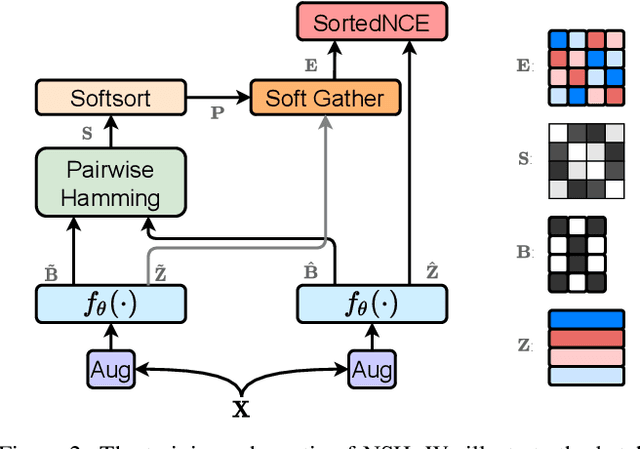
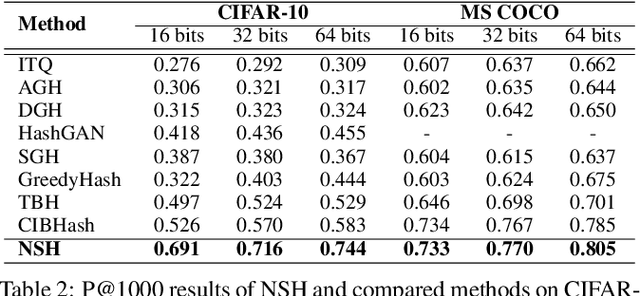
Locality sensitive hashing pictures a list-wise sorting problem. Its testing metrics, e.g., mean-average precision, count on a sorted candidate list ordered by pair-wise code similarity. However, scarcely does one train a deep hashing model with the sorted results end-to-end because of the non-differentiable nature of the sorting operation. This inconsistency in the objectives of training and test may lead to sub-optimal performance since the training loss often fails to reflect the actual retrieval metric. In this paper, we tackle this problem by introducing Naturally-Sorted Hashing (NSH). We sort the Hamming distances of samples' hash codes and accordingly gather their latent representations for self-supervised training. Thanks to the recent advances in differentiable sorting approximations, the hash head receives gradients from the sorter so that the hash encoder can be optimized along with the training procedure. Additionally, we describe a novel Sorted Noise-Contrastive Estimation (SortedNCE) loss that selectively picks positive and negative samples for contrastive learning, which allows NSH to mine data semantic relations during training in an unsupervised manner. Our extensive experiments show the proposed NSH model significantly outperforms the existing unsupervised hashing methods on three benchmarked datasets.
Adversarial Masking for Self-Supervised Learning
Jan 31, 2022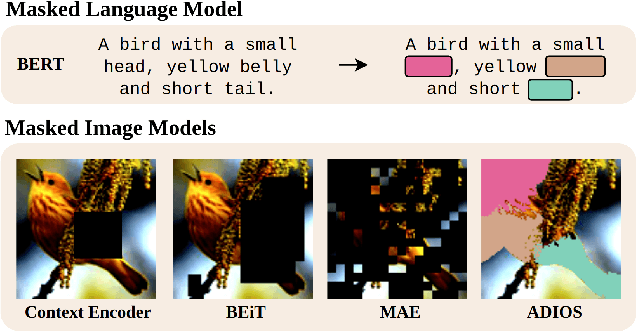
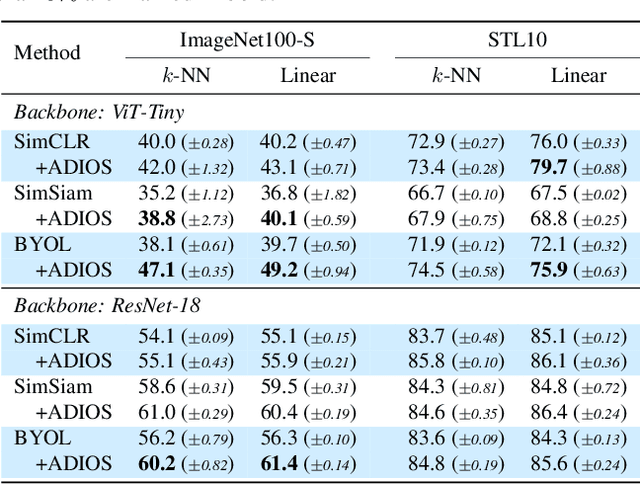

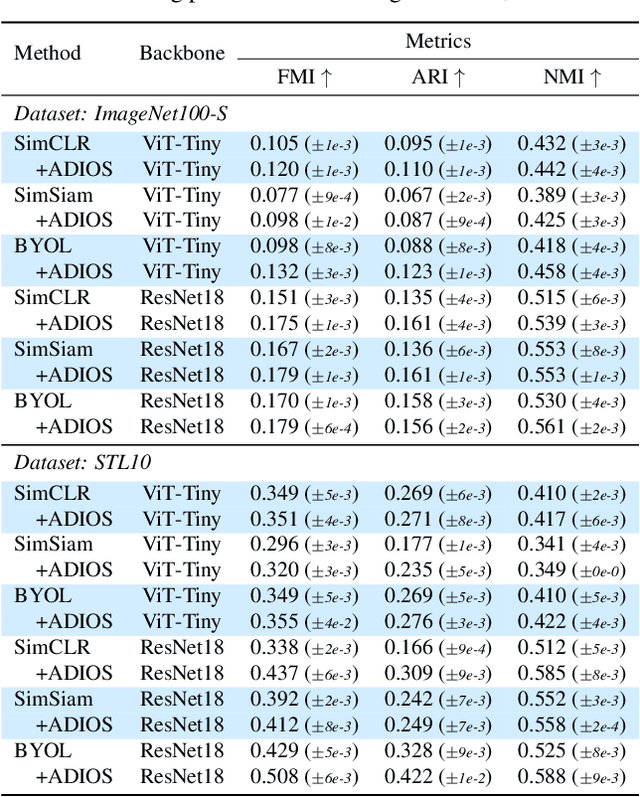
We propose ADIOS, a masked image model (MIM) framework for self-supervised learning, which simultaneously learns a masking function and an image encoder using an adversarial objective. The image encoder is trained to minimise the distance between representations of the original and that of a masked image. The masking function, conversely, aims at maximising this distance. ADIOS consistently improves on state-of-the-art self-supervised learning (SSL) methods on a variety of tasks and datasets -- including classification on ImageNet100 and STL10, transfer learning on CIFAR10/100, Flowers102 and iNaturalist, as well as robustness evaluated on the backgrounds challenge (Xiao et al., 2021) -- while generating semantically meaningful masks. Unlike modern MIM models such as MAE, BEiT and iBOT, ADIOS does not rely on the image-patch tokenisation construction of Vision Transformers, and can be implemented with convolutional backbones. We further demonstrate that the masks learned by ADIOS are more effective in improving representation learning of SSL methods than masking schemes used in popular MIM models.
On the Robustness of Quality Measures for GANs
Jan 31, 2022
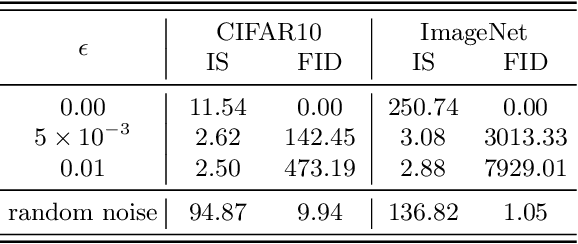


This work evaluates the robustness of quality measures of generative models such as Inception Score (IS) and Fr\'echet Inception Distance (FID). Analogous to the vulnerability of deep models against a variety of adversarial attacks, we show that such metrics can also be manipulated by additive pixel perturbations. Our experiments indicate that one can generate a distribution of images with very high scores but low perceptual quality. Conversely, one can optimize for small imperceptible perturbations that, when added to real world images, deteriorate their scores. Furthermore, we extend our evaluation to generative models themselves, including the state of the art network StyleGANv2. We show the vulnerability of both the generative model and the FID against additive perturbations in the latent space. Finally, we show that the FID can be robustified by directly replacing the Inception model by a robustly trained Inception. We validate the effectiveness of the robustified metric through extensive experiments, which show that it is more robust against manipulation.
LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
Dec 04, 2021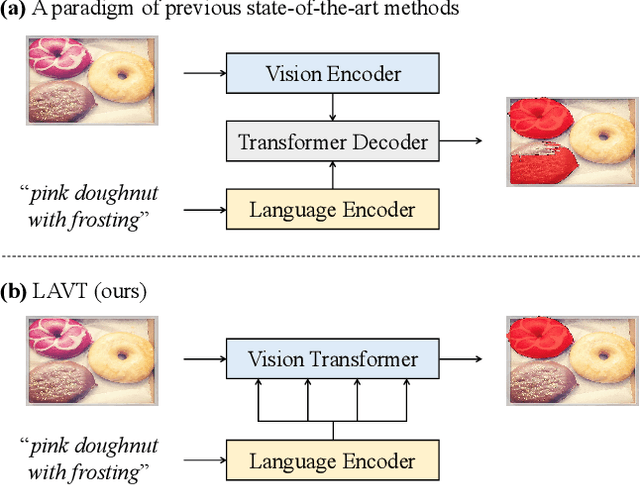
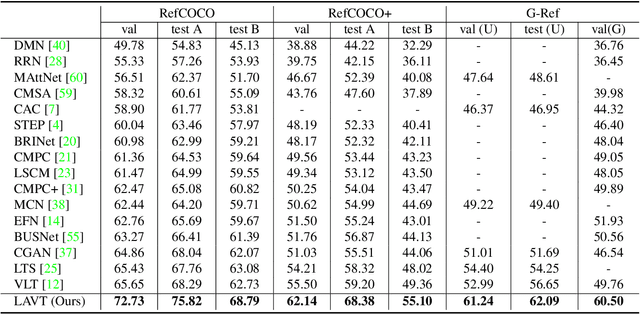
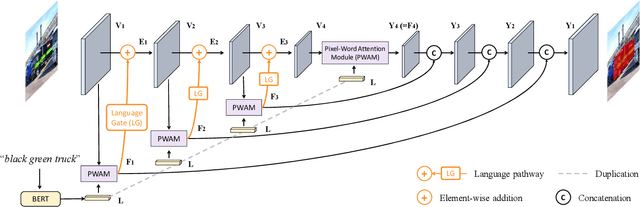
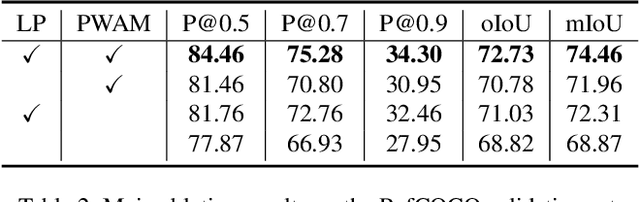
Referring image segmentation is a fundamental vision-language task that aims to segment out an object referred to by a natural language expression from an image. One of the key challenges behind this task is leveraging the referring expression for highlighting relevant positions in the image. A paradigm for tackling this problem is to leverage a powerful vision-language ("cross-modal") decoder to fuse features independently extracted from a vision encoder and a language encoder. Recent methods have made remarkable advancements in this paradigm by exploiting Transformers as cross-modal decoders, concurrent to the Transformer's overwhelming success in many other vision-language tasks. Adopting a different approach in this work, we show that significantly better cross-modal alignments can be achieved through the early fusion of linguistic and visual features in intermediate layers of a vision Transformer encoder network. By conducting cross-modal feature fusion in the visual feature encoding stage, we can leverage the well-proven correlation modeling power of a Transformer encoder for excavating helpful multi-modal context. This way, accurate segmentation results are readily harvested with a light-weight mask predictor. Without bells and whistles, our method surpasses the previous state-of-the-art methods on RefCOCO, RefCOCO+, and G-Ref by large margins.
Fixed Points in Cyber Space: Rethinking Optimal Evasion Attacks in the Age of AI-NIDS
Nov 23, 2021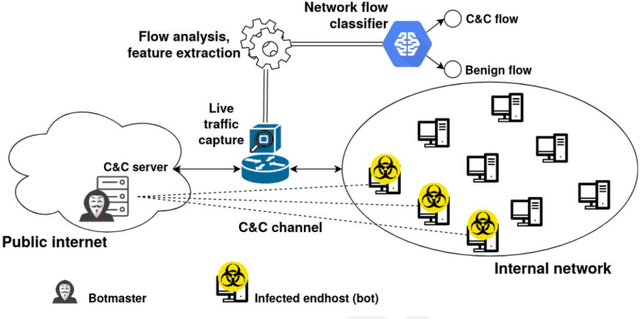
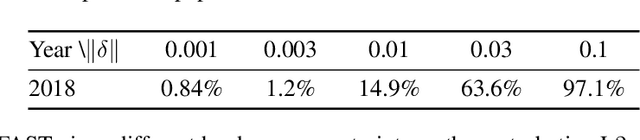
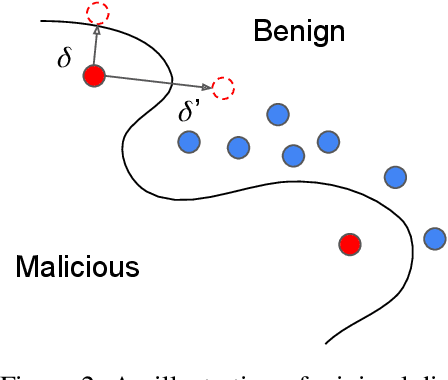
Cyber attacks are increasing in volume, frequency, and complexity. In response, the security community is looking toward fully automating cyber defense systems using machine learning. However, so far the resultant effects on the coevolutionary dynamics of attackers and defenders have not been examined. In this whitepaper, we hypothesise that increased automation on both sides will accelerate the coevolutionary cycle, thus begging the question of whether there are any resultant fixed points, and how they are characterised. Working within the threat model of Locked Shields, Europe's largest cyberdefense exercise, we study blackbox adversarial attacks on network classifiers. Given already existing attack capabilities, we question the utility of optimal evasion attack frameworks based on minimal evasion distances. Instead, we suggest a novel reinforcement learning setting that can be used to efficiently generate arbitrary adversarial perturbations. We then argue that attacker-defender fixed points are themselves general-sum games with complex phase transitions, and introduce a temporally extended multi-agent reinforcement learning framework in which the resultant dynamics can be studied. We hypothesise that one plausible fixed point of AI-NIDS may be a scenario where the defense strategy relies heavily on whitelisted feature flow subspaces. Finally, we demonstrate that a continual learning approach is required to study attacker-defender dynamics in temporally extended general-sum games.