 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Elicitation of Language Models
Jun 11, 2025



To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, \emph{without external supervision}. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Distillation Robustifies Unlearning
Jun 06, 2025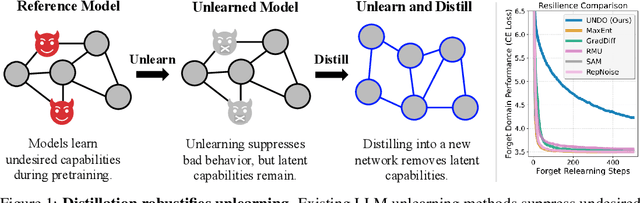

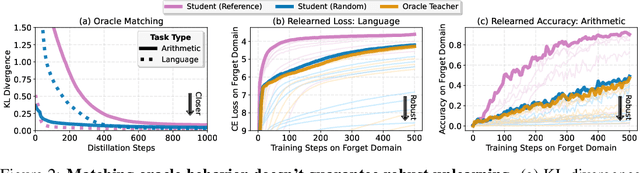
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.
Gradient Routing: Masking Gradients to Localize Computation in Neural Networks
Oct 06, 2024



Neural networks are trained primarily based on their inputs and outputs, without regard for their internal mechanisms. These neglected mechanisms determine properties that are critical for safety, like (i) transparency; (ii) the absence of sensitive information or harmful capabilities; and (iii) reliable generalization of goals beyond the training distribution. To address this shortcoming, we introduce gradient routing, a training method that isolates capabilities to specific subregions of a neural network. Gradient routing applies data-dependent, weighted masks to gradients during backpropagation. These masks are supplied by the user in order to configure which parameters are updated by which data points. We show that gradient routing can be used to (1) learn representations which are partitioned in an interpretable way; (2) enable robust unlearning via ablation of a pre-specified network subregion; and (3) achieve scalable oversight of a reinforcement learner by localizing modules responsible for different behaviors. Throughout, we find that gradient routing localizes capabilities even when applied to a limited, ad-hoc subset of the data. We conclude that the approach holds promise for challenging, real-world applications where quality data are scarce.
Speeding up and reducing memory usage for scientific machine learning via mixed precision
Jan 30, 2024



Scientific machine learning (SciML) has emerged as a versatile approach to address complex computational science and engineering problems. Within this field, physics-informed neural networks (PINNs) and deep operator networks (DeepONets) stand out as the leading techniques for solving partial differential equations by incorporating both physical equations and experimental data. However, training PINNs and DeepONets requires significant computational resources, including long computational times and large amounts of memory. In search of computational efficiency, training neural networks using half precision (float16) rather than the conventional single (float32) or double (float64) precision has gained substantial interest, given the inherent benefits of reduced computational time and memory consumed. However, we find that float16 cannot be applied to SciML methods, because of gradient divergence at the start of training, weight updates going to zero, and the inability to converge to a local minima. To overcome these limitations, we explore mixed precision, which is an approach that combines the float16 and float32 numerical formats to reduce memory usage and increase computational speed. Our experiments showcase that mixed precision training not only substantially decreases training times and memory demands but also maintains model accuracy. We also reinforce our empirical observations with a theoretical analysis. The research has broad implications for SciML in various computational applications.